 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spoken Discourse Modeling in Language Models Using Gestural Cues
Mar 05, 2025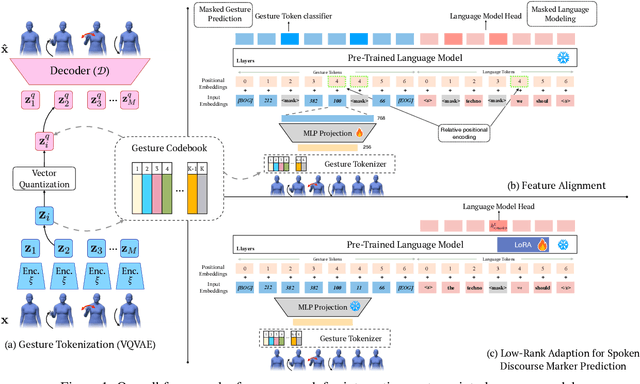
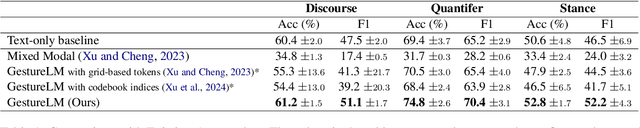


Research in linguistics shows that non-verbal cues, such as gestures, play a crucial role in spoken discourse. For example, speakers perform hand gestures to indicate topic shifts, helping listeners identify transitions in discourse. In this work, we investigate whether the joint modeling of gestures using human motion sequences and language can improve spoken discourse modeling in language models. To integrate gestures into language models, we first encode 3D human motion sequences into discrete gesture tokens using a VQ-VAE. These gesture token embeddings are then aligned with text embeddings through feature alignment, mapping them into the text embedding space. To evaluate the gesture-aligned language model on spoken discourse, we construct text infilling tasks targeting three key discourse cues grounded in linguistic research: discourse connectives, stance markers, and quantifiers. Results show that incorporating gestures enhances marker prediction accuracy across the three tasks, highlighting the complementary information that gestures can offer in modeling spoken discourse. We view this work as an initial step toward leveraging non-verbal cues to advance spoken language modeling in language models.
Retrieving Semantics from the Deep: an RAG Solution for Gesture Synthesis
Dec 09, 2024



Non-verbal communication often comprises of semantically rich gestures that help convey the meaning of an utterance. Producing such semantic co-speech gestures has been a major challenge for the existing neural systems that can generate rhythmic beat gestures, but struggle to produce semantically meaningful gestures. Therefore, we present RAG-Gesture, a diffusion-based gesture generation approach that leverages Retrieval Augmented Generation (RAG) to produce natural-looking and semantically rich gestures. Our neuro-explicit gesture generation approach is designed to produce semantic gestures grounded in interpretable linguistic knowledge. We achieve this by using explicit domain knowledge to retrieve exemplar motions from a database of co-speech gestures. Once retrieved, we then inject these semantic exemplar gestures into our diffusion-based gesture generation pipeline using DDIM inversion and retrieval guidance at the inference time without any need of training. Further, we propose a control paradigm for guidance, that allows the users to modulate the amount of influence each retrieval insertion has over the generated sequence. Our comparative evaluations demonstrate the validity of our approach against recent gesture generation approaches. The reader is urged to explore the results on our project page.