 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hazard Functions to Language Space: Cox-Supervised Distillation of Survival Risk into a Large Language Model
Jun 08, 2026We investigate whether information about time-to-event risk estimated by a Cox proportional hazards model can be transferred into a generative large language model. We propose a text-based survival modelling pipeline in which structured clinical covariates are converted into text prompts and a Qwen-based large language model is fine-tuned to generate patient-specific survival risk using Cox model predictions as a training target. Across GBSG2, ACTG320, and WHAS500, the model achieves competitive held-out discrimination and calibration despite being trained as a text-generation task rather than with a conventional survival-analysis loss. We further analyse the geometry of the model's hidden states, where t-SNE visualisations reveal smooth risk gradients in latent space, suggesting that the model represents survival risk as a continuous structure rather than isolated risk categories. Together, these findings suggest that large language models can internalise survival-risk structure while supporting calibrated prediction, providing a route towards time-to-event reasoning in language models.
Synthetic but Not Realistic: The Evaluation Challenge in Generative Modelling for Structured Electronic Medical Records
Jun 08, 2026Synthetic healthcare data are widely proposed as privacy-preserving substitutes for real patient data, yet their evaluation remains dominated by statistical similarity and predictive performance that do not reflect clinical validity. We introduce a multi-dimensional evaluation framework grounded in epidemiology, assessing descriptive fidelity, clinical utility, and structural validity, corresponding to descriptive, predictive, and causal questions. We evaluate four representative generative paradigms - GAN-based, VAE-boosted, diffusion-based, and masked modelling - using PRIME-CVD, a 50,000-person cohort with known ground-truth structure. While all models reproduce marginal distributions, none simultaneously preserve subgroup structure, effect estimates, and dependency structure. Notably, models with strong distributional fidelity can exhibit poor calibration and distorted relationships, leading to unreliable inference. These results show that current evaluation practices can overestimate synthetic data quality and motivate domain-informed assessment based on the ability to support valid clinical and scientific conclusions.
Limits of Generative Pre-Training in Structured EMR Trajectories with Irregular Sampling
Oct 27, 2025Foundation models refer to architectures trained on vast datasets using autoregressive pre-training from natural language processing to capture intricate patterns and motifs. They were originally developed to transfer such learned knowledge to downstream predictive tasks. Recently, however, some studies repurpose these learned representations for phenotype discovery without rigorous validation, risking superficially realistic but clinically incoherent embeddings. To test this mismatch, we trained two autoregressive models -- a sequence-to-sequence LSTM and a reduced Transformer -- on longitudinal ART for HIV and Acute Hypotension datasets. Controlled irregularity was added during training via random inter-visit gaps, while test sequences stayed complete. Patient-trajectory synthesis evaluated distributional and correlational fidelity. Both reproduced feature distributions but failed to preserve cross-feature structure -- showing that generative pre-training yields local realism but limited clinical coherence. These results highlight the need for domain-specific evaluation and support trajectory synthesis as a practical probe before fine-tuning or deployment.
Attention-Based Synthetic Data Generation for Calibration-Enhanced Survival Analysis: A Case Study for Chronic Kidney Disease Using Electronic Health Records
Mar 08, 2025Access to real-world healthcare data is limited by stringent privacy regulations and data imbalances, hindering advancements in research and clinical applications. Synthetic data presents a promising solution, yet existing methods often fail to ensure the realism, utility, and calibration essential for robust survival analysis. Here, we introduce Masked Clinical Modelling (MCM), an attention-based framework capable of generating high-fidelity synthetic datasets that preserve critical clinical insights, such as hazard ratios, while enhancing survival model calibration. Unlike traditional statistical methods like SMOTE and machine learning models such as VAEs, MCM supports both standalone dataset synthesis for reproducibility and conditional simulation for targeted augmentation, addressing diverse research needs. Validated on a chronic kidney disease electronic health records dataset, MCM reduced the general calibration loss over the entire dataset by 15%; and MCM reduced a mean calibration loss by 9% across 10 clinically stratified subgroups, outperforming 15 alternative methods. By bridging data accessibility with translational utility, MCM advances the precision of healthcare models, promoting more efficient use of scarce healthcare resources.
