 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEST: A robust attention formulation using query-modulated spherical attention
Mar 31, 2026The Transformer model architecture has become one of the most widely used in deep learning and the attention mechanism is at its core. The standard attention formulation uses a softmax operation applied to a scaled dot product between query and key vectors. We explore the role played by norms of the queries and keys, which can cause training instabilities when they arbitrarily increase. We demonstrate how this can happen even in simple Transformer models, in the presence of easy-to-learn spurious patterns in the data. We propose a new attention formulation, QUEry-modulated Spherical aTtention (QUEST), that constrains the keys to a hyperspherical latent space, while still allowing individual tokens to flexibly control the sharpness of the attention distribution. QUEST can be easily used as a drop-in replacement for standard attention. We focus on vision applications while also exploring other domains to highlight the method's generality. We show that (1) QUEST trains without instabilities and (2) produces models with improved performance (3) that are robust to data corruptions and adversarial attacks.
Understanding Ice Crystal Habit Diversity with Self-Supervised Learning
Sep 09, 2025Ice-containing clouds strongly impact climate, but they are hard to model due to ice crystal habit (i.e., shape) diversity. We use self-supervised learning (SSL) to learn latent representations of crystals from ice crystal imagery. By pre-training a vision transformer with many cloud particle images, we learn robust representations of crystal morphology, which can be used for various science-driven tasks. Our key contributions include (1) validating that our SSL approach can be used to learn meaningful representations, and (2) presenting a relevant application where we quantify ice crystal diversity with these latent representations. Our results demonstrate the power of SSL-driven representations to improve the characterization of ice crystals and subsequently constrain their role in Earth's climate system.
CleverDistiller: Simple and Spatially Consistent Cross-modal Distillation
Mar 12, 2025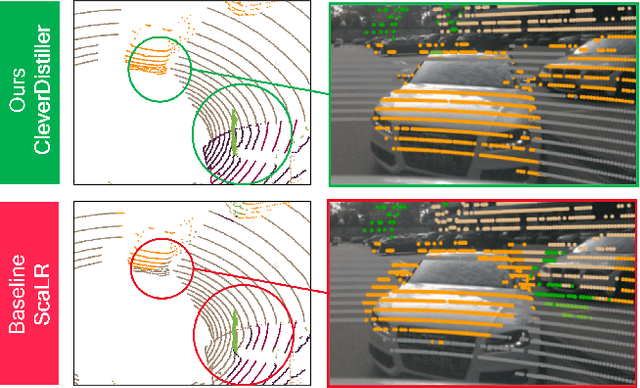
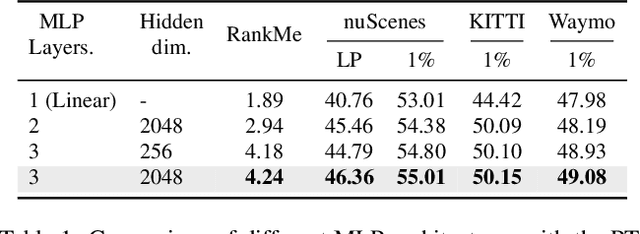
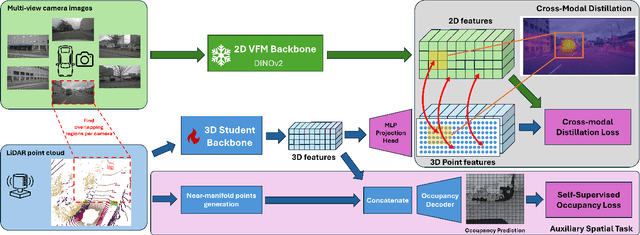
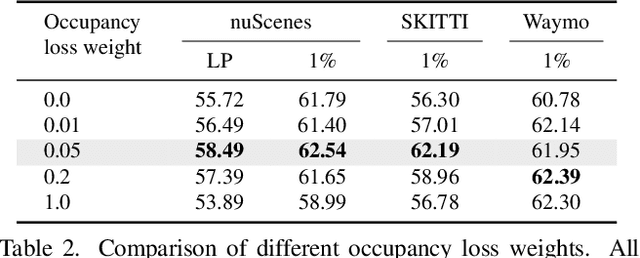
