 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHer2 Challenge Contest: A Detailed Assessment of Automated Her2 Scoring Algorithms in Whole Slide Images of Breast Cancer Tissues
Jul 24, 2017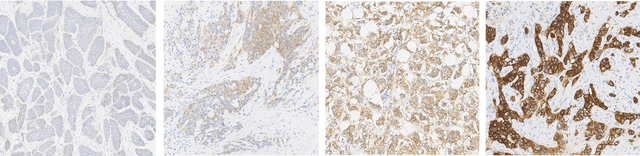

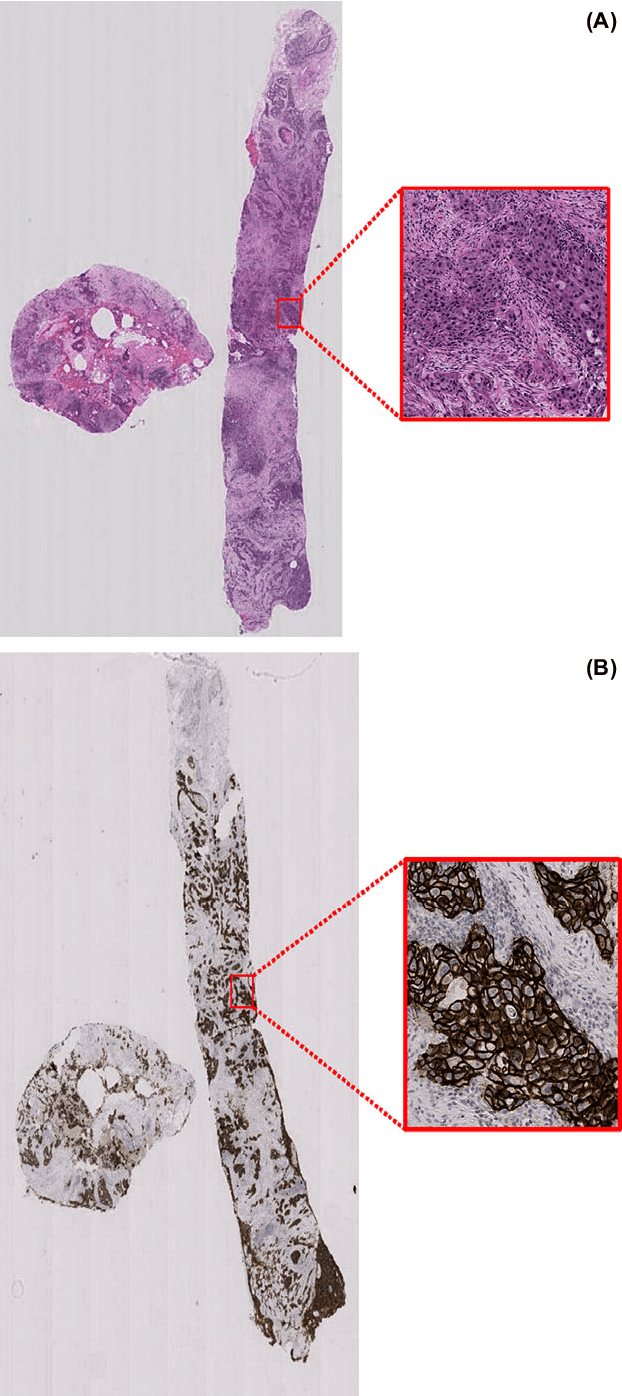
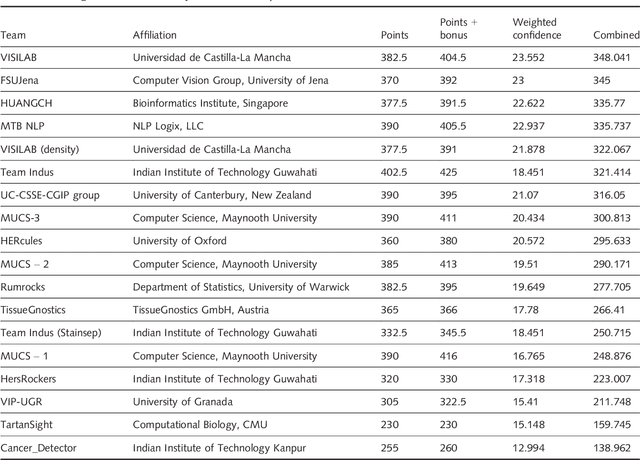
Evaluating expression of the Human epidermal growth factor receptor 2 (Her2) by visual examination of immunohistochemistry (IHC) on invasive breast cancer (BCa) is a key part of the diagnostic assessment of BCa due to its recognised importance as a predictive and prognostic marker in clinical practice. However, visual scoring of Her2 is subjective and consequently prone to inter-observer variability. Given the prognostic and therapeutic implications of Her2 scoring, a more objective method is required. In this paper, we report on a recent automated Her2 scoring contest, held in conjunction with the annual PathSoc meeting held in Nottingham in June 2016, aimed at systematically comparing and advancing the state-of-the-art Artificial Intelligence (AI) based automated methods for Her2 scoring. The contest dataset comprised of digitised whole slide images (WSI) of sections from 86 cases of invasive breast carcinoma stained with both Haematoxylin & Eosin (H&E) and IHC for Her2. The contesting algorithms automatically predicted