 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Anything: 4D Face Reconstruction from Any Image Sequence
Apr 21, 2026Accurate reconstruction and tracking of dynamic human faces from image sequences is challenging because non-rigid deformations, expression changes, and viewpoint variations occur simultaneously, creating significant ambiguity in geometry and correspondence estimation. We present a unified method for high-fidelity 4D facial reconstruction based on canonical facial point prediction, a representation that assigns each pixel a normalized facial coordinate in a shared canonical space. This formulation transforms dense tracking and dynamic reconstruction into a canonical reconstruction problem, enabling temporally consistent geometry and reliable correspondences within a single feed-forward model. By jointly predicting depth and canonical coordinates, our method enables accurate depth estimation, temporally stable reconstruction, dense 3D geometry, and robust facial point tracking within a single architecture. We implement this formulation using a transformer-based model that jointly predicts depth and canonical facial coordinates, trained using multi-view geometry data that non-rigidly warps into the canonical space. Extensive experiments on image and video benchmarks demonstrate state-of-the-art performance across reconstruction and tracking tasks, achieving approximately 3$\times$ lower correspondence error and faster inference than prior dynamic reconstruction methods, while improving depth accuracy by 16%. These results highlight canonical facial point prediction as an effective foundation for unified feed-forward 4D facial reconstruction.
G3DST: Generalizing 3D Style Transfer with Neural Radiance Fields across Scenes and Styles
Aug 24, 2024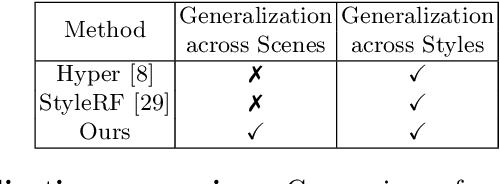
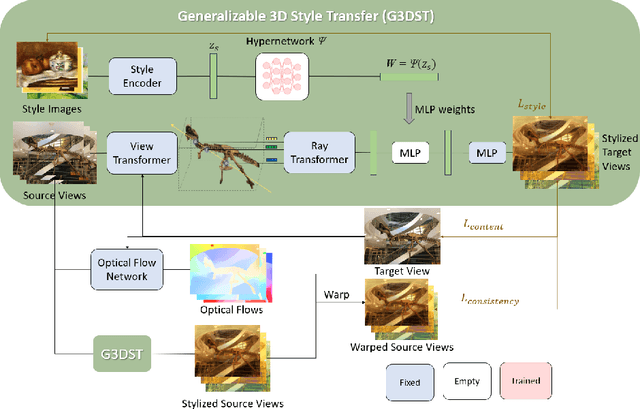
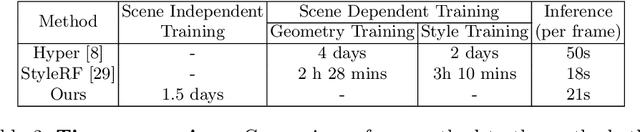

Neural Radiance Fields (NeRF) have emerged as a powerful tool for creating highly detailed and photorealistic scenes. Existing methods for NeRF-based 3D style transfer need extensive per-scene optimization for single or multiple styles, limiting the applicability and efficiency of 3D style transfer. In this work, we overcome the limitations of existing methods by rendering stylized novel views from a NeRF without the need for per-scene or per-style optimization. To this end, we take advantage of a generalizable NeRF model to facilitate style transfer in 3D, thereby enabling the use of a single learned model across various scenes. By incorporating a hypernetwork into a generalizable NeRF, our approach enables on-the-fly generation of stylized novel views. Moreover, we introduce a novel flow-based multi-view consistency loss to preserve consistency across multiple views. We evaluate our method across various scenes and artistic styles and show its performance in generating high-quality and multi-view consistent stylized images without the need for a scene-specific implicit model. Our findings demonstrate that this approach not only achieves a good visual quality comparable to that of per-scene methods but also significantly enhances efficiency and applicability, marking a notable advancement in the field of 3D style transfer.
Fantastic Style Channels and Where to Find Them: A Submodular Framework for Discovering Diverse Directions in GANs
Mar 31, 2022
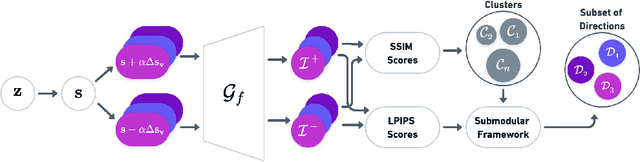