Vision foundation models (VFMs) such as DINO have led to a paradigm shift in 2D camera-based perception towards extracting generalized features to support many downstream tasks. Recent works introduce self-supervised cross-modal knowledge distillation (KD) as a way to transfer these powerful generalization capabilities into 3D LiDAR-based models. However, they either rely on highly complex distillation losses, pseudo-semantic maps, or limit KD to features useful for semantic segmentation only. In this work, we propose CleverDistiller, a self-supervised, cross-modal 2D-to-3D KD framework introducing a set of simple yet effective design choices: Unlike contrastive approaches relying on complex loss design choices, our method employs a direct feature similarity loss in combination with a multi layer perceptron (MLP) projection head to allow the 3D network to learn complex semantic dependencies throughout the projection. Crucially, our approach does not depend on pseudo-semantic maps, allowing for direct knowledge transfer from a VFM without explicit semantic supervision. Additionally, we introduce the auxiliary self-supervised spatial task of occupancy prediction to enhance the semantic knowledge, obtained from a VFM through KD, with 3D spatial reasoning capabilities. Experiments on standard autonomous driving benchmarks for 2D-to-3D KD demonstrate that CleverDistiller achieves state-of-the-art performance in both semantic segmentation and 3D object detection (3DOD) by up to 10% mIoU, especially when fine tuning on really low data amounts, showing the effectiveness of our simple yet powerful KD strategy
S3PT: Scene Semantics and Structure Guided Clustering to Boost Self-Supervised Pre-Training for Autonomous Driving
Oct 30, 2024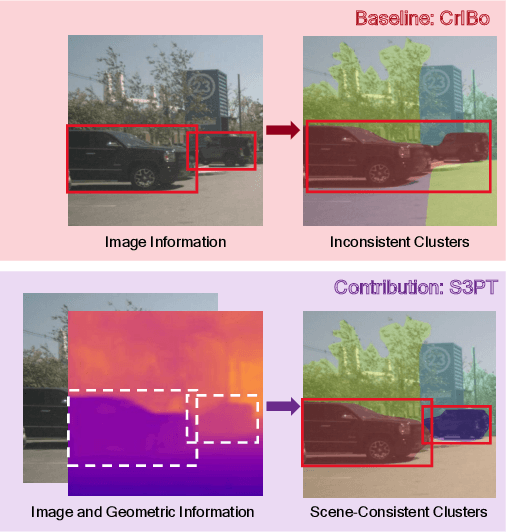
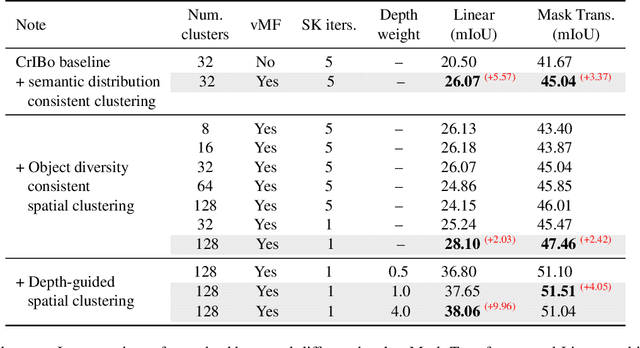
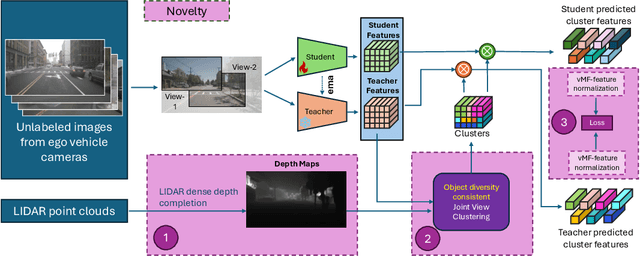
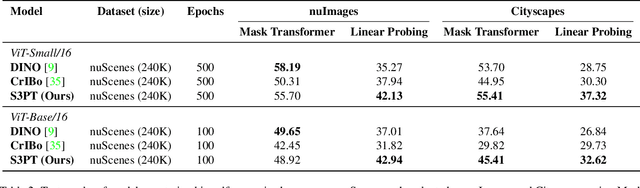
Recent self-supervised clustering-based pre-training techniques like DINO and Cribo have shown impressive results for downstream detection and segmentation tasks. However, real-world applications such as autonomous driving face challenges with imbalanced object class and size distributions and complex scene geometries. In this paper, we propose S3PT a novel scene semantics and structure guided clustering to provide more scene-consistent objectives for self-supervised training. Specifically, our contributions are threefold: First, we incorporate semantic distribution consistent clustering to encourage better representation of rare classes such as motorcycles or animals. Second, we introduce object diversity consistent spatial clustering, to handle imbalanced and diverse object sizes, ranging from large background areas to small objects such as pedestrians and traffic signs. Third, we propose a depth-guided spatial clustering to regularize learning based on geometric information of the scene, thus further refining region separation on the feature level. Our learned representations significantly improve performance in downstream semantic segmentation and 3D object detection tasks on the nuScenes, nuImages, and Cityscapes datasets and show promising domain translation properties.