scores of the IHC slides for an unseen subset of the dataset and the predicted scores were compared with the 'ground truth' (a consensus score from at least two experts). We also report on a simple Man vs Machine contest for the scoring of Her2 and show that the automated methods could beat the pathology experts on this contest dataset. This paper presents a benchmark for comparing the performance of automated algorithms for scoring of Her2. It also demonstrates the enormous potential of automated algorithms in assisting the pathologist with objective IHC scoring.
Generalized orderless pooling performs implicit salient matching
Jul 20, 2017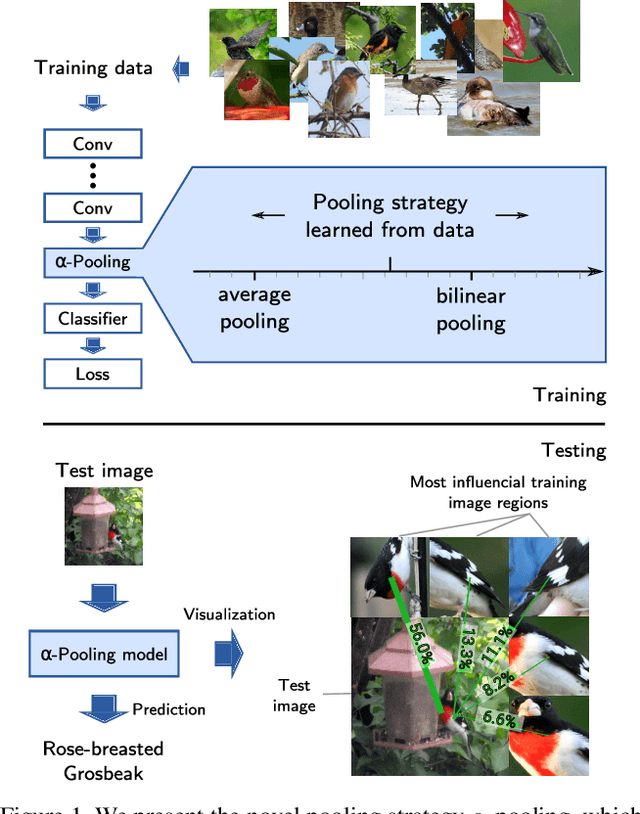
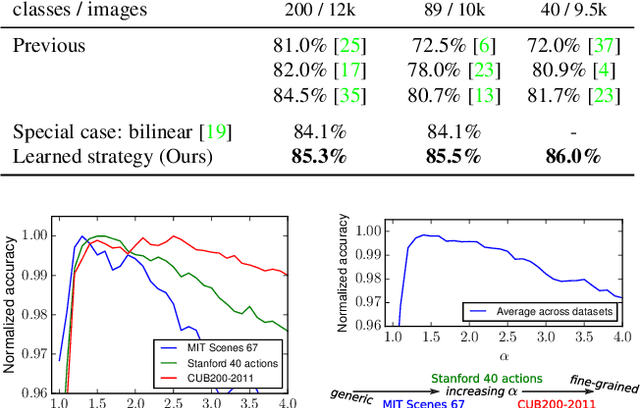

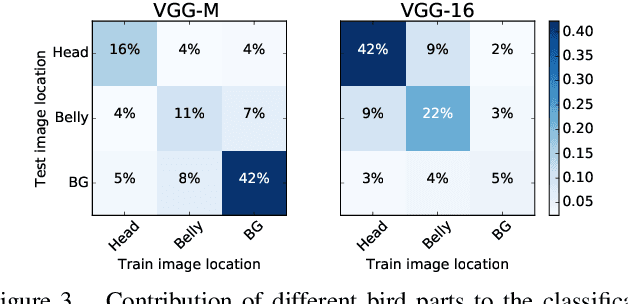
Most recent CNN architectures use average pooling as a final feature encoding step. In the field of fine-grained recognition, however, recent global representations like bilinear pooling offer improved performance. In this paper, we generalize average and bilinear pooling to "alpha-pooling", allowing for learning the pooling strategy during training. In addition, we present a novel way to visualize decisions made by these approaches. We identify parts of training images having the highest influence on the prediction of a given test image. It allows for justifying decisions to