 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Subtokens: A Rich Character Embedding for Low-resource and Morphologically Complex Languages
Feb 24, 2026Tokenization and sub-tokenization based models like word2vec, BERT and the GPTs are the state-of-the-art in natural language processing. Typically, these approaches have limitations with respect to their input representation. They fail to fully capture orthographic similarities and morphological variations, especially in highly inflected and under-resource languages. To mitigate this problem, we propose to computes word vectors directly from character strings, integrating both semantic and syntactic information. We denote this transformer-based approach Rich Character Embeddings (RCE). Furthermore, we propose a hybrid model that combines transformer and convolutional mechanisms. Both vector representations can be used as a drop-in replacement for dictionary- and subtoken-based word embeddings in existing model architectures. It has the potential to improve performance for both large context-based language models like BERT and small models like word2vec for under-resourced and morphologically rich languages. We evaluate our approach on various tasks like the SWAG, declension prediction for inflected languages, metaphor and chiasmus detection for various languages. Our experiments show that it outperforms traditional token-based approaches on limited data using OddOneOut and TopK metrics.
Let's Get the FACS Straight -- Reconstructing Obstructed Facial Features
Nov 10, 2023



The human face is one of the most crucial parts in interhuman communication. Even when parts of the face are hidden or obstructed the underlying facial movements can be understood. Machine learning approaches often fail in that regard due to the complexity of the facial structures. To alleviate this problem a common approach is to fine-tune a model for such a specific application. However, this is computational intensive and might have to be repeated for each desired analysis task. In this paper, we propose to reconstruct obstructed facial parts to avoid the task of repeated fine-tuning. As a result, existing facial analysis methods can be used without further changes with respect to the data. In our approach, the restoration of facial features is interpreted as a style transfer task between different recording setups. By using the CycleGAN architecture the requirement of matched pairs, which is often hard to fullfill, can be eliminated. To proof the viability of our approach, we compare our reconstructions with real unobstructed recordings. We created a novel data set in which 36 test subjects were recorded both with and without 62 surface electromyography sensors attached to their faces. In our evaluation, we feature typical facial analysis tasks, like the computation of Facial Action Units and the detection of emotions. To further assess the quality of the restoration, we also compare perceptional distances. We can show, that scores similar to the videos without obstructing sensors can be achieved.
Facial Behavior Analysis using 4D Curvature Statistics for Presentation Attack Detection
Nov 05, 2019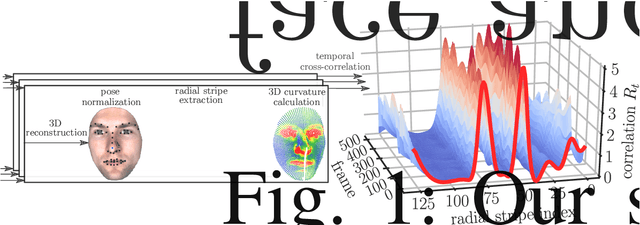


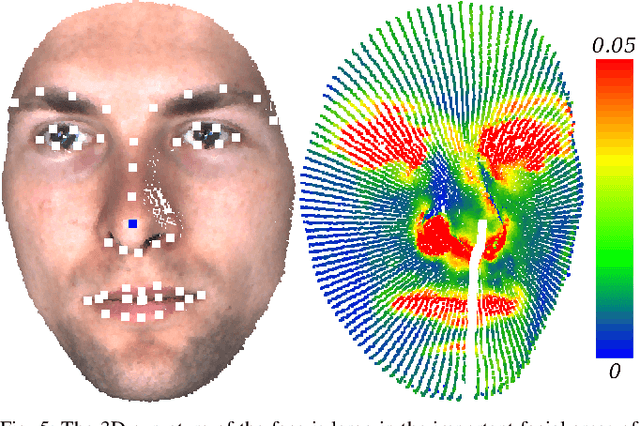
The uniqueness, complexity, and diversity of facial shapes and expressions led to success of facial biometric systems. Regardless of the accuracy of current facial recognition methods, most of them are vulnerable against the presentation of sophisticated masks. In the highly monitored application scenario at airports and banks, fraudsters probably do not wear masks. However, a deception will become more probable due to the increase of unsupervised authentication using kiosks, eGates and mobile phones in self-service. To robustly detect elastic 3D masks, one of the ultimate goals is to automatically analyze the plausibility of the facial behavior based on a sequence of 3D face scans. Most importantly, such a method would also detect all less advanced presentation attacks using static 3D masks, bent photographs with eyeholes, and replay attacks using monitors. Our proposed method achieves this goal by comparing the temporal curvature change between presentation attacks and genuine faces. For evaluation purposes, we recorded a challenging database containing replay attacks, static and elastic 3D masks using a high-quality 3D sensor. Based on the proposed representation, we found a clear separation between the low facial expressiveness of presentation attacks and the plausible behavior of genuine faces.
Neither Quick Nor Proper -- Evaluation of QuickProp for Learning Deep Neural Networks
Jun 15, 2016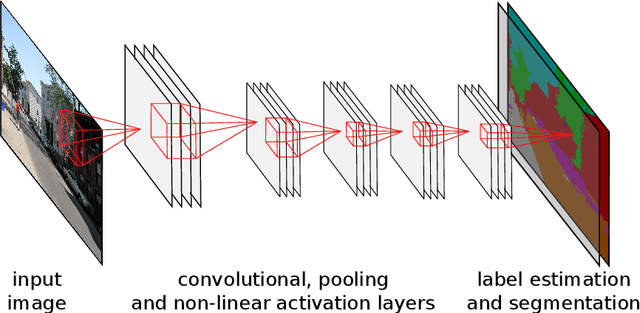

