 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it worth it? An experimental comparison of six deep- and classical machine learning methods for unsupervised anomaly detection in time series
Paper and Code
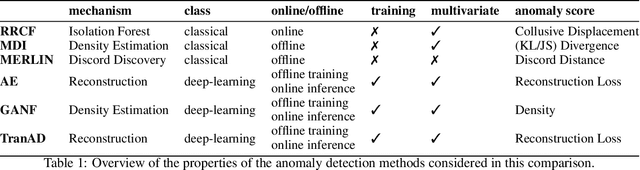
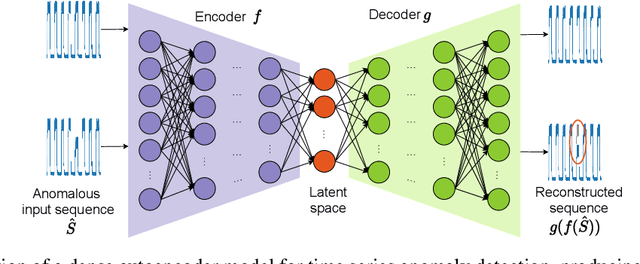
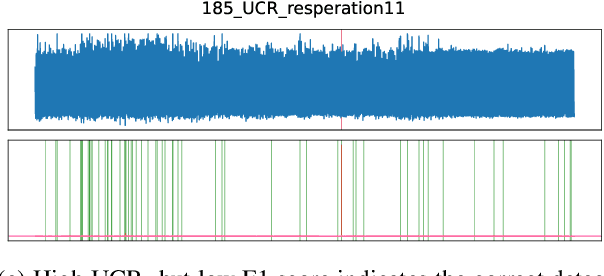
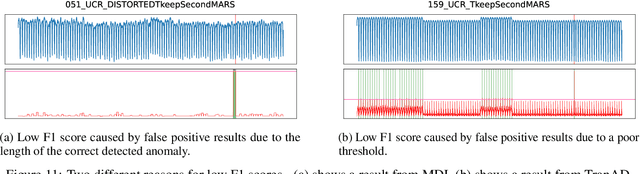
The detection of anomalies in time series data is crucial in a wide range of applications, such as system monitoring, health care or cyber security. While the vast number of available methods makes selecting the right method for a certain application hard enough, different methods have different strengths, e.g. regarding the type of anomalies they are able to find. In this work, we compare six unsupervised anomaly detection methods with different complexities to answer the questions: Are the more complex methods usually performing better? And are there specific anomaly types that those method are tailored to? The comparison is done on the UCR anomaly archive, a recent benchmark dataset for anomaly detection. We compare the six methods by analyzing the experimental results on a dataset- and anomaly type level after tuning the necessary hyperparameter for each method. Additionally we examine the ability of individual methods to incorporate prior knowledge about the anomalies and analyse the differences of point-wise and sequence wise features. We show with broad experiments, that the classical machine learning methods show a superior performance compared to the deep learning methods across a wide range of anomaly types.