users and also for analyzing the influence of semantic parts. For example, we can show that the higher capacity VGG16 model focuses much more on the bird's head than, e.g., the lower-capacity VGG-M model when recognizing fine-grained bird categories. Both contributions allow us to analyze the difference when moving between average and bilinear pooling. In addition, experiments show that our generalized approach can outperform both across a variety of standard datasets.
ImageNet pre-trained models with batch normalization
Dec 06, 2016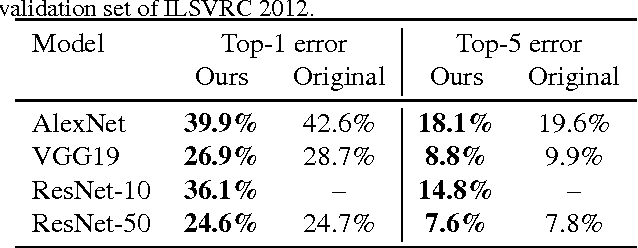
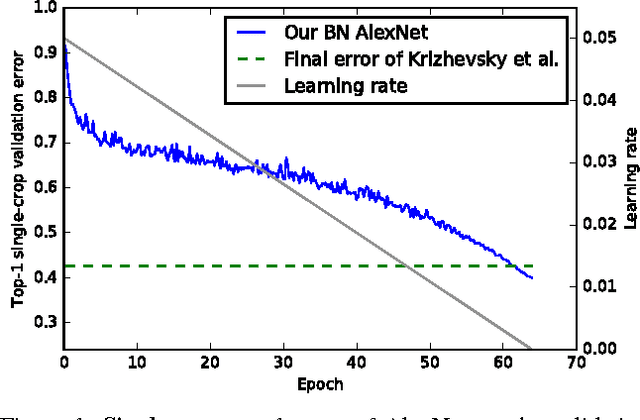
Convolutional neural networks (CNN) pre-trained on ImageNet are the backbone of most state-of-the-art approaches. In this paper, we present a new set of pre-trained models with popular state-of-the-art architectures for the Caffe framework. The first release includes Residual Networks (ResNets) with generation script as well as the batch-normalization-variants of AlexNet and VGG19. All models outperform previous models with the same architecture. The models and training code are available at http://www.inf-cv.uni-jena.de/Research/CNN+Models.html and https://github.com/cvjena/cnn-models
Fine-grained Recognition in the Noisy Wild: Sensitivity Analysis of Convolutional Neural Networks Approaches
Oct 21, 2016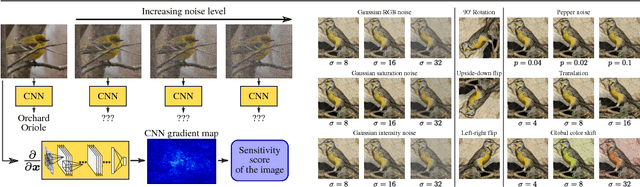
