 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeFaPaTo -- A joint toolbox for blinking analysis and facial features extraction
Feb 13, 2024Analyzing facial features and expressions is a complex task in computer vision. The human face is intricate, with significant shape, texture, and appearance variations. In medical contexts, facial structures that differ from the norm, such as those affected by paralysis, are particularly important to study and require precise analysis. One area of interest is the subtle movements involved in blinking, a process that is not yet fully understood and needs high-resolution, time-specific analysis for detailed understanding. However, a significant challenge is that many advanced computer vision techniques demand programming skills, making them less accessible to medical professionals who may not have these skills. The Jena Facial Palsy Toolbox (JeFaPaTo) has been developed to bridge this gap. It utilizes cutting-edge computer vision algorithms and offers a user-friendly interface for those without programming expertise. This toolbox is designed to make advanced facial analysis more accessible to medical experts, simplifying integration into their workflow. The state of the eye closure is of high interest to medical experts, e.g., in the context of facial palsy or Parkinson's disease. Due to facial nerve damage, the eye-closing process might be impaired and could lead to many undesirable side effects. Hence, more than a simple distinction between open and closed eyes is required for a detailed analysis. Factors such as duration, synchronicity, velocity, complete closure, the time between blinks, and frequency over time are highly relevant. Such detailed analysis could help medical experts better understand the blinking process, its deviations, and possible treatments for better eye care.
Self-supervised Data Bootstrapping for Deep Optical Character Recognition of Identity Documents
Aug 12, 2019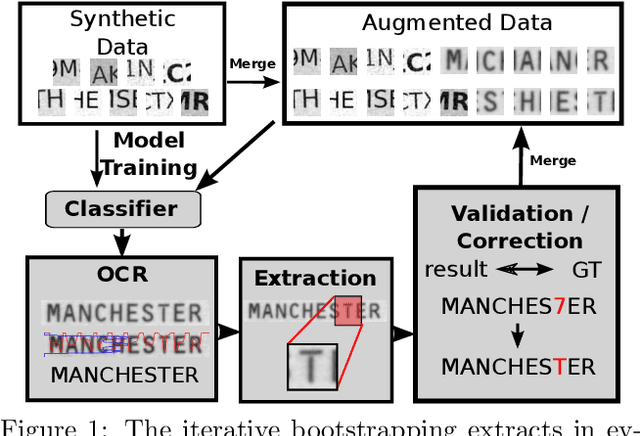

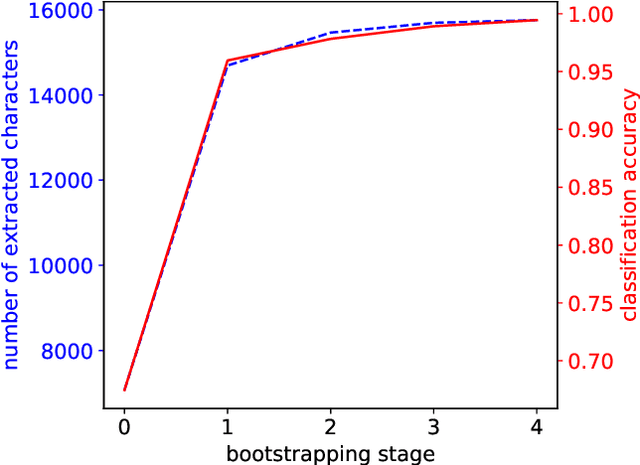
The essential task of verifying person identities at airports and national borders is very time consuming. To accelerate it, optical character recognition for identity documents (IDs) using dictionaries is not appropriate due to high variability of the text content in IDs, e.g., individual street names or surnames. Additionally, no properties of the used fonts in IDs are known. Therefore, we propose an iterative self-supervised bootstrapping approach using a smart strategy to mine real character data from IDs. In combination with synthetically generated character data, the real data is used to train efficient convolutional neural networks for character classification serving a practical runtime as well as a high accuracy. On a dataset with 74 character classes, we achieve an average class-wise accuracy of 99.4 %. In contrast, if we would apply a classifier trained only using synthetic data, the accuracy is reduced to 58.1 %. Finally, we show that our whole proposed pipeline outperforms an established open-source framework