 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuseVis: Interpreting neural networks for image fusion using per-pixel saliency visualization
Paper and Code
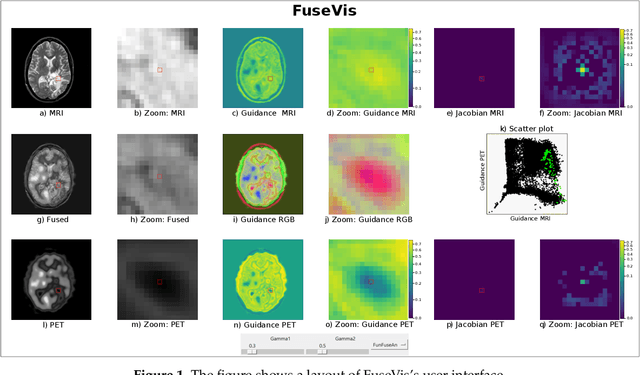

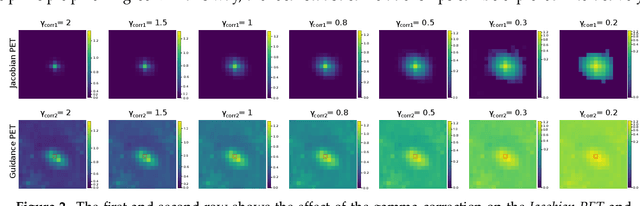

Image fusion helps in merging two or more images to construct a more informative single fused image. Recently, unsupervised learning based convolutional neural networks (CNN) have been utilized for different types of image fusion tasks such as medical image fusion, infrared-visible image fusion for autonomous driving as well as multi-focus and multi-exposure image fusion for satellite imagery. However, it is challenging to analyze the reliability of these CNNs for the image fusion tasks since no groundtruth is available. This led to the use of a wide variety of model architectures and optimization functions yielding quite different fusion results. Additionally, due to the highly opaque nature of such neural networks, it is difficult to explain the internal mechanics behind its fusion results. To overcome these challenges, we present a novel real-time visualization tool, named FuseVis, with which the end-user can compute per-pixel saliency maps that examine the influence of the input image pixels on each pixel of the fused image. We trained several image fusion based CNNs on medical image pairs and then using our FuseVis tool, we performed case studies on a specific clinical application by interpreting the saliency maps from each of the fusion methods. We specifically visualized the relative influence of each input image on the predictions of the fused image and showed that some of the evaluated image fusion methods are better suited for the specific clinical application. To the best of our knowledge, currently, there is no approach for visual analysis of neural networks for image fusion. Therefore, this work opens up a new research direction to improve the interpretability of deep fusion networks. The FuseVis tool can also be adapted in other deep neural network based image processing applications to make them interpretable.