 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective
Paper and Code

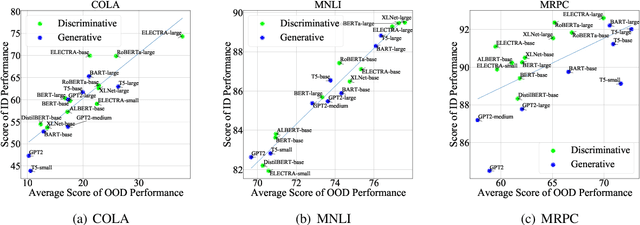


Pre-trained language models (PLMs) improve the model generalization by leveraging massive data as the training corpus in the pre-training phase. However, currently, the out-of-distribution (OOD) generalization becomes a generally ill-posed problem, even for the large-scale PLMs in natural language understanding tasks, which prevents the deployment of NLP methods in the real world. To facilitate the research in this direction, this paper makes the first attempt to establish a unified benchmark named GLUE-X, highlighting the importance of OOD robustness and providing insights on how to measure the robustness of a model and how to improve it. To this end, we collect 13 publicly available datasets as OOD test data, and conduct evaluations on 8 classic NLP tasks over \emph{18} popularly used models. Our findings confirm that the OOD accuracy in NLP tasks needs to be paid more attention to since the significant performance decay compared to ID accuracy has been found in all settings.