 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable performance analysis towards offline reinforcement learning: A dataset perspective
May 12, 2021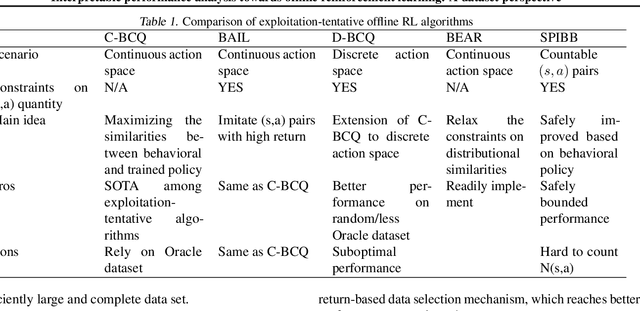

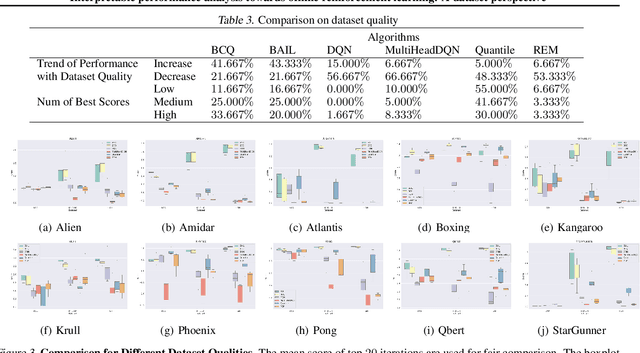
Offline reinforcement learning (RL) has increasingly become the focus of the artificial intelligent research due to its wide real-world applications where the collection of data may be difficult, time-consuming, or costly. In this paper, we first propose a two-fold taxonomy for existing offline RL algorithms from the perspective of exploration and exploitation tendency. Secondly, we derive the explicit expression of the upper bound of extrapolation error and explore the correlation between the performance of different types of algorithms and the distribution of actions under states. Specifically, we relax the strict assumption on the sufficiently large amount of state-action tuples. Accordingly, we provably explain why batch constrained Q-learning (BCQ) performs better than other existing techniques. Thirdly, after identifying the weakness of BCQ on dataset of low mean episode returns, we propose a modified variant based on top return selection mechanism, which is proved to be able to gain state-of-the-art performance on various datasets. Lastly, we create a benchmark platform on the Atari domain, entitled RL easy go (RLEG), at an estimated cost of more than 0.3 million dollars. We make it open-source for fair and comprehensive competitions between offline RL algorithms with complete datasets and checkpoints being provided.