 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"She was useful, but a bit too optimistic": Augmenting Design with Interactive Virtual Personas
Aug 26, 2025


Personas have been widely used to understand and communicate user needs in human-centred design. Despite their utility, they may fail to meet the demands of iterative workflows due to their static nature, limited engagement, and inability to adapt to evolving design needs. Recent advances in large language models (LLMs) pave the way for more engaging and adaptive approaches to user representation. This paper introduces Interactive Virtual Personas (IVPs): multimodal, LLM-driven, conversational user simulations that designers can interview, brainstorm with, and gather feedback from in real time via voice interface. We conducted a qualitative study with eight professional UX designers, employing an IVP named "Alice" across three design activities: user research, ideation, and prototype evaluation. Our findings demonstrate the potential of IVPs to expedite information gathering, inspire design solutions, and provide rapid user-like feedback. However, designers raised concerns about biases, over-optimism, the challenge of ensuring authenticity without real stakeholder input, and the inability of the IVP to fully replicate the nuances of human interaction. Our participants emphasised that IVPs should be viewed as a complement to, not a replacement for, real user engagement. We discuss strategies for prompt engineering, human-in-the-loop integration, and ethical considerations for effective and responsible IVP use in design. Finally, our work contributes to the growing body of research on generative AI in the design process by providing insights into UX designers' experiences of LLM-powered interactive personas.
Conversational AI-Powered Design: ChatGPT as Designer, User, and Product
Feb 15, 2023The recent advancements in Large Language Models (LLMs), particularly conversational LLMs like ChatGPT, have prompted changes in a range of fields, including design. This study aims to examine the capabilities of ChatGPT in a human-centered design process. To this end, a hypothetical design project was conducted, where ChatGPT was utilized to generate personas, simulate interviews with fictional users, create new design ideas, simulate usage scenarios and conversations between an imaginary prototype and fictional users, and lastly evaluate user experience. The results show that ChatGPT effectively performed the tasks assigned to it as a designer, user, or product, providing mostly appropriate responses. The study does, however, highlight some drawbacks such as forgotten information, partial responses, and a lack of output diversity. The paper explains the potential benefits and limitations of using conversational LLMs in design, discusses its implications, and suggests directions for future research in this rapidly evolving area.
Automatic Speech Summarisation: A Scoping Review
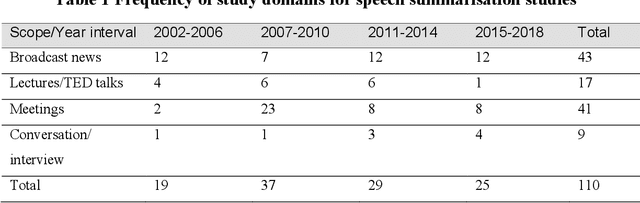
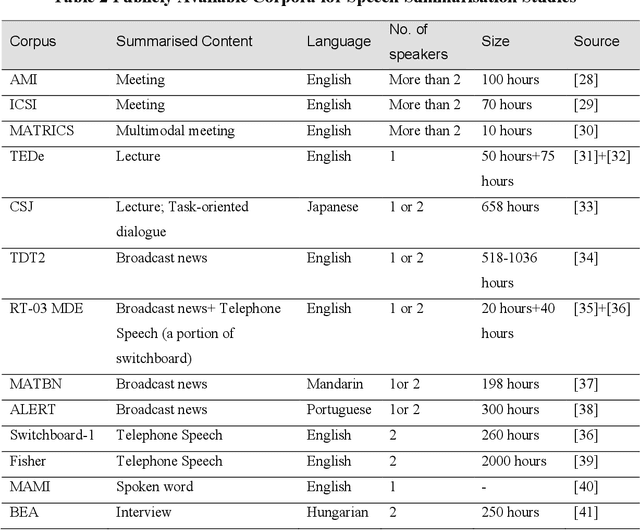
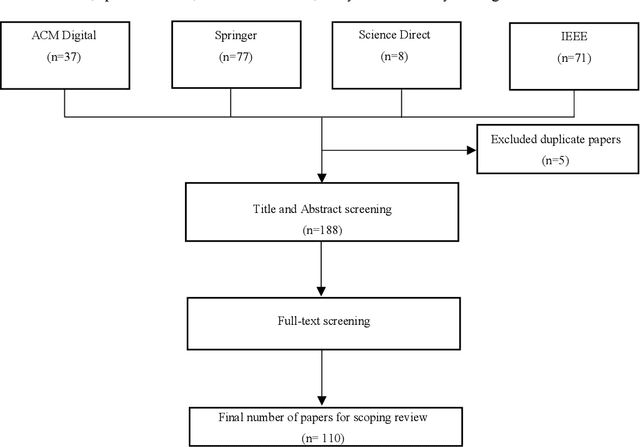
Aug 27, 2020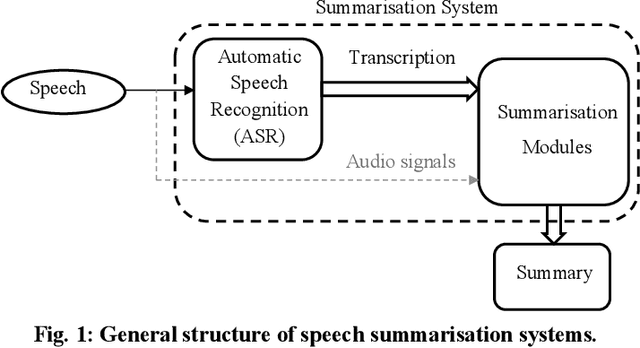
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.