 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting adverse outcomes following catheter ablation treatment for atrial fibrillation
Nov 22, 2022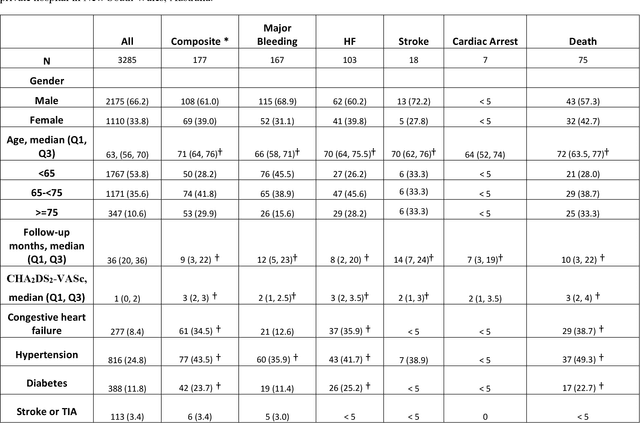
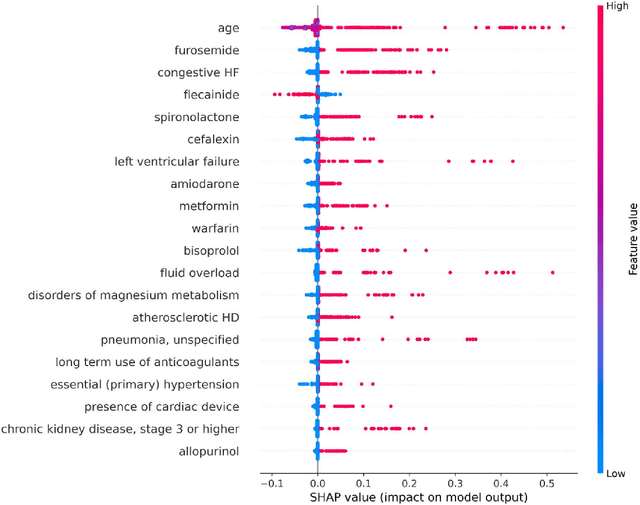
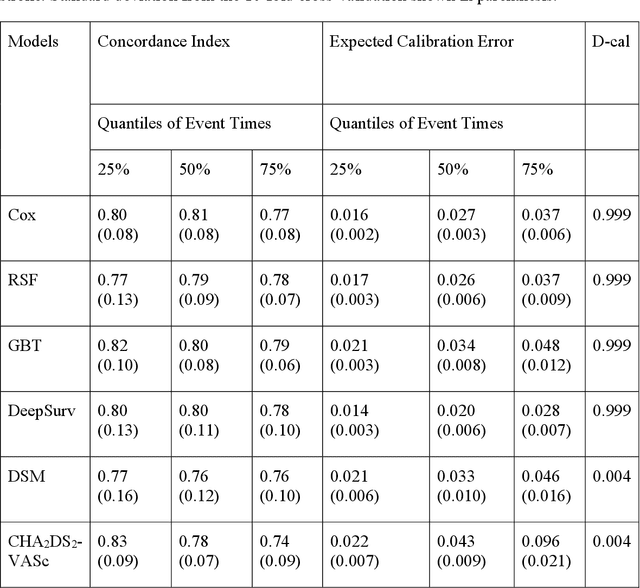
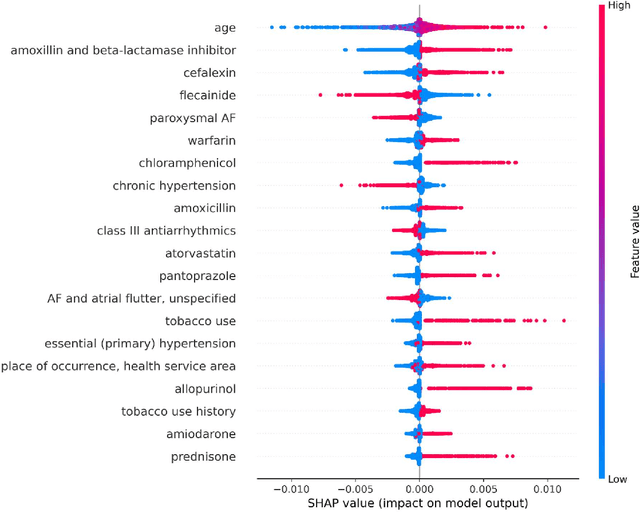
Objective: To develop prognostic survival models for predicting adverse outcomes after catheter ablation treatment for non-valvular atrial fibrillation (AF). Methods: We used a linked dataset including hospital administrative data, prescription medicine claims, emergency department presentations, and death registrations of patients in New South Wales, Australia. The cohort included patients who received catheter ablation for AF. Traditional and deep survival models were trained to predict major bleeding events and a composite of heart failure, stroke, cardiac arrest, and death. Results: Out of a total of 3285 patients in the cohort, 177 (5.3%) experienced the composite outcomeheart failure, stroke, cardiac arrest, deathand 167 (5.1%) experienced major bleeding events after catheter ablation treatment. Models predicting the composite outcome had high risk discrimination accuracy, with the best model having a concordance index > 0.79 at the evaluated time horizons. Models for predicting major bleeding events had poor risk discrimination performance, with all models having a concordance index < 0.66. The most impactful features for the models predicting higher risk were comorbidities indicative of poor health, older age, and therapies commonly used in sicker patients to treat heart failure and AF. Conclusions: Diagnosis and medication history did not contain sufficient information for precise risk prediction of experiencing major bleeding events. The models for predicting the composite outcome have the potential to enable clinicians to identify and manage high-risk patients following catheter ablation proactively. Future research is needed to validate the usefulness of these models in clinical practice.