Masked Clinical Modelling: A Framework for Synthetic and Augmented Survival Data Generation
Oct 23, 2024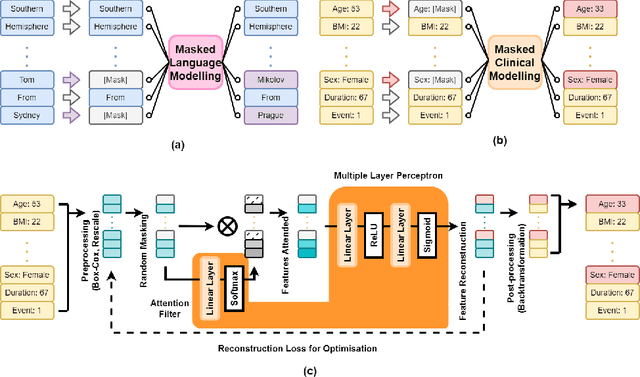
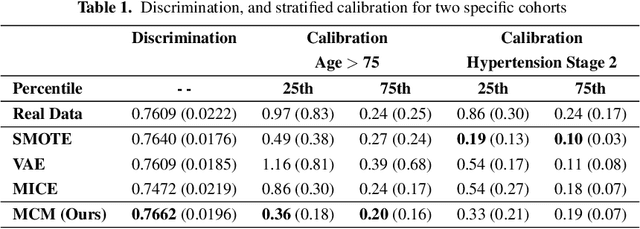
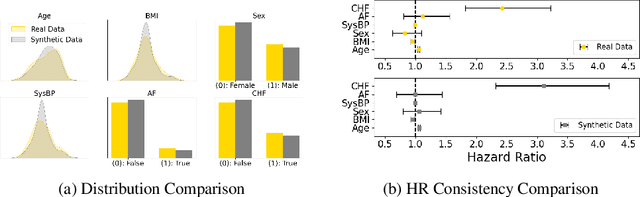
Access to real clinical data is often restricted due to privacy obligations, creating significant barriers for healthcare research. Synthetic datasets provide a promising solution, enabling secure data sharing and model development. However, most existing approaches focus on data realism rather than utility -- ensuring that models trained on synthetic data yield clinically meaningful insights comparable to those trained on real data. In this paper, we present Masked Clinical Modelling (MCM), a framework inspired by masked language modelling, designed for both data synthesis and conditional data augmentation. We evaluate this prototype on the WHAS500 dataset using Cox Proportional Hazards models, focusing on the preservation of hazard ratios as key clinical metrics. Our results show that data generated using the MCM framework improves both discrimination and calibration in survival analysis, outperforming existing methods. MCM demonstrates strong potential to support survival data analysis and broader healthcare applications.
CK4Gen: A Knowledge Distillation Framework for Generating High-Utility Synthetic Survival Datasets in Healthcare
Oct 22, 2024Access to real clinical data is heavily restricted by privacy regulations, hindering both healthcare research and education. These constraints slow progress in developing new treatments and data-driven healthcare solutions, while also limiting students' access to real-world datasets, leaving them without essential practical skills. High-utility synthetic datasets are therefore critical for advancing research and providing meaningful training material. However, current generative models -- such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) -- produce surface-level realism at the expense of healthcare utility, blending distinct patient profiles and producing synthetic data of limited practical relevance. To overcome these limitations, we introduce CK4Gen (Cox Knowledge for Generation), a novel framework that leverages knowledge distillation from Cox Proportional Hazards (CoxPH) models to create synthetic survival datasets that preserve key clinical characteristics, including hazard ratios and survival curves. CK4Gen avoids the interpolation issues seen in VAEs and GANs by maintaining distinct patient risk profiles, ensuring realistic and reliable outputs for research and educational use. Validated across four benchmark datasets -- GBSG2, ACTG320, WHAS500, and FLChain -- CK4Gen outperforms competing techniques by better aligning real and synthetic data, enhancing survival model performance in both discrimination and calibration via data augmentation. As CK4Gen is scalable across clinical conditions, and with code to be made publicly available, future researchers can apply it to their own datasets to generate synthetic versions suitable for open sharing.
