 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
Controllable Memory Usage: Balancing Anchoring and Innovation in Long-Term Human-Agent Interaction
Jan 08, 2026As LLM-based agents are increasingly used in long-term interactions, cumulative memory is critical for enabling personalization and maintaining stylistic consistency. However, most existing systems adopt an ``all-or-nothing'' approach to memory usage: incorporating all relevant past information can lead to \textit{Memory Anchoring}, where the agent is trapped by past interactions, while excluding memory entirely results in under-utilization and the loss of important interaction history. We show that an agent's reliance on memory can be modeled as an explicit and user-controllable dimension. We first introduce a behavioral metric of memory dependence to quantify the influence of past interactions on current outputs. We then propose \textbf{Stee}rable \textbf{M}emory Agent, \texttt{SteeM}, a framework that allows users to dynamically regulate memory reliance, ranging from a fresh-start mode that promotes innovation to a high-fidelity mode that closely follows interaction history. Experiments across different scenarios demonstrate that our approach consistently outperforms conventional prompting and rigid memory masking strategies, yielding a more nuanced and effective control for personalized human-agent collaboration.
Generating 6-D Trajectories for Omnidirectional Multirotor Aerial Vehicles in Cluttered Environments
Apr 16, 2024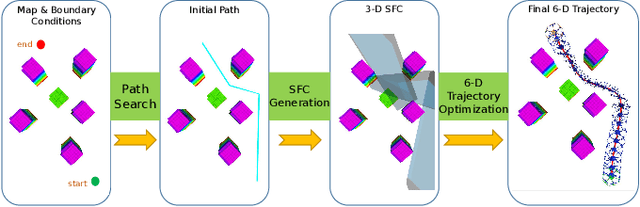

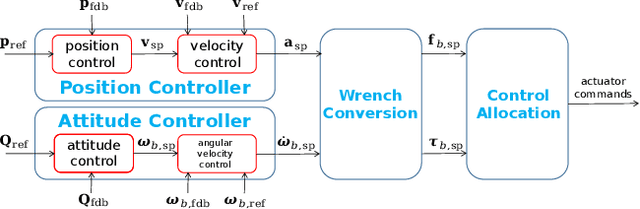
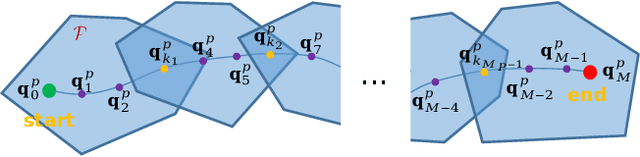
As fully-actuated systems, omnidirectional multirotor aerial vehicles (OMAVs) have more flexible maneuverability and advantages in aggressive flight in cluttered environments than traditional underactuated MAVs. %Due to the high dimensionality of configuration space, making the designed trajectory generation algorithm efficient is challenging. This paper aims to achieve safe flight of OMAVs in cluttered environments. Considering existing static obstacles, an efficient optimization-based framework is proposed to generate 6-D $SE(3)$ trajectories for OMAVs. Given the kinodynamic constraints and the 3D collision-free region represented by a series of intersecting convex polyhedra, the proposed method finally generates a safe and dynamically feasible 6-D trajectory. First, we parameterize the vehicle's attitude into a free 3D vector using stereographic projection to eliminate the constraints inherent in the $SO(3)$ manifold, while the complete $SE(3)$ trajectory is represented as a 6-D polynomial in time without inherent constraints. The vehicle's shape is modeled as a cuboid attached to the body frame to achieve whole-body collision evaluation. Then, we formulate the origin trajectory generation problem as a constrained optimization problem. The original constrained problem is finally transformed into an unconstrained one that can be solved efficiently. To verify the proposed framework's performance, simulations and real-world experiments based on a tilt-rotor hexarotor aerial vehicle are carried out.