 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous Agreement: How to find the Ideal Number of Anomaly Classes in Correlated, Multivariate Time Series Data
Jan 13, 2025
Detecting and classifying abnormal system states is critical for condition monitoring, but supervised methods often fall short due to the rarity of anomalies and the lack of labeled data. Therefore, clustering is often used to group similar abnormal behavior. However, evaluating cluster quality without ground truth is challenging, as existing measures such as the Silhouette Score (SSC) only evaluate the cohesion and separation of clusters and ignore possible prior knowledge about the data. To address this challenge, we introduce the Synchronized Anomaly Agreement Index (SAAI), which exploits the synchronicity of anomalies across multivariate time series to assess cluster quality. We demonstrate the effectiveness of SAAI by showing that maximizing SAAI improves accuracy on the task of finding the true number of anomaly classes K in correlated time series by 0.23 compared to SSC and by 0.32 compared to X-Means. We also show that clusters obtained by maximizing SAAI are easier to interpret compared to SSC.
Unraveling Anomalies in Time: Unsupervised Discovery and Isolation of Anomalous Behavior in Bio-regenerative Life Support System Telemetry
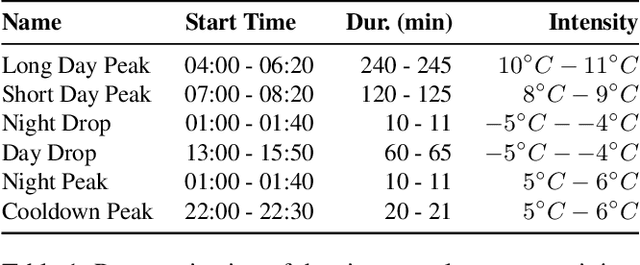
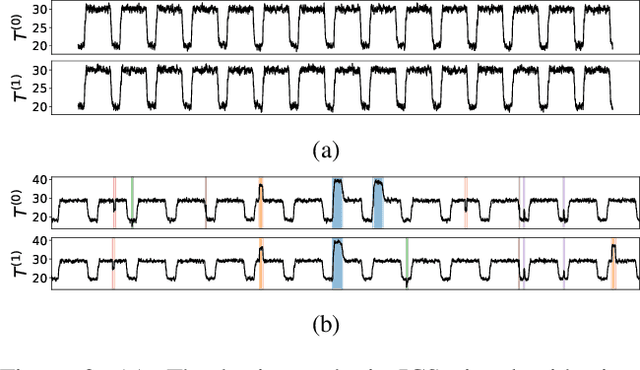
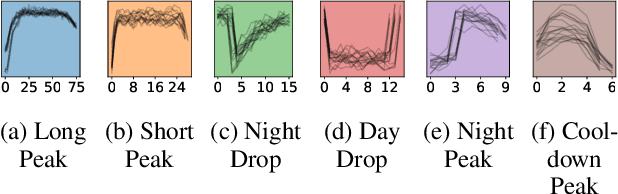
Jun 14, 2024The detection of abnormal or critical system states is essential in condition monitoring. While much attention is given to promptly identifying anomalies, a retrospective analysis of these anomalies can significantly enhance our comprehension of the underlying causes of observed undesired behavior. This aspect becomes particularly critical when the monitored system is deployed in a vital environment. In this study, we delve into anomalies within the domain of Bio-Regenerative Life Support Systems (BLSS) for space exploration and analyze anomalies found in telemetry data stemming from the EDEN ISS space greenhouse in Antarctica. We employ time series clustering on anomaly detection results to categorize various types of anomalies in both uni- and multivariate settings. We then assess the effectiveness of these methods in identifying systematic anomalous behavior. Additionally, we illustrate that the anomaly detection methods MDI and DAMP produce complementary results, as previously indicated by research.
Is it worth it? An experimental comparison of six deep- and classical machine learning methods for unsupervised anomaly detection in time series
Dec 21, 2022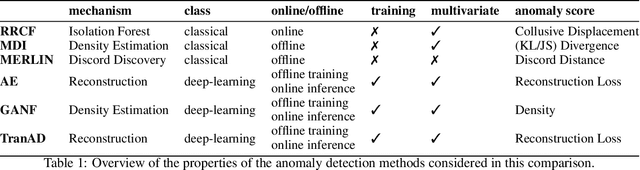
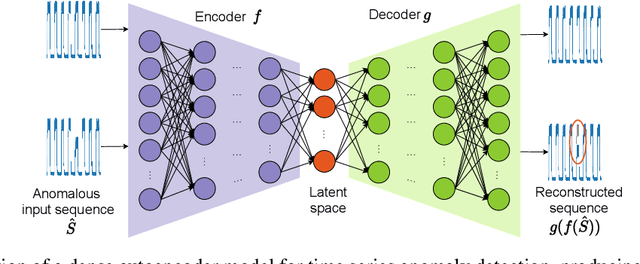
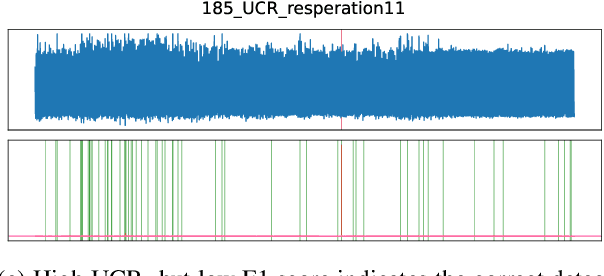
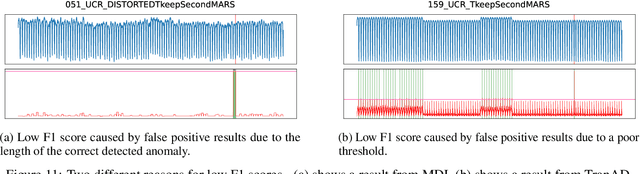
The detection of anomalies in time series data is crucial in a wide range of applications, such as system monitoring, health care or cyber security. While the vast number of available methods makes selecting the right method for a certain application hard enough, different methods have different strengths, e.g. regarding the type of anomalies they are able to find. In this work, we compare six unsupervised anomaly detection methods with different complexities to answer the questions: Are the more complex methods usually performing better? And are there specific anomaly types that those method are tailored to? The comparison is done on the UCR anomaly archive, a recent benchmark dataset for anomaly detection. We compare the six methods by analyzing the experimental results on a dataset- and anomaly type level after tuning the necessary hyperparameter for each method. Additionally we examine the ability of individual methods to incorporate prior knowledge about the anomalies and analyse the differences of point-wise and sequence wise features. We show with broad experiments, that the classical machine learning methods show a superior performance compared to the deep learning methods across a wide range of anomaly types.