 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfederated Machine Learning on Horizontally and Vertically Separated Medical Data for Large-Scale Health System Intelligence
Oct 04, 2019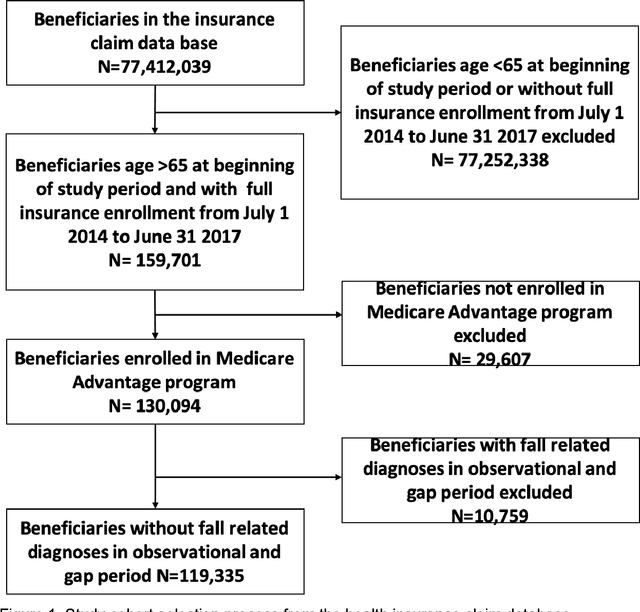
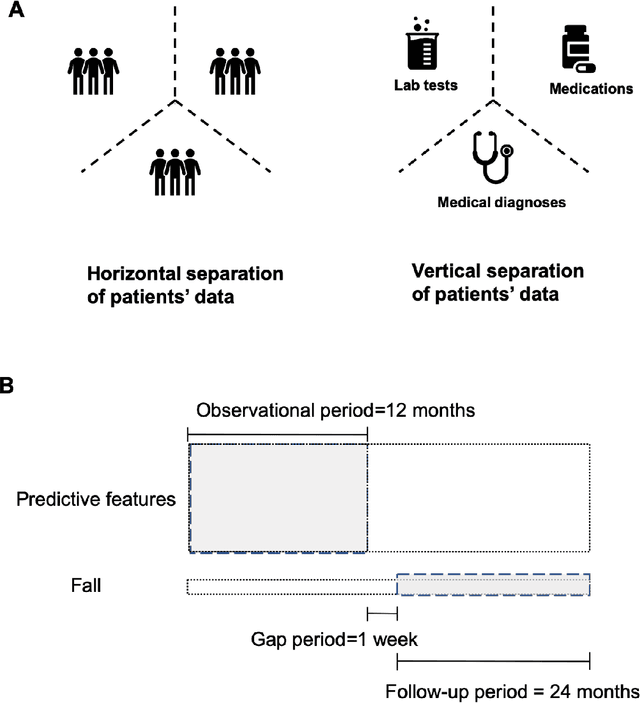
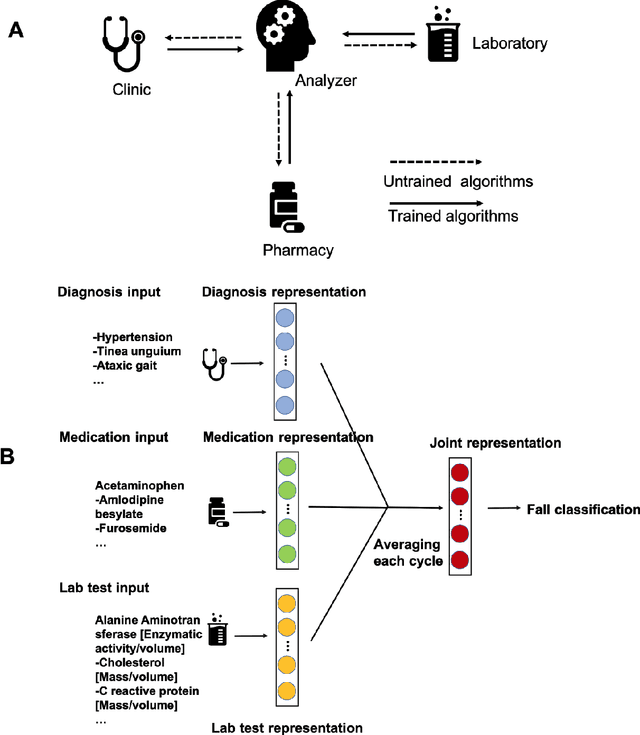
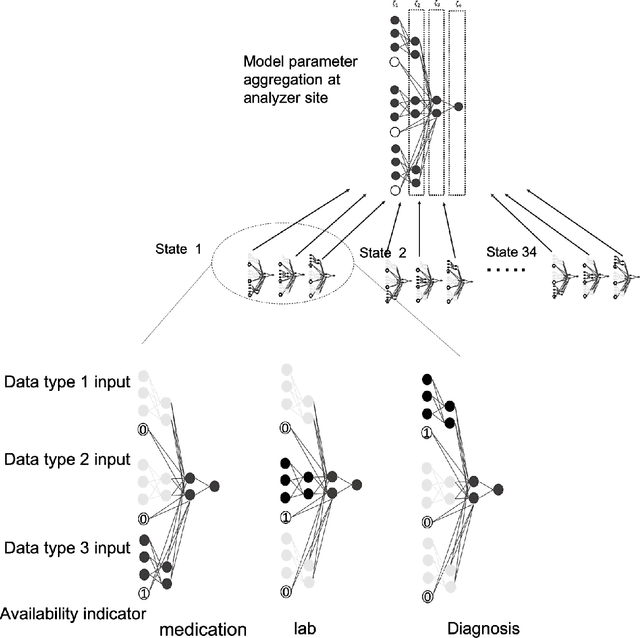
A patient's health information is generally fragmented across silos. Though it is technically feasible to unite data for analysis in a manner that underpins a rapid learning healthcare system, privacy concerns and regulatory barriers limit data centralization. Machine learning can be conducted in a federated manner on patient datasets with the same set of variables, but separated across sites of care. But federated learning cannot handle the situation where different data types for a given patient are separated vertically across different organizations. We call methods that enable machine learning model training on data separated by two or more degrees "confederated machine learning." We built and evaluated a confederated machine learning model to stratify the risk of accidental falls among the elderly
