 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Relevant Flood Images on Twitter using Content-based Filters
Nov 11, 2020
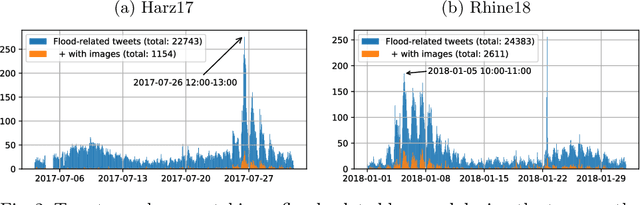
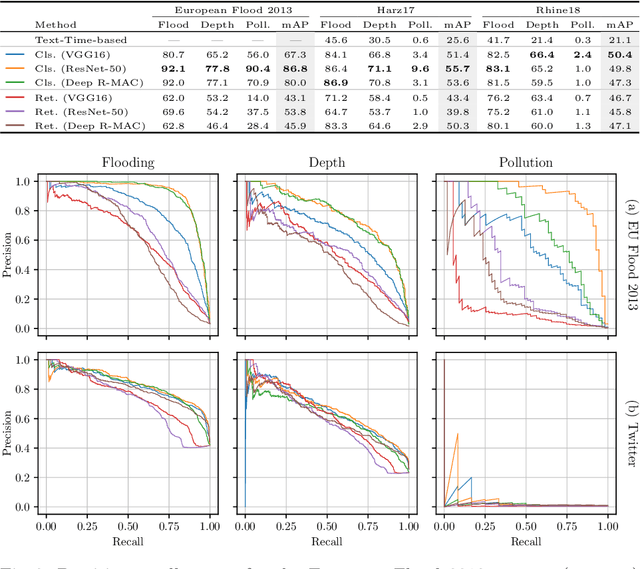
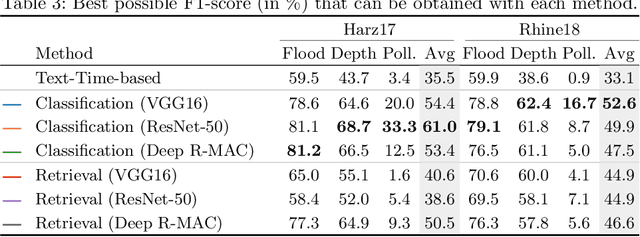
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to coarsely distributed sensors or sensor failures. At the same time, a plethora of information is buried in an abundance of images of the event posted on social media platforms such as Twitter. These images could be used to document and rapidly assess the situation and derive proxy-data not available from sensors, e.g., the degree of water pollution. However, not all images posted online are suitable or informative enough for this purpose. Therefore, we propose an automatic filtering approach using machine learning techniques for finding Twitter images that are relevant for one of the following information objectives: assessing the flooded area, the inundation depth, and the degree of water pollution. Instead of relying on textual information present in the tweet, the filter analyzes the image contents directly. We evaluate the performance of two different approaches and various features on a case-study of two major flooding events. Our image-based filter is able to enhance the quality of the results substantially compared with a keyword-based filter, improving the mean average precision from 23% to 53% on average.
Enhancing Flood Impact Analysis using Interactive Retrieval of Social Media Images
Aug 09, 2019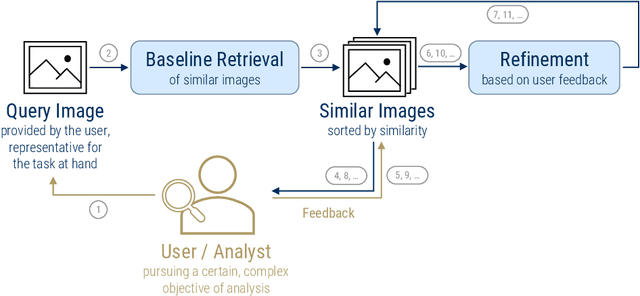
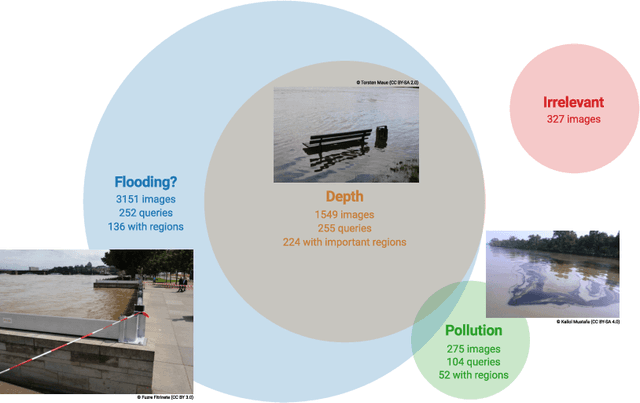

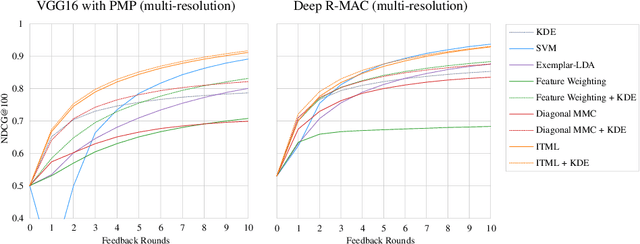
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to a coarse distribution of sensors or sensor failures. This limitation could be alleviated by leveraging information contained in images of the event posted on social media platforms, so-called "Volunteered Geographic Information (VGI)". To save the analyst from the need to inspect all images posted online manually, we propose to use content-based image retrieval with the possibility of relevance feedback for retrieving only relevant images of the event to be analyzed. To evaluate this approach, we introduce a new dataset of 3,710 flood images, annotated by domain experts regarding their relevance with respect to three tasks (determining the flooded area, inundation depth, water pollution). We compare several image features and relevance feedback methods on that dataset, mixed with 97,085 distractor images, and are able to improve the precision among the top 100 retrieval results from 55% with the baseline retrieval to 87% after 5 rounds of feedback.