 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning an Unbiased Classifier from Biased Data via Conditional Adversarial Debiasing
Paper and Code
Mar 10, 2021
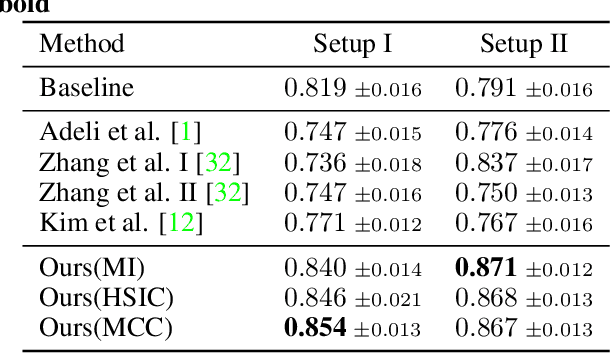

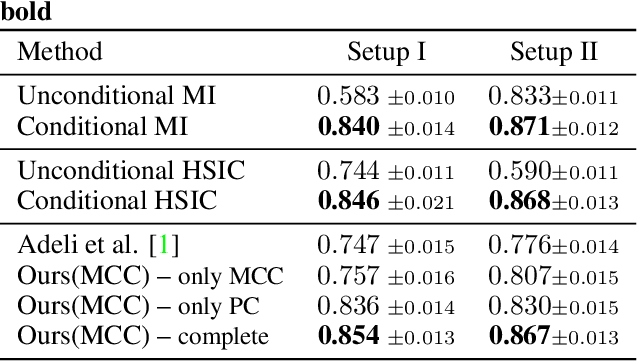
Bias in classifiers is a severe issue of modern deep learning methods, especially for their application in safety- and security-critical areas. Often, the bias of a classifier is a direct consequence of a bias in the training dataset, frequently caused by the co-occurrence of relevant features and irrelevant ones. To mitigate this issue, we require learning algorithms that prevent the propagation of bias from the dataset into the classifier. We present a novel adversarial debiasing method, which addresses a feature that is spuriously connected to the labels of training images but statistically independent of the labels for test images. Thus, the automatic identification of relevant features during training is perturbed by irrelevant features. This is the case in a wide range of bias-related problems for many computer vision tasks, such as automatic skin cancer detection or driver assistance. We argue by a mathematical proof that our approach is superior to existing techniques for the abovementioned bias. Our experiments show that our approach performs better than state-of-the-art techniques on a well-known benchmark dataset with real-world images of cats and dogs.