FADL:Federated-Autonomous Deep Learning for Distributed Electronic Health Record
Dec 03, 2018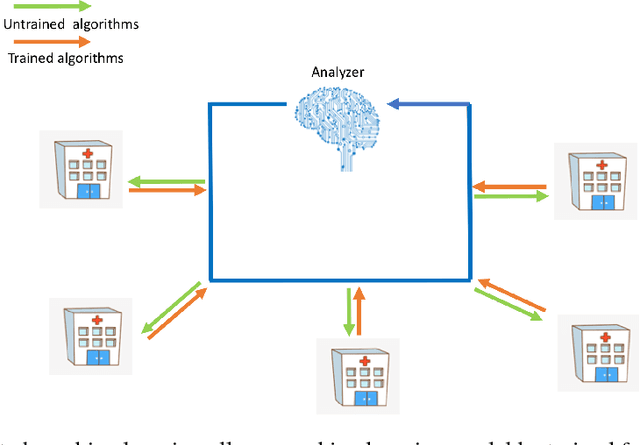
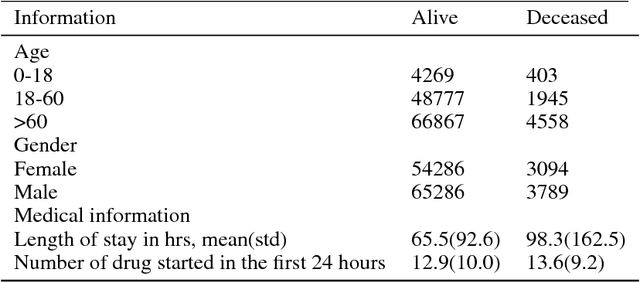
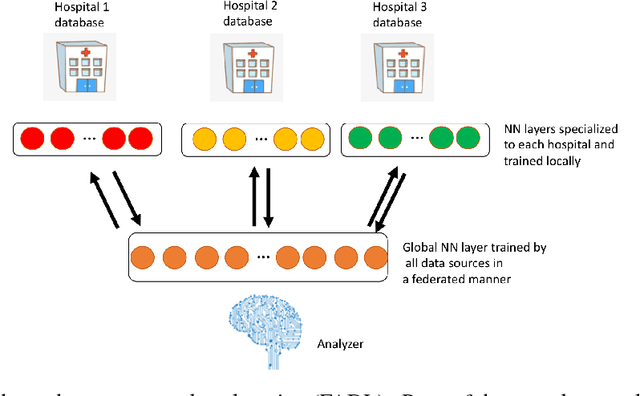

Electronic health record (EHR) data is collected by individual institutions and often stored across locations in silos. Getting access to these data is difficult and slow due to security, privacy, regulatory, and operational issues. We show, using ICU data from 58 different hospitals, that machine learning models to predict patient mortality can be trained efficiently without moving health data out of their silos using a distributed machine learning strategy. We propose a new method, called Federated-Autonomous Deep Learning (FADL) that trains part of the model using all data sources in a distributed manner and other parts using data from specific data sources. We observed that FADL outperforms traditional federated learning strategy and conclude that balance between global and local training is an important factor to consider when design distributed machine learning methods , especially in healthcare.