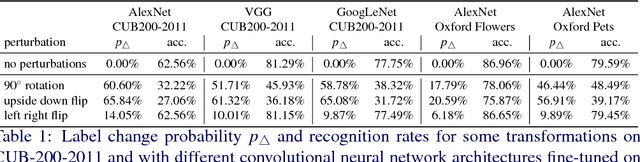
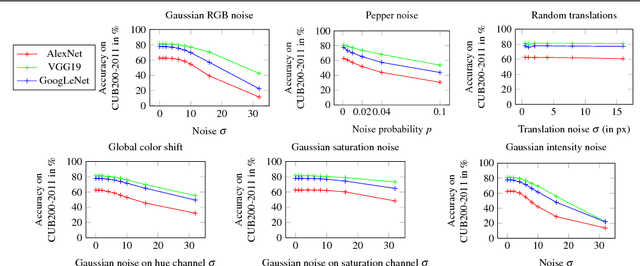
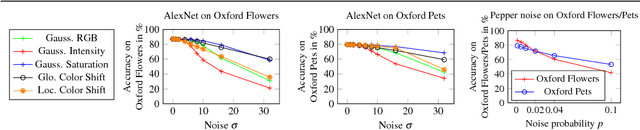
In this paper, we study the sensitivity of CNN outputs with respect to image transformations and noise in the area of fine-grained recognition. In particular, we answer the following questions (1) how sensitive are CNNs with respect to image transformations encountered during wild image capture?; (2) how can we predict CNN sensitivity?; and (3) can we increase the robustness of CNNs with respect to image degradations? To answer the first question, we provide an extensive empirical sensitivity analysis of commonly used CNN architectures (AlexNet, VGG19, GoogleNet) across various types of image degradations. This allows for predicting CNN performance for new domains comprised by images of lower quality or captured from a different viewpoint. We also show how the sensitivity of CNN outputs can be predicted for single images. Furthermore, we demonstrate that input layer dropout or pre-filtering during test time only reduces CNN sensitivity for high levels of degradation. Experiments for fine-grained recognition tasks reveal that VGG19 is more robust to severe image degradations than AlexNet and GoogleNet. However, small intensity noise can lead to dramatic changes in CNN performance even for VGG19.