Predicting adverse outcomes following catheter ablation treatment for atrial fibrillation
Nov 22, 2022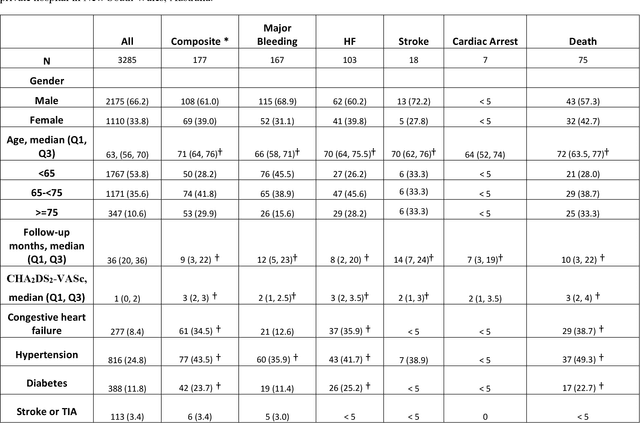
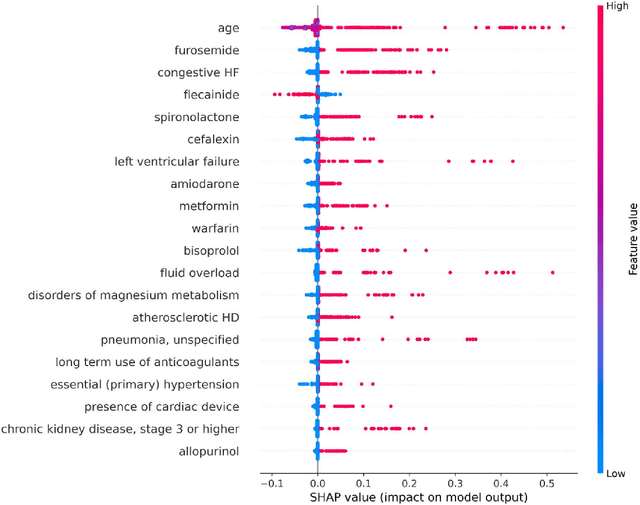
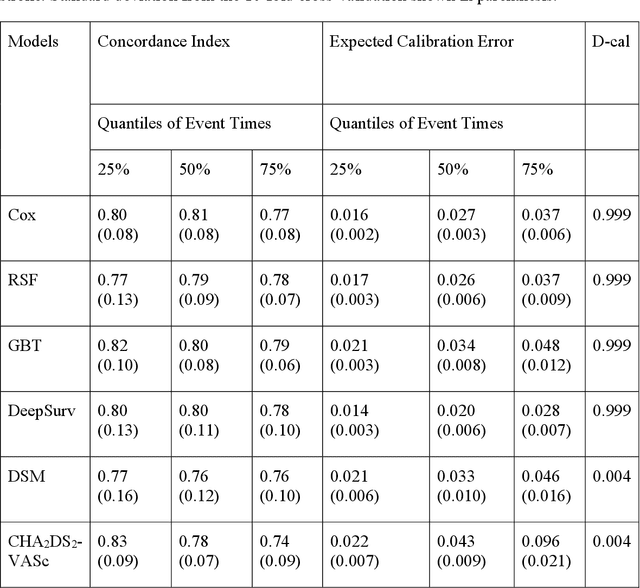
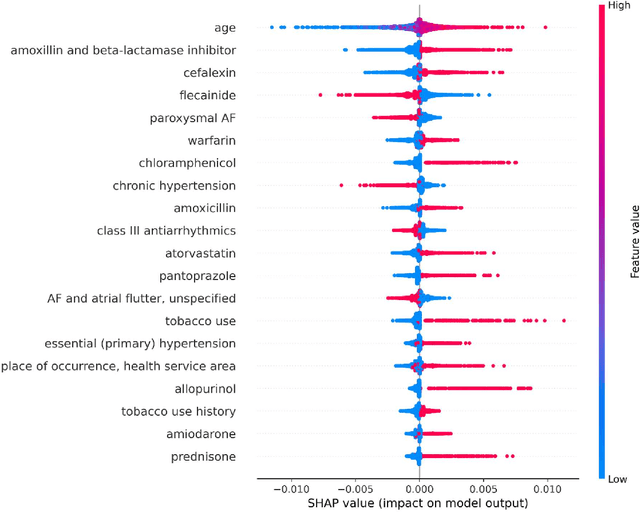
Objective: To develop prognostic survival models for predicting adverse outcomes after catheter ablation treatment for non-valvular atrial fibrillation (AF). Methods: We used a linked dataset including hospital administrative data, prescription medicine claims, emergency department presentations, and death registrations of patients in New South Wales, Australia. The cohort included patients who received catheter ablation for AF. Traditional and deep survival models were trained to predict major bleeding events and a composite of heart failure, stroke, cardiac arrest, and death. Results: Out of a total of 3285 patients in the cohort, 177 (5.3%) experienced the composite outcomeheart failure, stroke, cardiac arrest, deathand 167 (5.1%) experienced major bleeding events after catheter ablation treatment. Models predicting the composite outcome had high risk discrimination accuracy, with the best model having a concordance index > 0.79 at the evaluated time horizons. Models for predicting major bleeding events had poor risk discrimination performance, with all models having a concordance