Automatic Speech Summarisation: A Scoping Review
Aug 27, 2020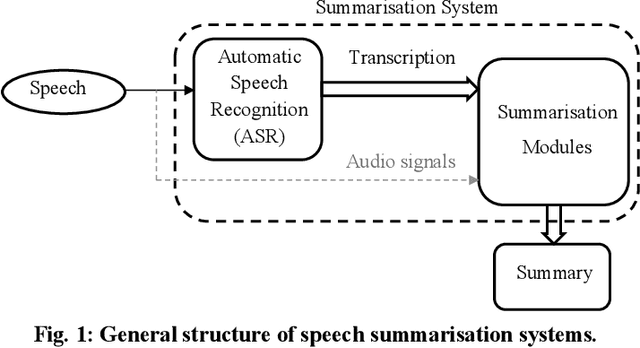
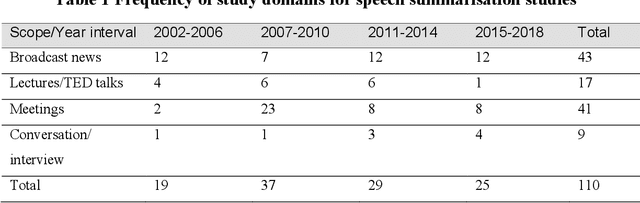
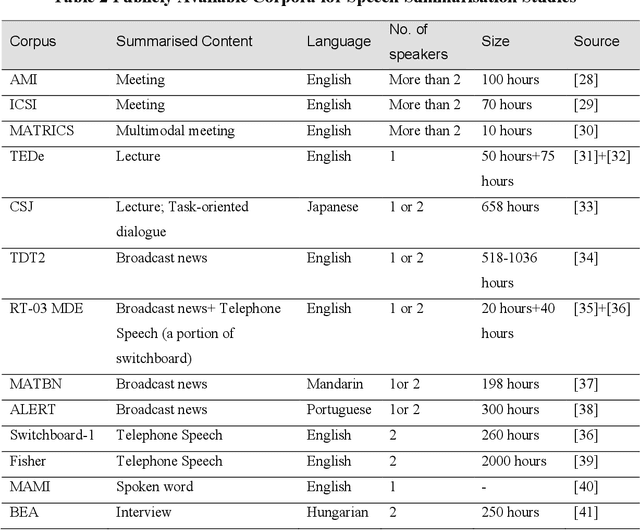
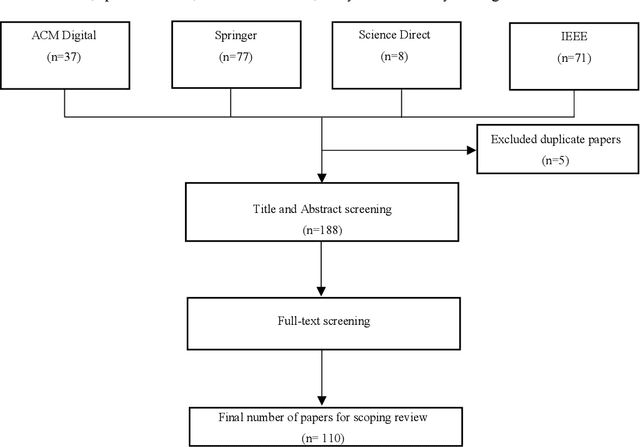
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
Collaborative Evolution of 3D Models
Nov 27, 2017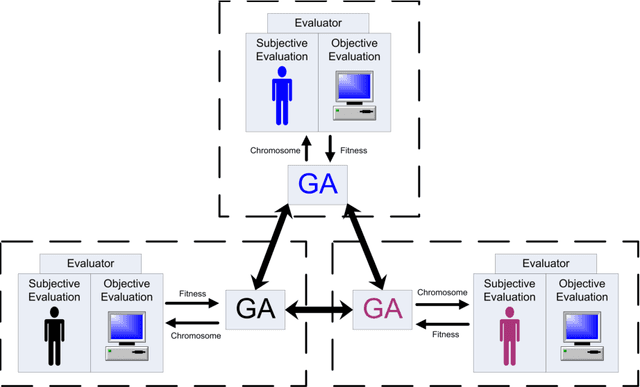
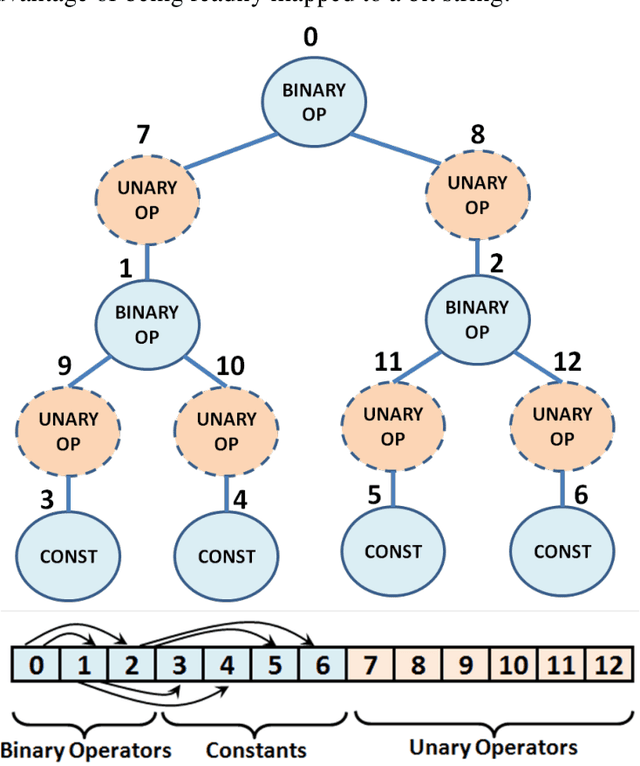
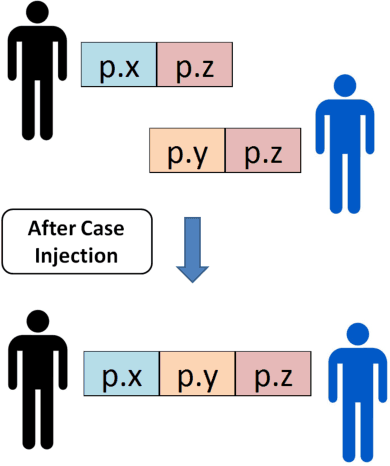
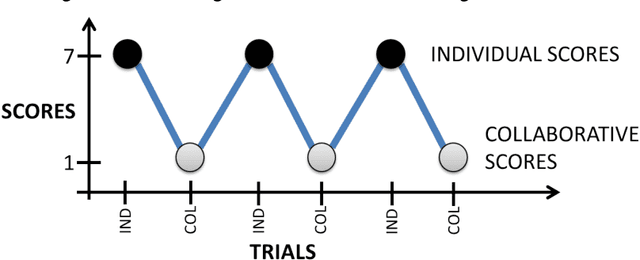
We present a computational model of creative design based on collaborative interactive genetic algorithms. In our model, designers individually guide interactive genetic algorithms (IGAs) to generate and explore potential design solutions quickly. Collaboration is supported by allowing designers to share solutions amongst each other while using IGAs, with the sharing of solutions adding variables to the search space. We present experiments on 3D modeling as a case study, with designers creating model transformations individually and collaboratively. The transformations were evaluated by participants in surveys and results show that individual and collaborative models were considered equally creative. However, the use of our collaborative IGAs model materially changes resulting designs compared to individual IGAs.