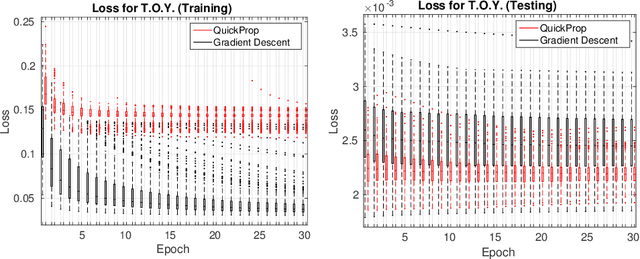
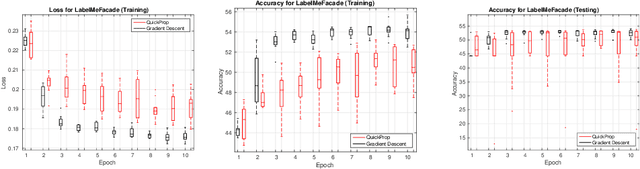
Neural networks and especially convolutional neural networks are of great interest in current computer vision research. However, many techniques, extensions, and modifications have been published in the past, which are not yet used by current approaches. In this paper, we study the application of a method called QuickProp for training of deep neural networks. In particular, we apply QuickProp during learning and testing of fully convolutional networks for the task of semantic segmentation. We compare QuickProp empirically with gradient descent, which is the current standard method. Experiments suggest that QuickProp can not compete with standard gradient descent techniques for complex computer vision tasks like semantic segmentation.
Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding
Feb 23, 2015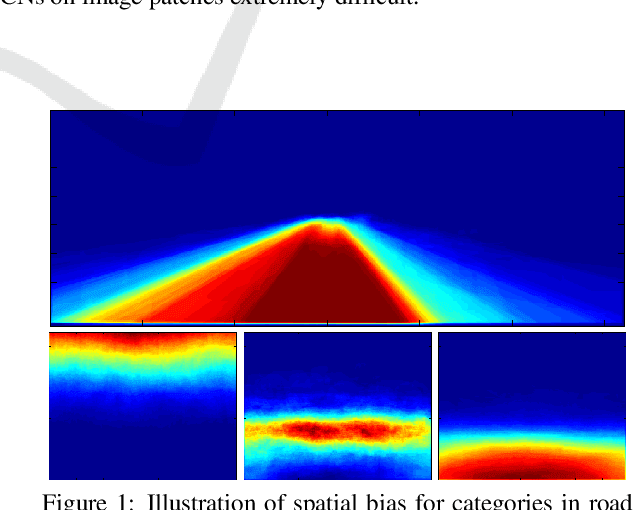
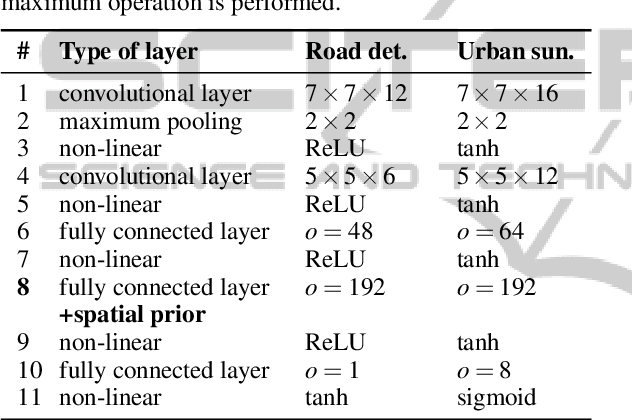
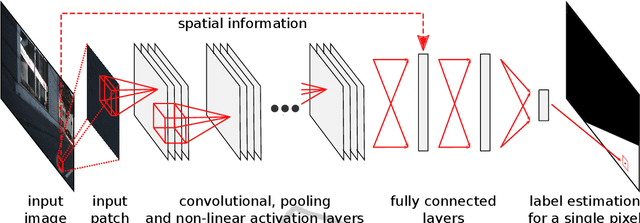
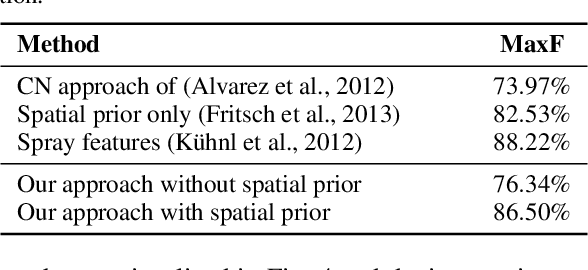
Classifying single image patches is important in many different applications, such as road detection or scene understanding. In this paper, we present convolutional patch networks, which are convolutional networks learned to distinguish different image patches and which can be used for pixel-wise labeling. We also show how to incorporate spatial information of the patch as an input to the network, which allows for learning spatial priors for certain categories jointly with an appearance model. In particular, we focus on road detection and urban scene understanding, two application areas where we are able to achieve state-of-the-art results on the KITTI as well as on the LabelMeFacade dataset. Furthermore, our paper offers a guideline for people working in the area and desperately wandering through all the painstaking details that render training CNs on image patches extremely difficult.