 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive and Incremental Learning with Weak Supervision
Jan 20, 2020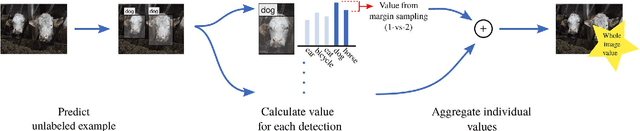
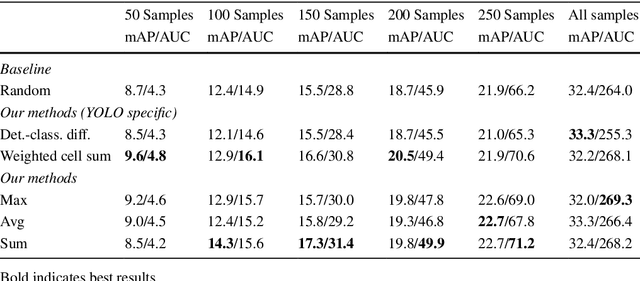

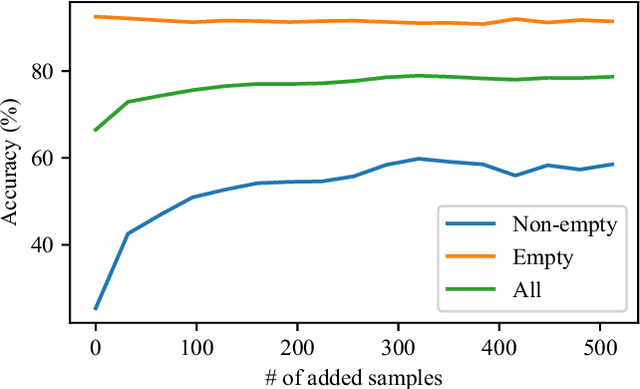
Large amounts of labeled training data are one of the main contributors to the great success that deep models have achieved in the past. Label acquisition for tasks other than benchmarks can pose a challenge due to requirements of both funding and expertise. By selecting unlabeled examples that are promising in terms of model improvement and only asking for respective labels, active learning can increase the efficiency of the labeling process in terms of time and cost. In this work, we describe combinations of an incremental learning scheme and methods of active learning. These allow for continuous exploration of newly observed unlabeled data. We describe selection criteria based on model uncertainty as well as expected model output change (EMOC). An object detection task is evaluated in a continuous exploration context on the PASCAL VOC dataset. We also validate a weakly supervised system based on active and incremental learning in a real-world biodiversity application where images from camera traps are analyzed. Labeling only 32 images by accepting or rejecting proposals generated by our method yields an increase in accuracy from 25.4% to 42.6%.
Active Learning for Deep Object Detection
Sep 26, 2018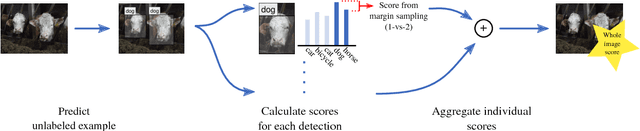
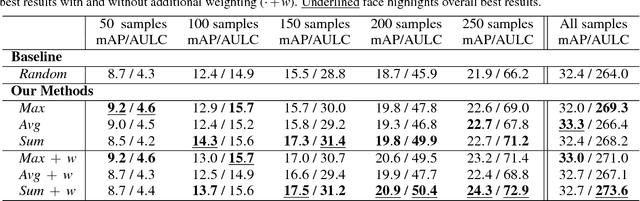
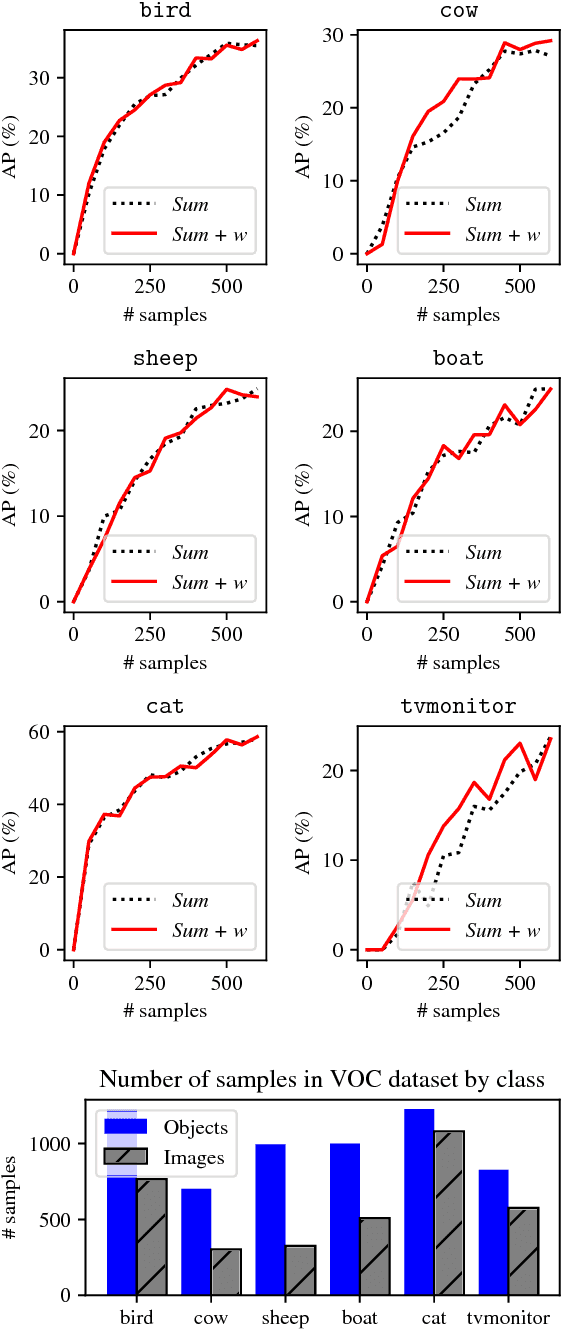

