 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Pirates Need a Map: Stealing Seeds helps Stealing Prompts
Sep 11, 2025Diffusion models have significantly advanced text-to-image generation, enabling the creation of highly realistic images conditioned on textual prompts and seeds. Given the considerable intellectual and economic value embedded in such prompts, prompt theft poses a critical security and privacy concern. In this paper, we investigate prompt-stealing attacks targeting diffusion models. We reveal that numerical optimization-based prompt recovery methods are fundamentally limited as they do not account for the initial random noise used during image generation. We identify and exploit a noise-generation vulnerability (CWE-339), prevalent in major image-generation frameworks, originating from PyTorch's restriction of seed values to a range of $2^{32}$ when generating the initial random noise on CPUs. Through a large-scale empirical analysis conducted on images shared via the popular platform CivitAI, we demonstrate that approximately 95% of these images' seed values can be effectively brute-forced in 140 minutes per seed using our seed-recovery tool, SeedSnitch. Leveraging the recovered seed, we propose PromptPirate, a genetic algorithm-based optimization method explicitly designed for prompt stealing. PromptPirate surpasses state-of-the-art methods, i.e., PromptStealer, P2HP, and CLIP-Interrogator, achieving an 8-11% improvement in LPIPS similarity. Furthermore, we introduce straightforward and effective countermeasures that render seed stealing, and thus optimization-based prompt stealing, ineffective. We have disclosed our findings responsibly and initiated coordinated mitigation efforts with the developers to address this critical vulnerability.
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras
Dec 12, 2023



We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
Facial De-occlusion Network for Virtual Telepresence Systems
Oct 23, 2022To see what is not in the image is one of the broader missions of computer vision. Technology to inpaint images has made significant progress with the coming of deep learning. This paper proposes a method to tackle occlusion specific to human faces. Virtual presence is a promising direction in communication and recreation for the future. However, Virtual Reality (VR) headsets occlude a significant portion of the face, hindering the photo-realistic appearance of the face in the virtual world. State-of-the-art image inpainting methods for de-occluding the eye region does not give usable results. To this end, we propose a working solution that gives usable results to tackle this problem enabling the use of the real-time photo-realistic de-occluded face of the user in VR settings.
Attention based Occlusion Removal for Hybrid Telepresence Systems
Dec 02, 2021
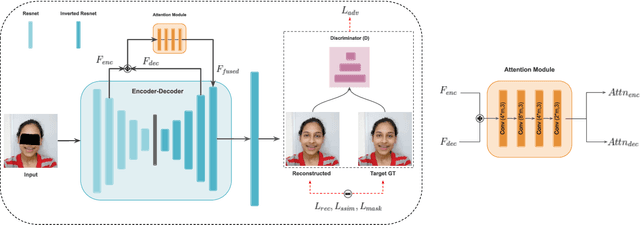


Traditionally, video conferencing is a widely adopted solution for telecommunication, but a lack of immersiveness comes inherently due to the 2D nature of facial representation. The integration of Virtual Reality (VR) in a communication/telepresence system through Head Mounted Displays (HMDs) promises to provide users a much better immersive experience. However, HMDs cause hindrance by blocking the facial appearance and expressions of the user. To overcome these issues, we propose a novel attention-enabled encoder-decoder architecture for HMD de-occlusion. We also propose to train our person-specific model using short videos (1-2 minutes) of the user, captured in varying appearances, and demonstrated generalization to unseen poses and appearances of the user. We report superior qualitative and quantitative results over state-of-the-art methods. We also present applications of this approach to hybrid video teleconferencing using existing animation and 3D face reconstruction pipelines.