Neither Quick Nor Proper -- Evaluation of QuickProp for Learning Deep Neural Networks
Jun 15, 2016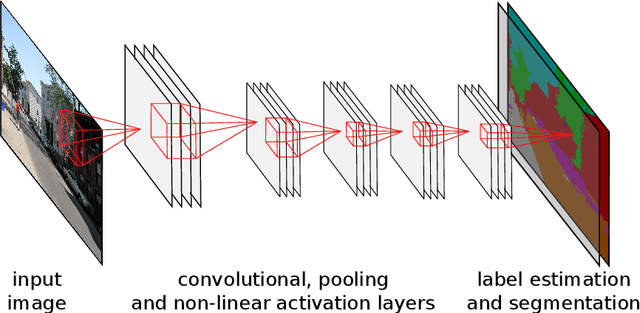

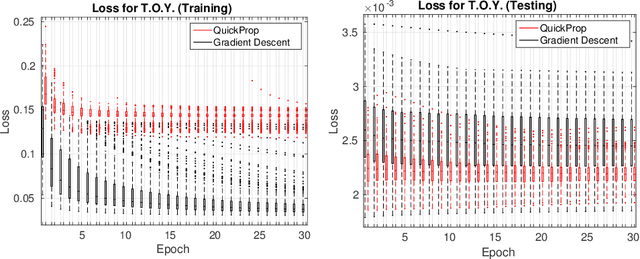
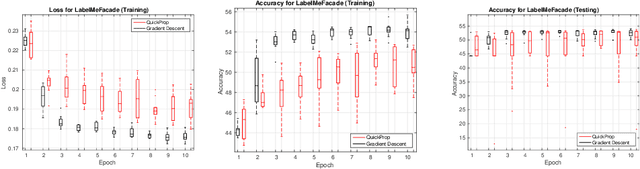
Neural networks and especially convolutional neural networks are of great interest in current computer vision research. However, many techniques, extensions, and modifications have been published in the past, which are not yet used by current approaches. In this paper, we study the application of a method called QuickProp for training of deep neural networks. In particular, we apply QuickProp during learning and testing of fully convolutional networks for the task of semantic segmentation. We compare QuickProp empirically with gradient descent, which is the current standard method. Experiments suggest that QuickProp can not compete with standard gradient descent techniques for complex computer vision tasks like semantic segmentation.
Neural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks
Dec 05, 2015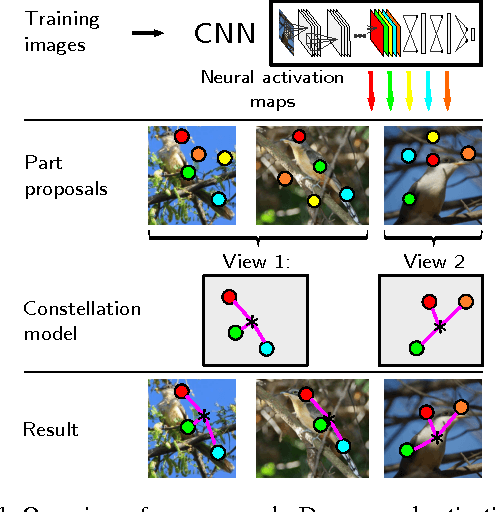

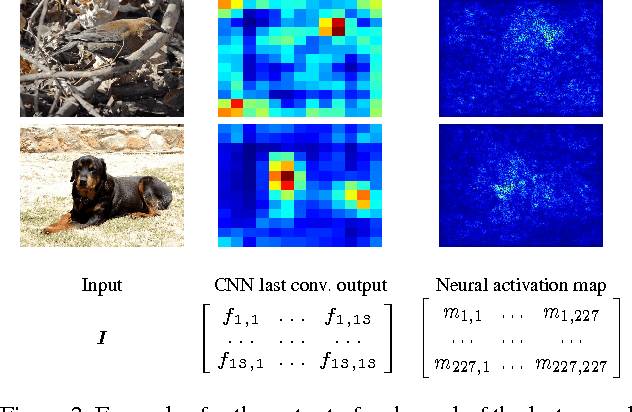
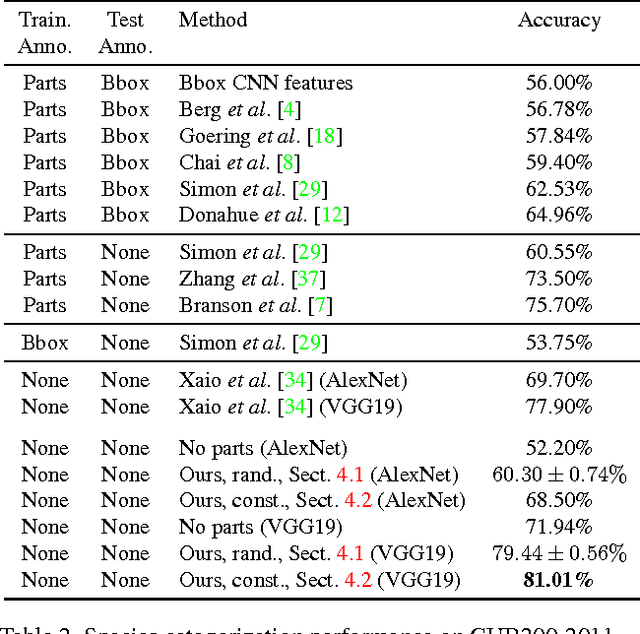
Part models of object categories are essential for challenging recognition tasks, where differences in categories are subtle and only reflected in appearances of small parts of the object. We present an approach that is able to learn part models in a completely unsupervised manner, without part annotations and even without given bounding boxes during learning. The key idea is to find constellations of neural activation patterns computed using convolutional neural networks. In our experiments, we outperform existing approaches for fine-grained recognition on the CUB200-2011, NA