 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Partial Prototype Collapse in the DINO Family of Self-Supervised Methods
Oct 17, 2024



A prominent self-supervised learning paradigm is to model the representations as clusters, or more generally as a mixture model. Learning to map the data samples to compact representations and fitting the mixture model simultaneously leads to the representation collapse problem. Regularizing the distribution of data points over the clusters is the prevalent strategy to avoid this issue. While this is sufficient to prevent full representation collapse, we show that a partial prototype collapse problem still exists in the DINO family of methods, that leads to significant redundancies in the prototypes. Such prototype redundancies serve as shortcuts for the method to achieve a marginal latent class distribution that matches the prescribed prior. We show that by encouraging the model to use diverse prototypes, the partial prototype collapse can be mitigated. Effective utilization of the prototypes enables the methods to learn more fine-grained clusters, encouraging more informative representations. We demonstrate that this is especially beneficial when pre-training on a long-tailed fine-grained dataset.
DINO as a von Mises-Fisher mixture model
May 17, 2024

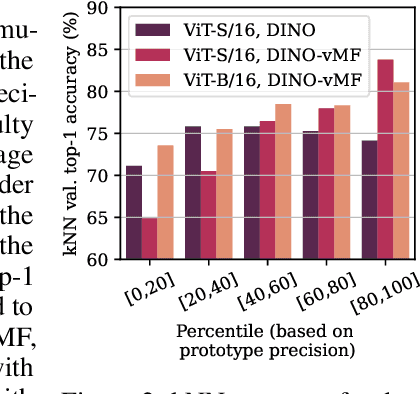

Self-distillation methods using Siamese networks are popular for self-supervised pre-training. DINO is one such method based on a cross-entropy loss between $K$-dimensional probability vectors, obtained by applying a softmax function to the dot product between representations and learnt prototypes. Given the fact that the learned representations are $L^2$-normalized, we show that DINO and its derivatives, such as iBOT, can be interpreted as a mixture model of von Mises-Fisher components. With this interpretation, DINO assumes equal precision for all components when the prototypes are also $L^2$-normalized. Using this insight we propose DINO-vMF, that adds appropriate normalization constants when computing the cluster assignment probabilities. Unlike DINO, DINO-vMF is stable also for the larger ViT-Base model with unnormalized prototypes. We show that the added flexibility of the mixture model is beneficial in terms of better image representations. The DINO-vMF pre-trained model consistently performs better than DINO on a range of downstream tasks. We obtain similar improvements for iBOT-vMF vs iBOT and thereby show the relevance of our proposed modification also for other methods derived from DINO.
Evaluating model calibration in classification
Feb 19, 2019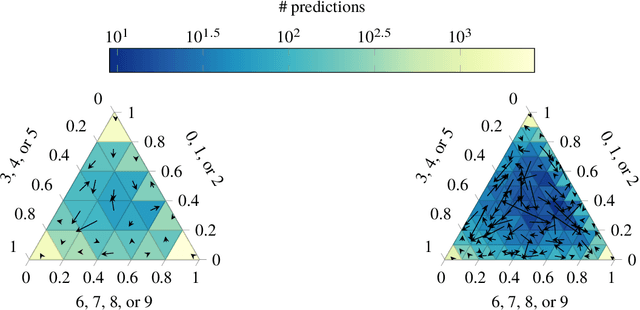

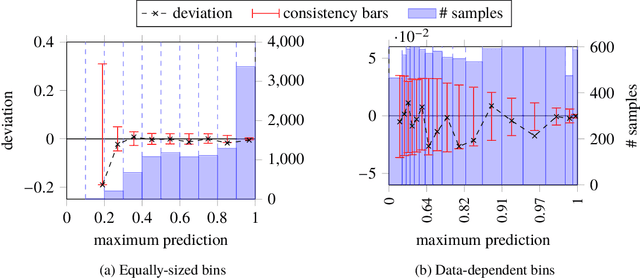
Probabilistic classifiers output a probability distribution on target classes rather than just a class prediction. Besides providing a clear separation of prediction and decision making, the main advantage of probabilistic models is their ability to represent uncertainty about predictions. In safety-critical applications, it is pivotal for a model to possess an adequate sense of uncertainty, which for probabilistic classifiers translates into outputting probability distributions that are consistent with the empirical frequencies observed from realized outcomes. A classifier with such a property is called calibrated. In this work, we develop a general theoretical calibration evaluation framework grounded in probability theory, and point out subtleties present in model calibration evaluation that lead to refined interpretations of existing evaluation techniques. Lastly, we propose new ways to quantify and visualize miscalibration in probabilistic classification, including novel multidimensional reliability diagrams.