index < 0.66. The most impactful features for the models predicting higher risk were comorbidities indicative of poor health, older age, and therapies commonly used in sicker patients to treat heart failure and AF. Conclusions: Diagnosis and medication history did not contain sufficient information for precise risk prediction of experiencing major bleeding events. The models for predicting the composite outcome have the potential to enable clinicians to identify and manage high-risk patients following catheter ablation proactively. Future research is needed to validate the usefulness of these models in clinical practice.
Incorporating Uncertainty in Learning to Defer Algorithms for Safe Computer-Aided Diagnosis
Sep 03, 2021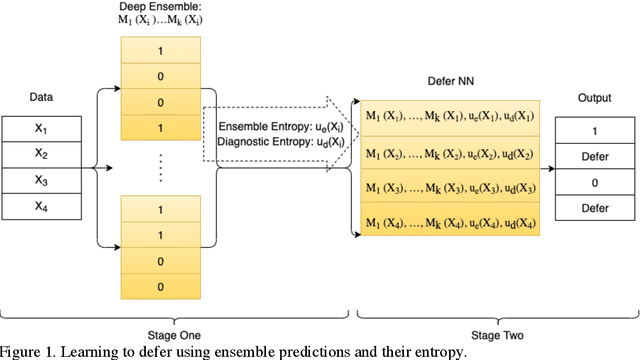
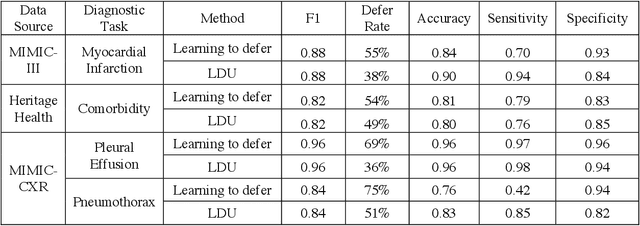
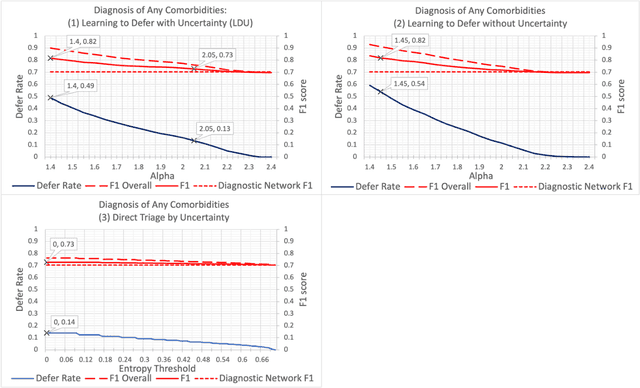
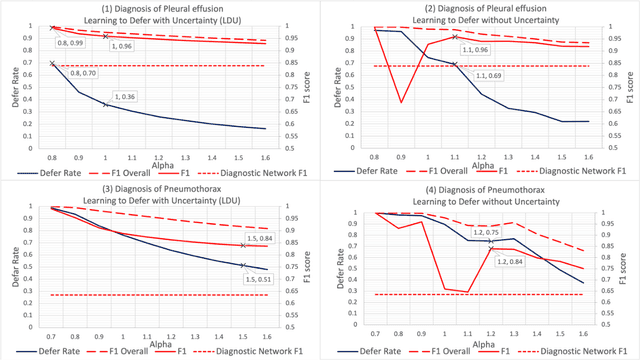
In this study we propose the Learning to Defer with Uncertainty (LDU) algorithm, an approach which considers the model's predictive uncertainty when identifying the patient group to be evaluated by human experts. By identifying patients for whom the uncertainty of computer-aided diagnosis is estimated to be high and defers them for evaluation by human experts, the LDU algorithm can be used to mitigate the risk of erroneous computer-aided diagnoses in clinical settings.