birds, Oxford PETS, and Oxford Flowers dataset in case no part or bounding box annotations are available and achieve state-of-the-art performance for the Stanford Dog dataset. We also show the benefits of neural constellation models as a data augmentation technique for fine-tuning. Furthermore, our paper unites the areas of generic and fine-grained classification, since our approach is suitable for both scenarios. The source code of our method is available online at http://www.inf-cv.uni-jena.de/part_discovery
Fine-grained Recognition Datasets for Biodiversity Analysis
Jul 03, 2015


In the following paper, we present and discuss challenging applications for fine-grained visual classification (FGVC): biodiversity and species analysis. We not only give details about two challenging new datasets suitable for computer vision research with up to 675 highly similar classes, but also present first results with localized features using convolutional neural networks (CNN). We conclude with a list of challenging new research directions in the area of visual classification for biodiversity research.
Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding
Feb 23, 2015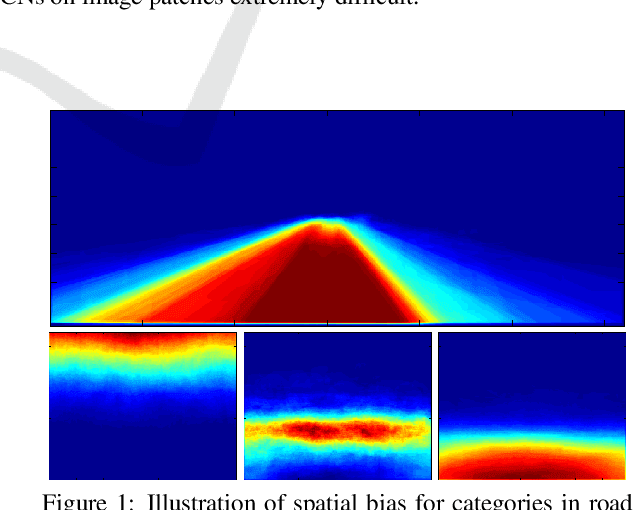
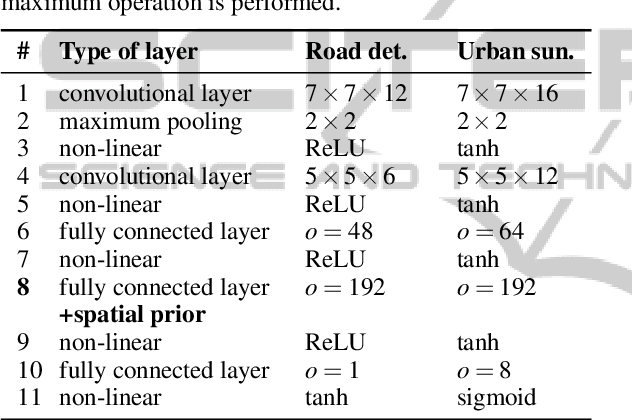
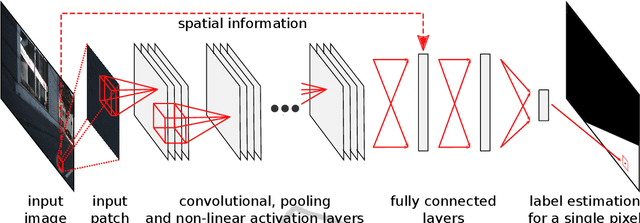
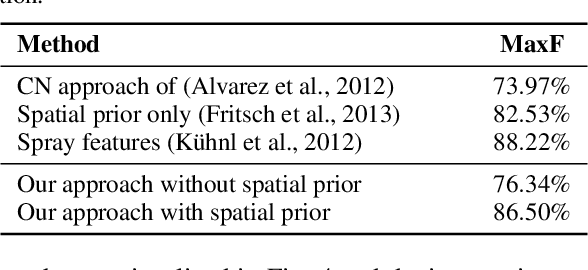
Classifying single image patches is important in many different applications, such as road detection or scene understanding. In this paper, we present convolutional patch networks, which are convolutional networks learned to distinguish different image patches and which can be used for pixel-wise labeling. We also show how to incorporate spatial information of the patch as an input to the network, which allows for