 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Neural Rewriter for Vehicle Routing with Limited Disclosure of Costs
Paper and Code
Jun 13, 2022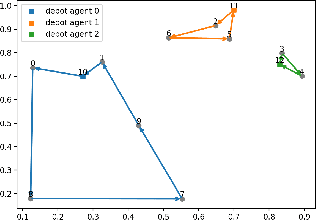

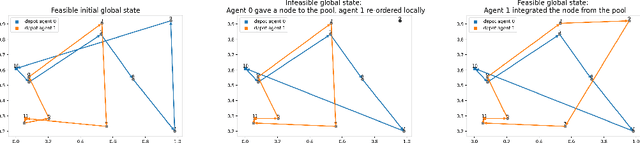

We interpret solving the multi-vehicle routing problem as a team Markov game with partially observable costs. For a given set of customers to serve, the playing agents (vehicles) have the common goal to determine the team-optimal agent routes with minimal total cost. Each agent thereby observes only its own cost. Our multi-agent reinforcement learning approach, the so-called multi-agent Neural Rewriter, builds on the single-agent Neural Rewriter to solve the problem by iteratively rewriting solutions. Parallel agent action execution and partial observability require new rewriting rules for the game. We propose the introduction of a so-called pool in the system which serves as a collection point for unvisited nodes. It enables agents to act simultaneously and exchange nodes in a conflict-free manner. We realize limited disclosure of agent-specific costs by only sharing them during learning. During inference, each agents acts decentrally, solely based on its own cost. First empirical results on small problem sizes demonstrate that we reach a performance close to the employed OR-Tools benchmark which operates in the perfect cost information setting.