Stochastic Treatment Recommendation with Deep Survival Dose Response Function (DeepSDRF)
Aug 24, 2021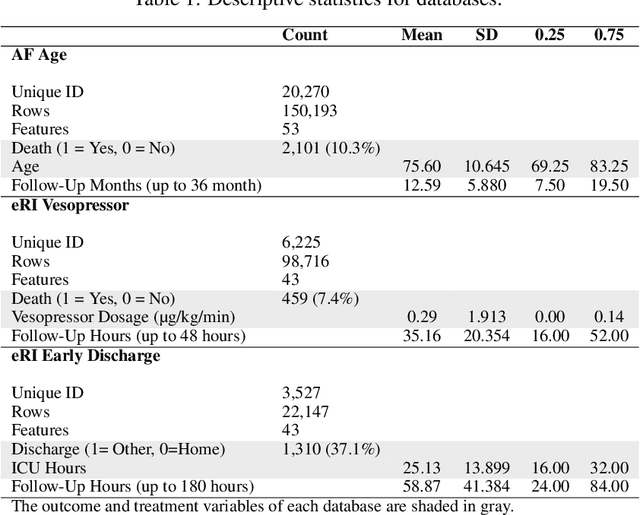
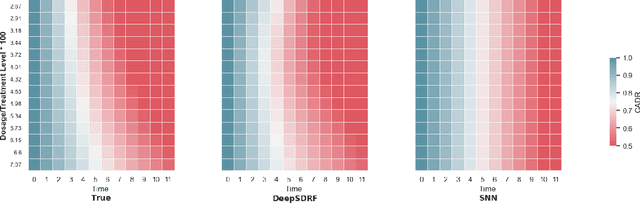
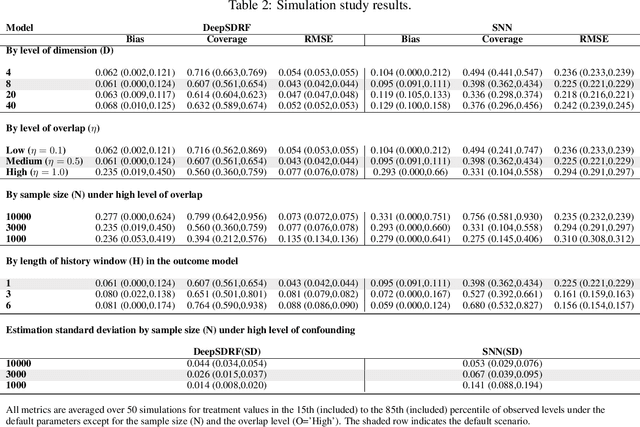
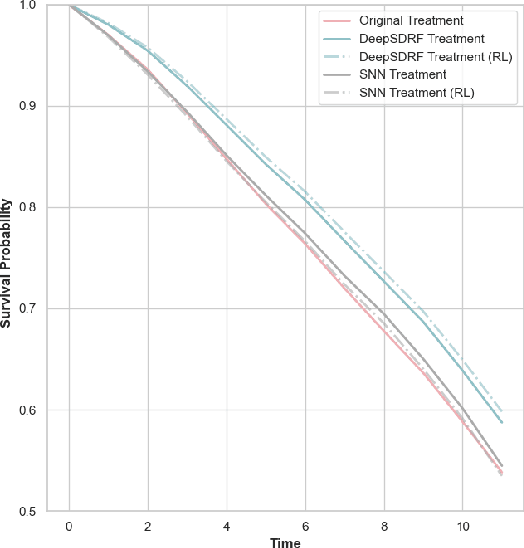
We propose a general formulation for stochastic treatment recommendation problems in settings with clinical survival data, which we call the Deep Survival Dose Response Function (DeepSDRF). That is, we consider the problem of learning the conditional average dose response (CADR) function solely from historical data in which unobserved factors (confounders) affect both observed treatment and time-to-event outcomes. The estimated treatment effect from DeepSDRF enables us to develop recommender algorithms with explanatory insights. We compared two recommender approaches based on random search and reinforcement learning and found similar performance in terms of patient outcome. We tested the DeepSDRF and the corresponding recommender on extensive simulation studies and two empirical databases: 1) the Clinical Practice Research Datalink (CPRD) and 2) the eICU Research Institute (eRI) database. To the best of our knowledge, this is the first time that confounders are taken into consideration for addressing the stochastic treatment effect with observational data in a medical context.