* Machine Learning for Health (ML4H) Workshop at NeurIPS 2018 arXiv:cs/0101200
Modelling spatiotemporal variation of positive and negative sentiment on Twitter to improve the identification of localised deviations
Feb 22, 2018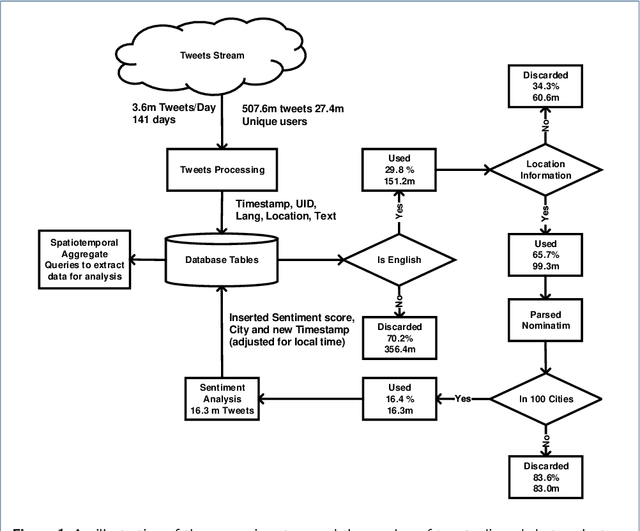
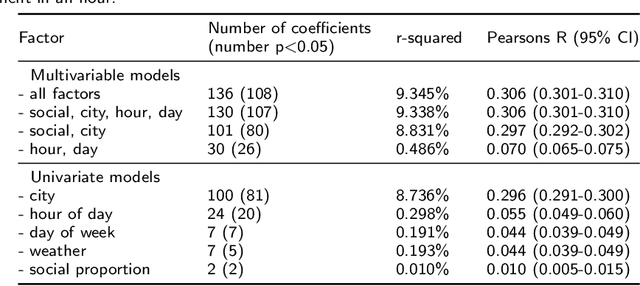
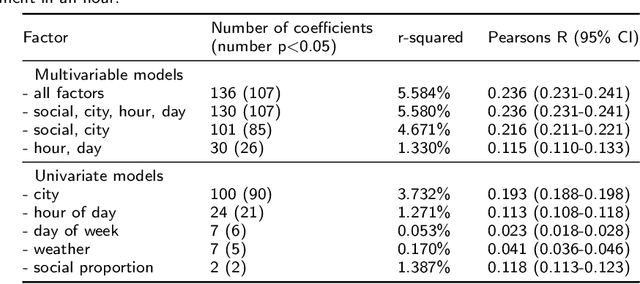
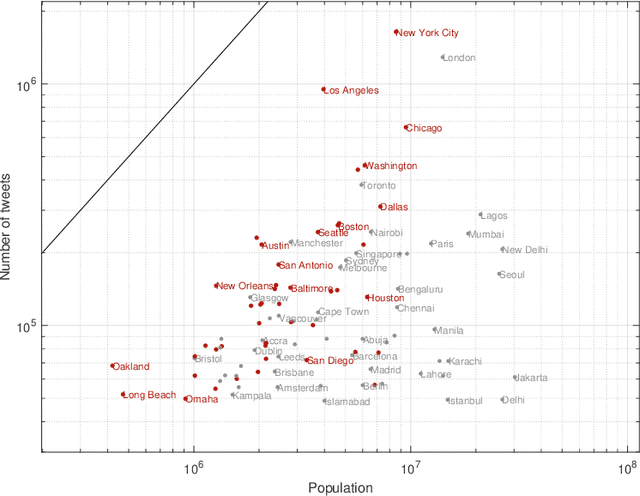
Studies examining how sentiment on social media varies over time and space appear to produce inconsistent results. Analysing 16.54 million English-language tweets from 100 cities posted between 13 July and 30 November 2017, our aim was to clarify how spatiotemporal and social factors contributed to variation in sentiment on Twitter. We estimated positive and negative sentiment for each of the cities using dictionary-based sentiment analysis and constructed models to explain differences in sentiment using time of day, day of week, weather, interaction type (social or non-social), and city as factors. Tests in a distinct but contiguous period of time showed that all factors were independently associated with sentiment. In the full multivariable model of positive (Pearson's R in test data 0.236; 95% CI 0.231-0.241), and negative (Pearson's R in test data 0.306 95% CI 0.301-0.310) sentiment, city and time of day explained more of the variance than other factors. Extreme differences between observed and expected sentiment using the full model appeared to be better aligned with international news events than degenerate models. In applications that aim to detect localised events using the sentiment of Twitter populations, it is useful to account for baseline differences before looking for unexpected changes.