 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCoNet: Long-Short Context Network for Active Speaker Detection
Paper and Code
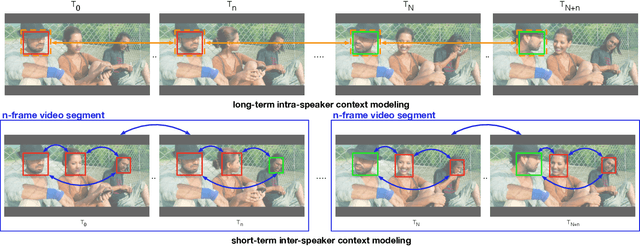
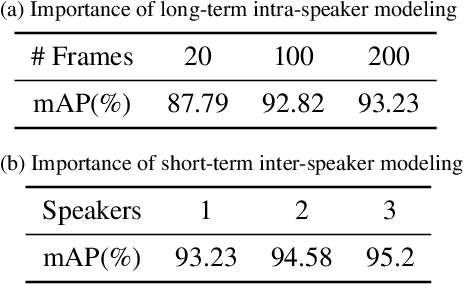
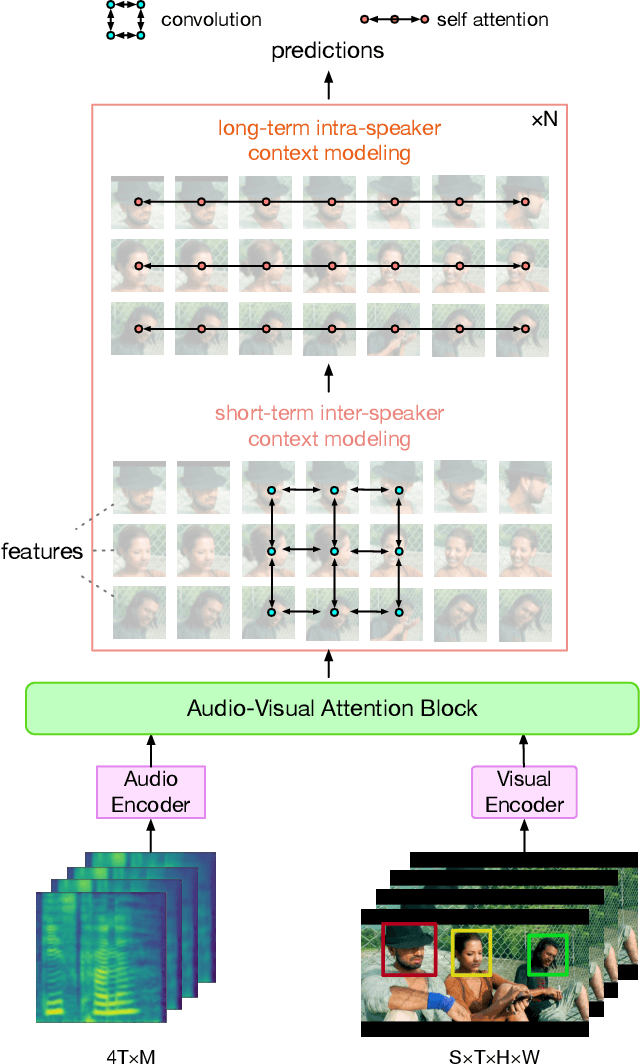

Active Speaker Detection (ASD) aims to identify who is speaking in each frame of a video. ASD reasons from audio and visual information from two contexts: long-term intra-speaker context and short-term inter-speaker context. Long-term intra-speaker context models the temporal dependencies of the same speaker, while short-term inter-speaker context models the interactions of speakers in the same scene. These two contexts are complementary to each other and can help infer the active speaker. Motivated by these observations, we propose LoCoNet, a simple yet effective Long-Short Context Network that models the long-term intra-speaker context and short-term inter-speaker context. We use self-attention to model long-term intra-speaker context due to its effectiveness in modeling long-range dependencies, and convolutional blocks that capture local patterns to model short-term inter-speaker context. Extensive experiments show that LoCoNet achieves state-of-the-art performance on multiple datasets, achieving an mAP of 95.2%(+1.1%) on AVA-ActiveSpeaker, 68.1%(+22%) on Columbia dataset, 97.2%(+2.8%) on Talkies dataset and 59.7%(+8.0%) on Ego4D dataset. Moreover, in challenging cases where multiple speakers are present, or face of active speaker is much smaller than other faces in the same scene, LoCoNet outperforms previous state-of-the-art methods by 3.4% on the AVA-ActiveSpeaker dataset. The code will be released at https://github.com/SJTUwxz/LoCoNet_ASD.