CDSM -- Casual Inference using Deep Bayesian Dynamic Survival Models
Feb 24, 2021
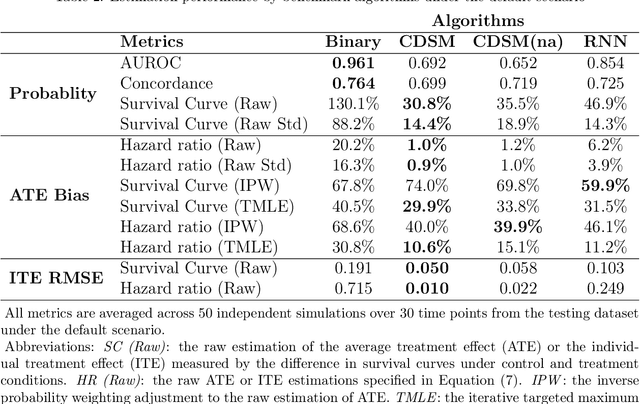
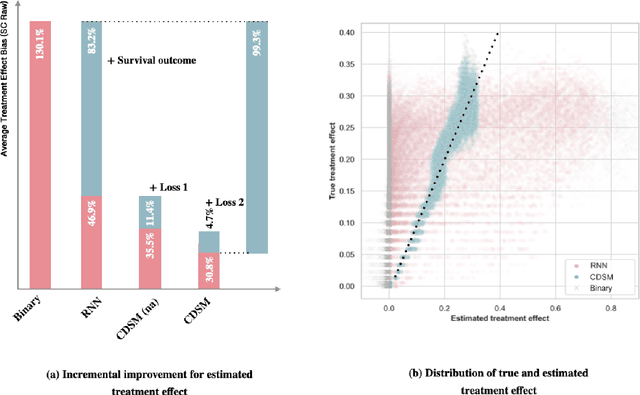
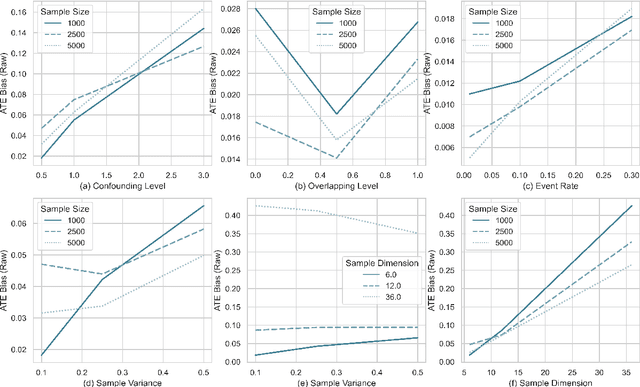
A smart healthcare system that supports clinicians for risk-calibrated treatment assessment typically requires the accurate modeling of time-to-event outcomes. To tackle this sequential treatment effect estimation problem, we developed causal dynamic survival model (CDSM) for causal inference with survival outcomes using longitudinal electronic health record (EHR). CDSM has impressive explanatory performance while maintaining the prediction capability of conventional binary neural network predictors. It borrows the strength from explanatory framework including the survival analysis and counterfactual framework and integrates them with the prediction power from a deep Bayesian recurrent neural network to extract implicit knowledge from EHR data. In two large clinical cohort studies, our model identified the conditional average treatment effect in accordance with previous literature yet detected individual effect heterogeneity over time and patient subgroups. The model provides individualized and clinically interpretable treatment effect estimations to improve patient outcomes.