 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pseudo Global Fusion Paradigm-Based Cross-View Network for LiDAR-Based Place Recognition
Aug 12, 2025LiDAR-based Place Recognition (LPR) remains a critical task in Embodied Artificial Intelligence (AI) and Autonomous Driving, primarily addressing localization challenges in GPS-denied environments and supporting loop closure detection. Existing approaches reduce place recognition to a Euclidean distance-based metric learning task, neglecting the feature space's intrinsic structures and intra-class variances. Such Euclidean-centric formulation inherently limits the model's capacity to capture nonlinear data distributions, leading to suboptimal performance in complex environments and temporal-varying scenarios. To address these challenges, we propose a novel cross-view network based on an innovative fusion paradigm. Our framework introduces a pseudo-global information guidance mechanism that coordinates multi-modal branches to perform feature learning within a unified semantic space. Concurrently, we propose a Manifold Adaptation and Pairwise Variance-Locality Learning Metric that constructs a Symmetric Positive Definite (SPD) matrix to compute Mahalanobis distance, superseding traditional Euclidean distance metrics. This geometric formulation enables the model to accurately characterize intrinsic data distributions and capture complex inter-class dependencies within the feature space. Experimental results demonstrate that the proposed algorithm achieves competitive performance, particularly excelling in complex environmental conditions.
MambaFlow: A Novel and Flow-guided State Space Model for Scene Flow Estimation
Feb 24, 2025Scene flow estimation aims to predict 3D motion from consecutive point cloud frames, which is of great interest in autonomous driving field. Existing methods face challenges such as insufficient spatio-temporal modeling and inherent loss of fine-grained feature during voxelization. However, the success of Mamba, a representative state space model (SSM) that enables global modeling with linear complexity, provides a promising solution. In this paper, we propose MambaFlow, a novel scene flow estimation network with a mamba-based decoder. It enables deep interaction and coupling of spatio-temporal features using a well-designed backbone. Innovatively, we steer the global attention modeling of voxel-based features with point offset information using an efficient Mamba-based decoder, learning voxel-to-point patterns that are used to devoxelize shared voxel representations into point-wise features. To further enhance the model's generalization capabilities across diverse scenarios, we propose a novel scene-adaptive loss function that automatically adapts to different motion patterns.Extensive experiments on the Argoverse 2 benchmark demonstrate that MambaFlow achieves state-of-the-art performance with real-time inference speed among existing works, enabling accurate flow estimation in real-world urban scenarios. The code is available at https://github.com/SCNU-RISLAB/MambaFlow.
OverlapMamba: Novel Shift State Space Model for LiDAR-based Place Recognition
May 13, 2024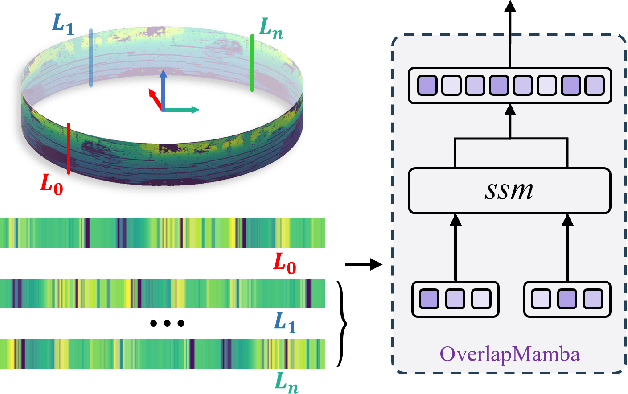
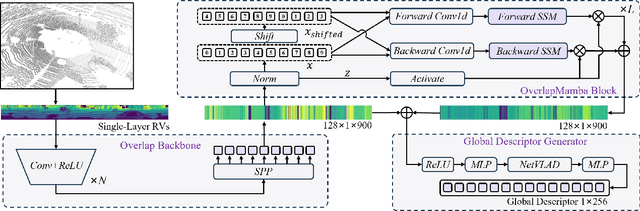
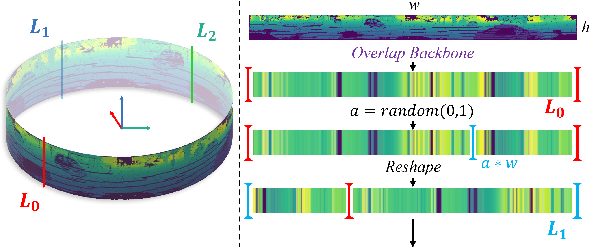
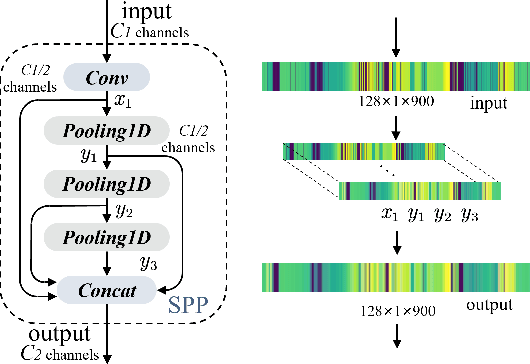
Place recognition is the foundation for enabling autonomous systems to achieve independent decision-making and safe operations. It is also crucial in tasks such as loop closure detection and global localization within SLAM. Previous methods utilize mundane point cloud representations as input and deep learning-based LiDAR-based Place Recognition (LPR) approaches employing different point cloud image inputs with convolutional neural networks (CNNs) or transformer architectures. However, the recently proposed Mamba deep learning model, combined with state space models (SSMs), holds great potential for long sequence modeling. Therefore, we developed OverlapMamba, a novel network for place recognition, which represents input range views (RVs) as sequences. In a novel way, we employ a stochastic reconstruction approach to build shift state space models, compressing the visual representation. Evaluated on three different public datasets, our method effectively detects loop closures, showing robustness even when traversing previously visited locations from different directions. Relying on raw range view inputs, it outperforms typical LiDAR and multi-view combination methods in time complexity and speed, indicating strong place recognition capabilities and real-time efficiency.