 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Data Bootstrapping for Deep Optical Character Recognition of Identity Documents
Paper and Code
Aug 12, 2019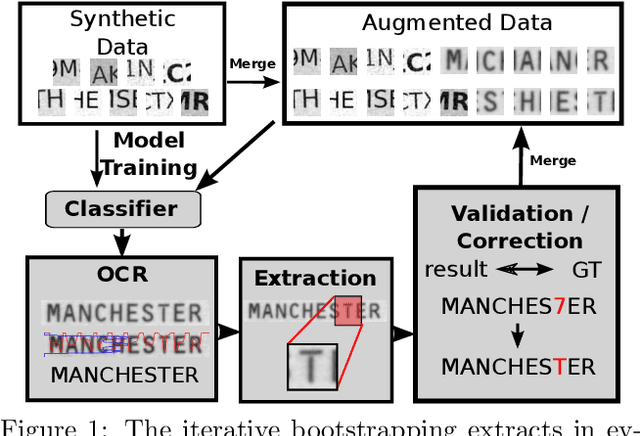

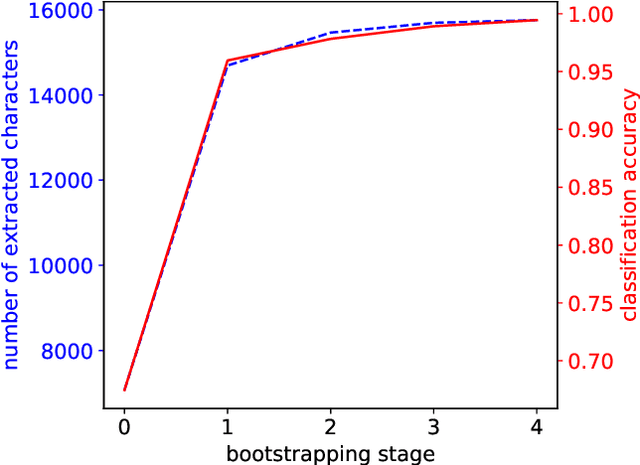
The essential task of verifying person identities at airports and national borders is very time consuming. To accelerate it, optical character recognition for identity documents (IDs) using dictionaries is not appropriate due to high variability of the text content in IDs, e.g., individual street names or surnames. Additionally, no properties of the used fonts in IDs are known. Therefore, we propose an iterative self-supervised bootstrapping approach using a smart strategy to mine real character data from IDs. In combination with synthetically generated character data, the real data is used to train efficient convolutional neural networks for character classification serving a practical runtime as well as a high accuracy. On a dataset with 74 character classes, we achieve an average class-wise accuracy of 99.4 %. In contrast, if we would apply a classifier trained only using synthetic data, the accuracy is reduced to 58.1 %. Finally, we show that our whole proposed pipeline outperforms an established open-source framework