The great success that deep models have achieved in the past is mainly owed to large amounts of labeled training data. However, the acquisition of labeled data for new tasks aside from existing benchmarks is both challenging and costly. Active learning can make the process of labeling new data more efficient by selecting unlabeled samples which, when labeled, are expected to improve the model the most. In this paper, we combine a novel method of active learning for object detection with an incremental learning scheme to enable continuous exploration of new unlabeled datasets. We propose a set of uncertainty-based active learning metrics suitable for most object detectors. Furthermore, we present an approach to leverage class imbalances during sample selection. All methods are evaluated systematically in a continuous exploration context on the PASCAL VOC 2012 dataset.
Information-Theoretic Active Learning for Content-Based Image Retrieval
Sep 07, 2018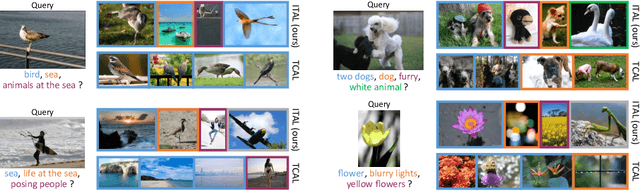
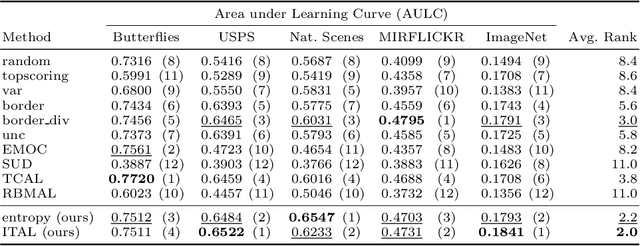
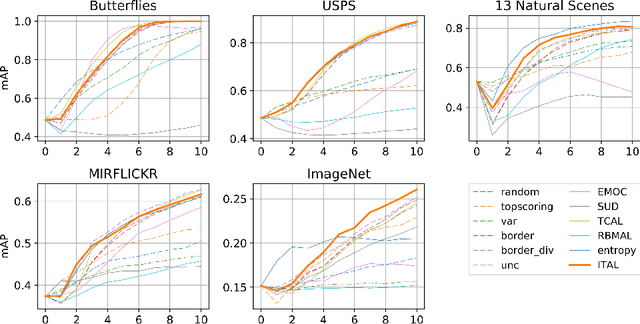
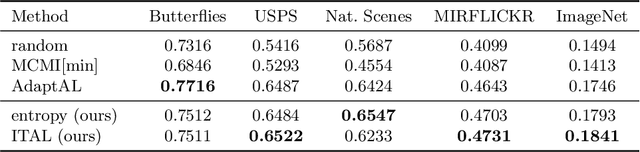
We propose Information-Theoretic Active Learning (ITAL), a novel batch-mode active learning method for binary classification, and apply it for acquiring meaningful user feedback in the context of content-based image retrieval. Instead of combining different heuristics such as uncertainty, diversity, or density, our method is based on maximizing the mutual information between the predicted relevance of the images and the expected user feedback regarding the selected batch. We propose suitable approximations to this computationally demanding problem and also integrate an explicit model of user behavior that accounts for possible incorrect labels and unnameable instances. Furthermore, our approach does not only take the structure of the data but also the expected model output change caused by the user feedback into account. In contrast to other methods, ITAL turns out to be highly flexible and provides state-of-the-art performance across various datasets, such as MIRFLICKR and ImageNet.