* Design Computing and Cognition 2014
Fault Detection of Broken Rotor Bar in LS-PMSM Using Random Forests
Nov 03, 2017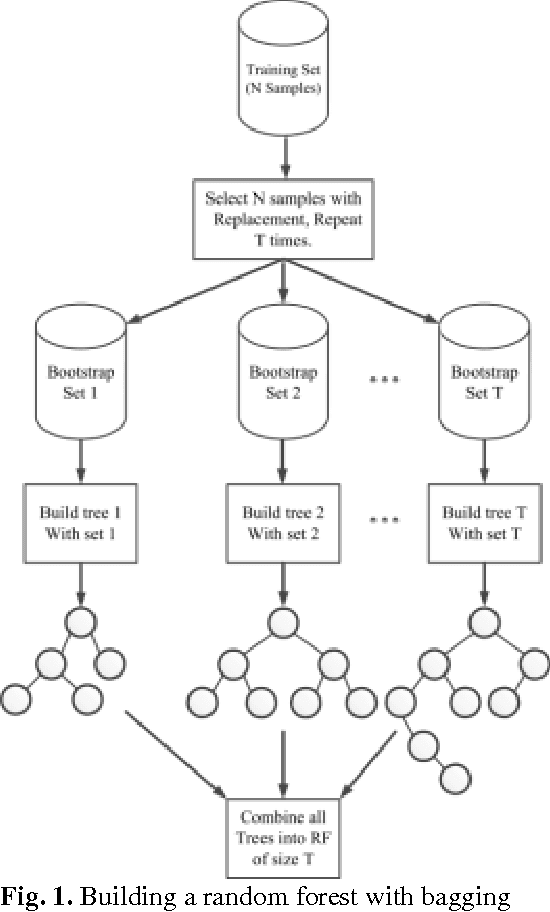
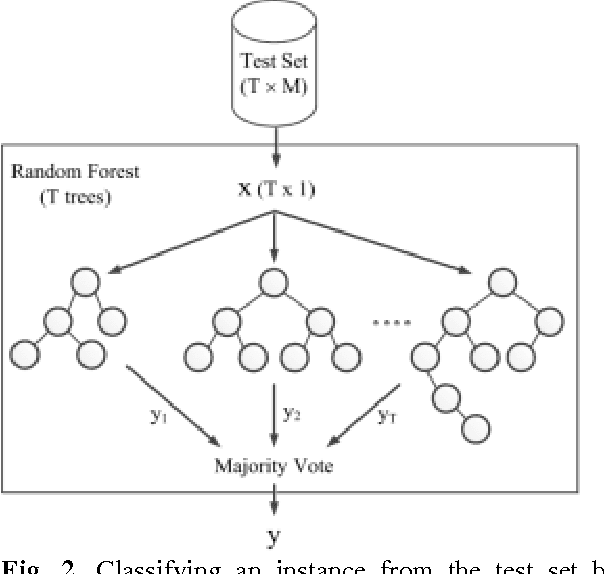
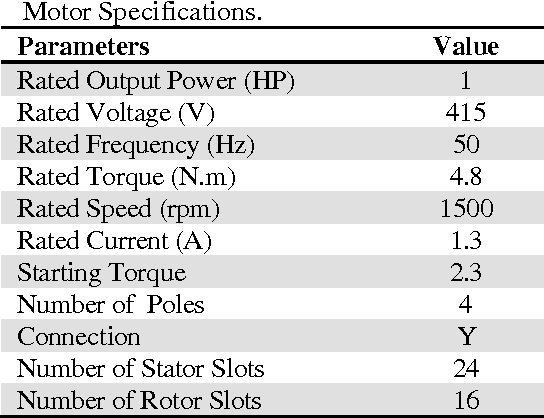
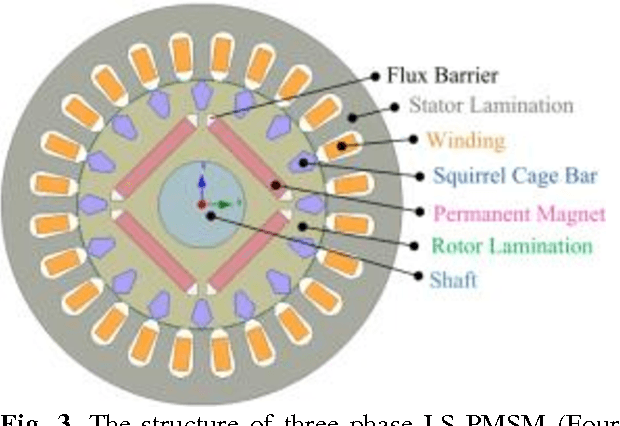
This paper proposes a new approach to diagnose broken rotor bar failure in a line start-permanent magnet synchronous motor (LS-PMSM) using random forests. The transient current signal during the motor startup was acquired from a healthy motor and a faulty motor with a broken rotor bar fault. We extracted 13 statistical time domain features from the startup transient current signal, and used these features to train and test a random forest to determine whether the motor was operating under normal or faulty conditions. For feature selection, we used the feature importances from the random forest to reduce the number of features to two features. The results showed that the random forest classifies the motor condition as healthy or faulty with an accuracy of 98.8% using all features and with an accuracy of 98.4% by using only the mean-index and impulsion features. The performance of the random forest was compared with a decision tree, Na\"ive Bayes classifier, logistic regression, linear ridge, and a support vector machine, with the random forest consistently having a higher accuracy than the other algorithms. The proposed approach can be used in industry for online monitoring and fault diagnostic of LS-PMSM motors and the results can be helpful for the establishment of preventive maintenance plans in factories.