On Partial Prototype Collapse in the DINO Family of Self-Supervised Methods
Oct 17, 2024



A prominent self-supervised learning paradigm is to model the representations as clusters, or more generally as a mixture model. Learning to map the data samples to compact representations and fitting the mixture model simultaneously leads to the representation collapse problem. Regularizing the distribution of data points over the clusters is the prevalent strategy to avoid this issue. While this is sufficient to prevent full representation collapse, we show that a partial prototype collapse problem still exists in the DINO family of methods, that leads to significant redundancies in the prototypes. Such prototype redundancies serve as shortcuts for the method to achieve a marginal latent class distribution that matches the prescribed prior. We show that by encouraging the model to use diverse prototypes, the partial prototype collapse can be mitigated. Effective utilization of the prototypes enables the methods to learn more fine-grained clusters, encouraging more informative representations. We demonstrate that this is especially beneficial when pre-training on a long-tailed fine-grained dataset.
DINO as a von Mises-Fisher mixture model
May 17, 2024

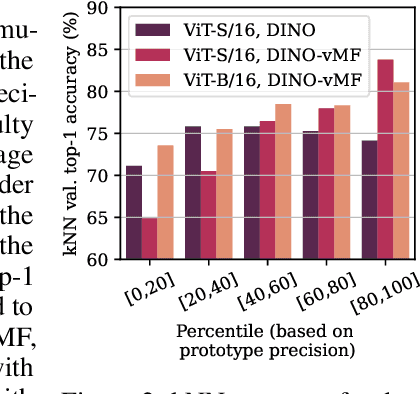

Self-distillation methods using Siamese networks are popular for self-supervised pre-training. DINO is one such method based on a cross-entropy loss between $K$-dimensional probability vectors, obtained by applying a softmax function to the dot product between representations and learnt prototypes. Given the fact that the learned representations are $L^2$-normalized, we show that DINO and its derivatives, such as iBOT, can be interpreted as a mixture model of von Mises-Fisher components. With this interpretation, DINO assumes equal precision for all components when the prototypes are also $L^2$-normalized. Using this insight we propose DINO-vMF, that adds appropriate normalization constants when computing the cluster assignment probabilities. Unlike DINO, DINO-vMF is stable also for the larger ViT-Base model with unnormalized prototypes. We show that the added flexibility of the mixture model is beneficial in terms of better image representations. The DINO-vMF pre-trained model consistently performs better than DINO on a range of downstream tasks. We obtain similar improvements for iBOT-vMF vs iBOT and thereby show the relevance of our proposed modification also for other methods derived from DINO.