Fast Learning and Prediction for Object Detection using Whitened CNN Features
Apr 12, 2017

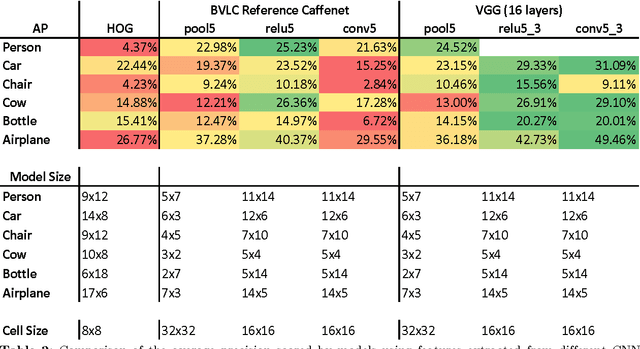
We combine features extracted from pre-trained convolutional neural networks (CNNs) with the fast, linear Exemplar-LDA classifier to get the advantages of both: the high detection performance of CNNs, automatic feature engineering, fast model learning from few training samples and efficient sliding-window detection. The Adaptive Real-Time Object Detection System (ARTOS) has been refactored broadly to be used in combination with Caffe for the experimental studies reported in this work.
Active and Continuous Exploration with Deep Neural Networks and Expected Model Output Changes
Dec 19, 2016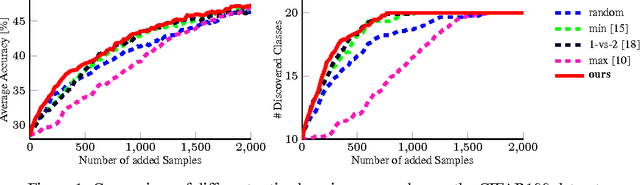
The demands on visual recognition systems do not end with the complexity offered by current large-scale image datasets, such as ImageNet. In consequence, we need curious and continuously learning algorithms that actively acquire knowledge about semantic concepts which are present in available unlabeled data. As a step towards this goal, we show how to perform continuous active learning and exploration, where an algorithm actively selects relevant batches of unlabeled examples for annotation. These examples could either belong to already known or to yet undiscovered classes. Our algorithm is based on a new generalization of the Expected Model Output Change principle for deep architectures and is especially tailored to deep neural networks. Furthermore, we show easy-to-implement approximations that yield efficient techniques for active selection. Empirical experiments show that our method outperforms currently used heuristics.