learning spatial priors for certain categories jointly with an appearance model. In particular, we focus on road detection and urban scene understanding, two application areas where we are able to achieve state-of-the-art results on the KITTI as well as on the LabelMeFacade dataset. Furthermore, our paper offers a guideline for people working in the area and desperately wandering through all the painstaking details that render training CNs on image patches extremely difficult.
Part Detector Discovery in Deep Convolutional Neural Networks
Nov 14, 2014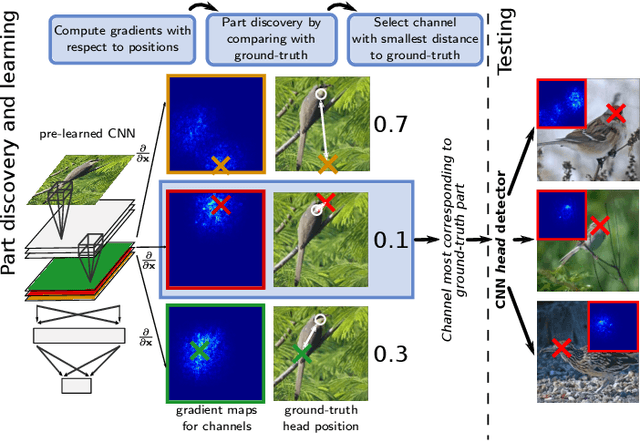
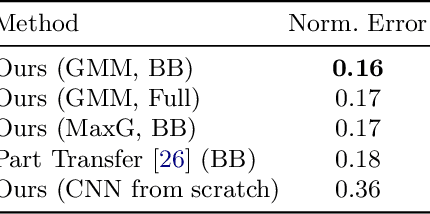

Current fine-grained classification approaches often rely on a robust localization of object parts to extract localized feature representations suitable for discrimination. However, part localization is a challenging task due to the large variation of appearance and pose. In this paper, we show how pre-trained convolutional neural networks can be used for robust and efficient object part discovery and localization without the necessity to actually train the network on the current dataset. Our approach called "part detector discovery" (PDD) is based on analyzing the gradient maps of the network outputs and finding activation centers spatially related to annotated semantic parts or bounding boxes. This allows us not just to obtain excellent performance on the CUB200-2011 dataset, but in contrast to previous approaches also to perform detection and bird classification jointly without requiring a given bounding box annotation during testing and ground-truth parts during training. The code is available at http://www.inf-cv.uni-jena.de/part_discovery and https://github.com/cvjena/PartDetectorDisovery.