 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURHand: Universal Relightable Hands
Jan 10, 2024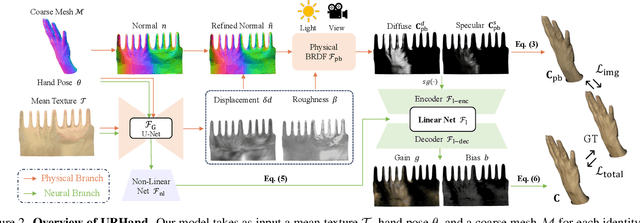
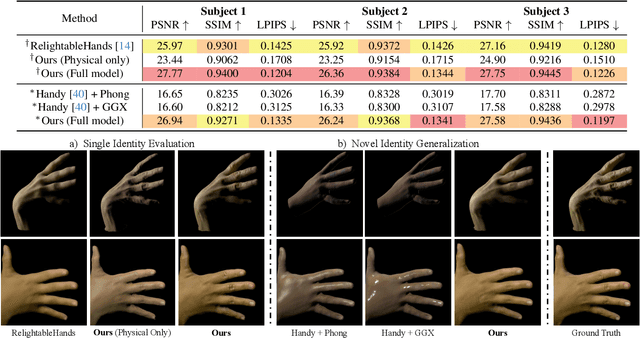
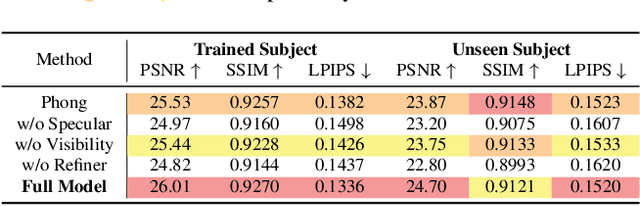
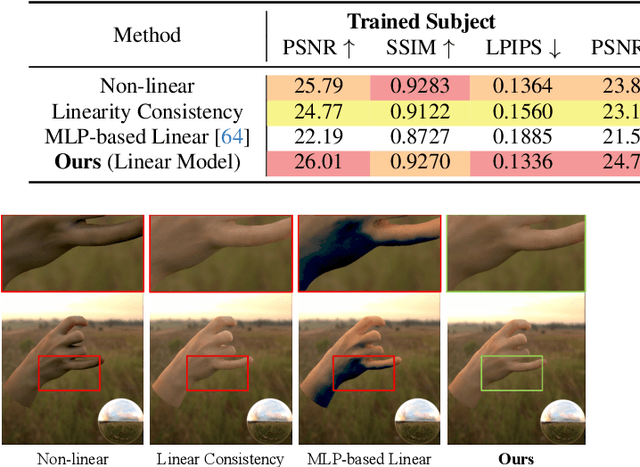
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
A Dataset of Relighted 3D Interacting Hands
Oct 26, 2023



The two-hand interaction is one of the most challenging signals to analyze due to the self-similarity, complicated articulations, and occlusions of hands. Although several datasets have been proposed for the two-hand interaction analysis, all of them do not achieve 1) diverse and realistic image appearances and 2) diverse and large-scale groundtruth (GT) 3D poses at the same time. In this work, we propose Re:InterHand, a dataset of relighted 3D interacting hands that achieve the two goals. To this end, we employ a state-of-the-art hand relighting network with our accurately tracked two-hand 3D poses. We compare our Re:InterHand with existing 3D interacting hands datasets and show the benefit of it. Our Re:InterHand is available in https://mks0601.github.io/ReInterHand/.