The discovery of interpretable directions in the latent spaces of pre-trained GAN models has recently become a popular topic. In particular, StyleGAN2 has enabled various image generation and manipulation tasks due to its rich and disentangled latent spaces. The discovery of such directions is typically done either in a supervised manner, which requires annotated data for each desired manipulation or in an unsupervised manner, which requires a manual effort to identify the directions. As a result, existing work typically finds only a handful of directions in which controllable edits can be made. In this study, we design a novel submodular framework that finds the most representative and diverse subset of directions in the latent space of StyleGAN2. Our approach takes advantage of the latent space of channel-wise style parameters, so-called style space, in which we cluster channels that perform similar manipulations into groups. Our framework promotes diversity by using the notion of clusters and can be efficiently solved with a greedy optimization scheme. We evaluate our framework with qualitative and quantitative experiments and show that our method finds more diverse and disentangled directions. Our project page can be found at http://catlab-team.github.io/fantasticstyles.
Discovering Multiple and Diverse Directions for Cognitive Image Properties
Feb 23, 2022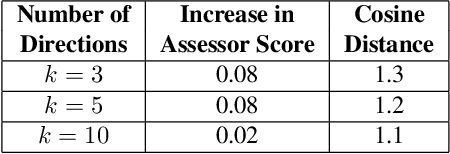
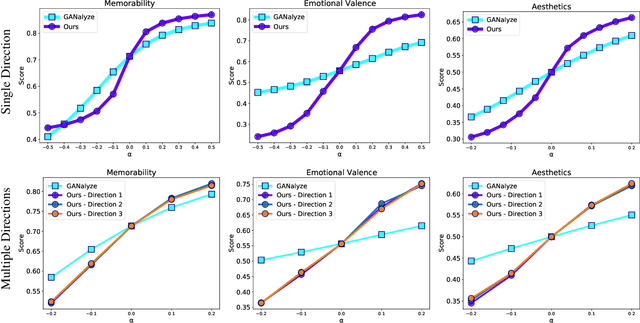


Recent research has shown that it is possible to find interpretable directions in the latent spaces of pre-trained GANs. These directions enable controllable generation and support a variety of semantic editing operations. While previous work has focused on discovering a single direction that performs a desired editing operation such as zoom-in, limited work has been done on the discovery of multiple and diverse directions that can achieve the desired edit. In this work, we propose a novel framework that discovers multiple and diverse directions for a given property of interest. In particular, we focus on the manipulation of cognitive properties such as Memorability, Emotional Valence and Aesthetics. We show with extensive experiments that our method successfully manipulates these properties while producing diverse outputs. Our project page and source code can be found at http://catlab-team.github.io/latentcognitive.
StyleMC: Multi-Channel Based Fast Text-Guided Image Generation and Manipulation
Dec 15, 2021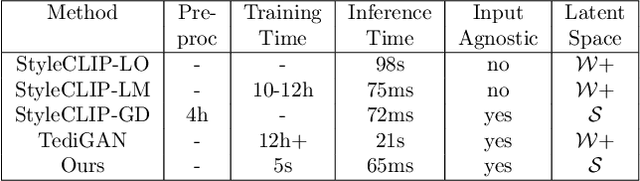
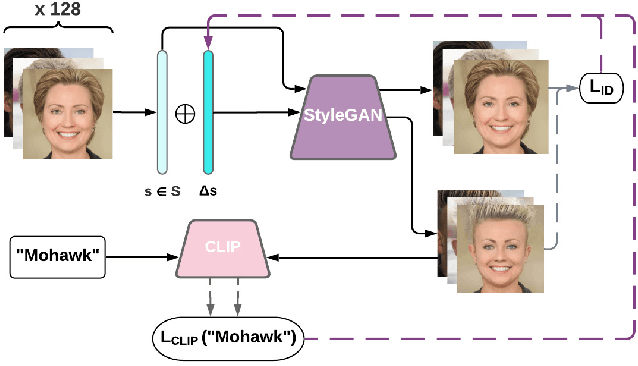


Discovering meaningful directions in the latent space of GANs to manipulate semantic attributes typically requires large amounts of labeled data. Recent work aims to overcome this limitation by leveraging the power of Contrastive Language-Image Pre-training (CLIP), a joint text-image model. While promising, these methods require several hours of preprocessing or training to achieve the desired manipulations. In this paper, we present StyleMC, a fast and efficient method for text-driven image generation and manipulation. StyleMC uses a CLIP-based loss and an identity loss to manipulate images via a single text prompt without significantly affecting other attributes. Unlike prior work, StyleMC requires only a few seconds of training per text prompt to find stable global directions, does not require prompt engineering and can be used with any pre-trained StyleGAN2 model. We demonstrate the effectiveness of our method and compare it to state-of-the-art methods. Our code can be found at http://catlab-team.github.io/stylemc.
Exploring Latent Dimensions of Crowd-sourced Creativity
Dec 13, 2021


Recently, the discovery of interpretable directions in the latent spaces of pre-trained GANs has become a popular topic. While existing works mostly consider directions for semantic image manipulations, we focus on an abstract property: creativity. Can we manipulate an image to be more or less creative? We build our work on the largest AI-based creativity platform, Artbreeder, where users can generate images using pre-trained GAN models. We explore the latent dimensions of images generated on this platform and present a novel framework for manipulating images to make them more creative. Our code and dataset are available at http://github.com/catlab-team/latentcreative.