 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectromyography-Informed Facial Expression Reconstruction for Physiological-Based Synthesis and Analysis
Mar 12, 2025
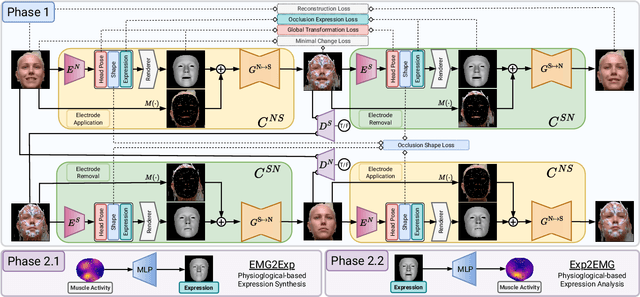

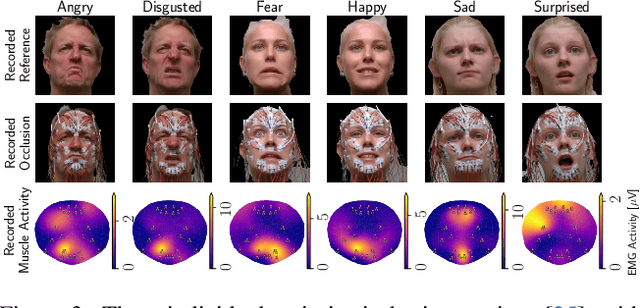
The relationship between muscle activity and resulting facial expressions is crucial for various fields, including psychology, medicine, and entertainment. The synchronous recording of facial mimicry and muscular activity via surface electromyography (sEMG) provides a unique window into these complex dynamics. Unfortunately, existing methods for facial analysis cannot handle electrode occlusion, rendering them ineffective. Even with occlusion-free reference images of the same person, variations in expression intensity and execution are unmatchable. Our electromyography-informed facial expression reconstruction (EIFER) approach is a novel method to restore faces under sEMG occlusion faithfully in an adversarial manner. We decouple facial geometry and visual appearance (e.g., skin texture, lighting, electrodes) by combining a 3D Morphable Model (3DMM) with neural unpaired image-to-image translation via reference recordings. Then, EIFER learns a bidirectional mapping between 3DMM expression parameters and muscle activity, establishing correspondence between the two domains. We validate the effectiveness of our approach through experiments on a dataset of synchronized sEMG recordings and facial mimicry, demonstrating faithful geometry and appearance reconstruction. Further, we synthesize expressions based on muscle activity and how observed expressions can predict dynamic muscle activity. Consequently, EIFER introduces a new paradigm for facial electromyography, which could be extended to other forms of multi-modal face recordings.
Facing Asymmetry -- Uncovering the Causal Link between Facial Symmetry and Expression Classifiers using Synthetic Interventions
Sep 24, 2024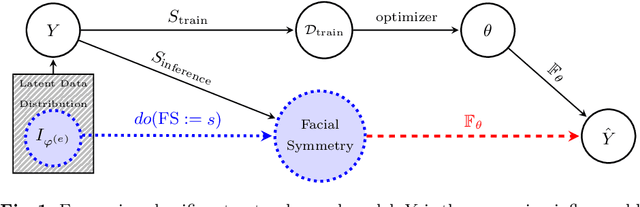
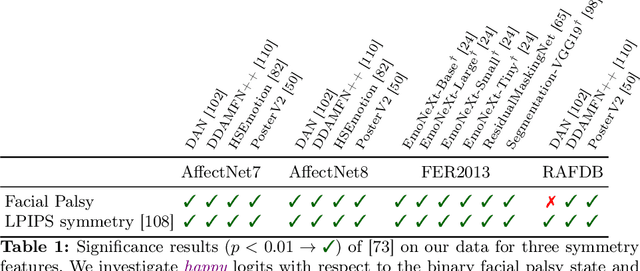

Understanding expressions is vital for deciphering human behavior, and nowadays, end-to-end trained black box models achieve high performance. Due to the black-box nature of these models, it is unclear how they behave when applied out-of-distribution. Specifically, these models show decreased performance for unilateral facial palsy patients. We hypothesize that one crucial factor guiding the internal decision rules is facial symmetry. In this work, we use insights from causal reasoning to investigate the hypothesis. After deriving a structural causal model, we develop a synthetic interventional framework. This approach allows us to analyze how facial symmetry impacts a network's output behavior while keeping other factors fixed. All 17 investigated expression classifiers significantly lower their output activations for reduced symmetry. This result is congruent with observed behavior on real-world data from healthy subjects and facial palsy patients. As such, our investigation serves as a case study for identifying causal factors that influence the behavior of black-box models.
The Power of Properties: Uncovering the Influential Factors in Emotion Classification
Apr 11, 2024



Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decision-making processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behavior requires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.
JeFaPaTo -- A joint toolbox for blinking analysis and facial features extraction
Feb 13, 2024Analyzing facial features and expressions is a complex task in computer vision. The human face is intricate, with significant shape, texture, and appearance variations. In medical contexts, facial structures that differ from the norm, such as those affected by paralysis, are particularly important to study and require precise analysis. One area of interest is the subtle movements involved in blinking, a process that is not yet fully understood and needs high-resolution, time-specific analysis for detailed understanding. However, a significant challenge is that many advanced computer vision techniques demand programming skills, making them less accessible to medical professionals who may not have these skills. The Jena Facial Palsy Toolbox (JeFaPaTo) has been developed to bridge this gap. It utilizes cutting-edge computer vision algorithms and offers a user-friendly interface for those without programming expertise. This toolbox is designed to make advanced facial analysis more accessible to medical experts, simplifying integration into their workflow. The state of the eye closure is of high interest to medical experts, e.g., in the context of facial palsy or Parkinson's disease. Due to facial nerve damage, the eye-closing process might be impaired and could lead to many undesirable side effects. Hence, more than a simple distinction between open and closed eyes is required for a detailed analysis. Factors such as duration, synchronicity, velocity, complete closure, the time between blinks, and frequency over time are highly relevant. Such detailed analysis could help medical experts better understand the blinking process, its deviations, and possible treatments for better eye care.
Let's Get the FACS Straight -- Reconstructing Obstructed Facial Features
Nov 10, 2023



The human face is one of the most crucial parts in interhuman communication. Even when parts of the face are hidden or obstructed the underlying facial movements can be understood. Machine learning approaches often fail in that regard due to the complexity of the facial structures. To alleviate this problem a common approach is to fine-tune a model for such a specific application. However, this is computational intensive and might have to be repeated for each desired analysis task. In this paper, we propose to reconstruct obstructed facial parts to avoid the task of repeated fine-tuning. As a result, existing facial analysis methods can be used without further changes with respect to the data. In our approach, the restoration of facial features is interpreted as a style transfer task between different recording setups. By using the CycleGAN architecture the requirement of matched pairs, which is often hard to fullfill, can be eliminated. To proof the viability of our approach, we compare our reconstructions with real unobstructed recordings. We created a novel data set in which 36 test subjects were recorded both with and without 62 surface electromyography sensors attached to their faces. In our evaluation, we feature typical facial analysis tasks, like the computation of Facial Action Units and the detection of emotions. To further assess the quality of the restoration, we also compare perceptional distances. We can show, that scores similar to the videos without obstructing sensors can be achieved.