 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLmPT: Conditional Point Transformer for Anatomical Landmark Detection on 3D Point Clouds
Feb 02, 2026Accurate identification of anatomical landmarks is crucial for various medical applications. Traditional manual landmarking is time-consuming and prone to inter-observer variability, while rule-based methods are often tailored to specific geometries or limited sets of landmarks. In recent years, anatomical surfaces have been effectively represented as point clouds, which are lightweight structures composed of spatial coordinates. Following this strategy and to overcome the limitations of existing landmarking techniques, we propose Landmark Point Transformer (LmPT), a method for automatic anatomical landmark detection on point clouds that can leverage homologous bones from different species for translational research. The LmPT model incorporates a conditioning mechanism that enables adaptability to different input types to conduct cross-species learning. We focus the evaluation of our approach on femoral landmarking using both human and newly annotated dog femurs, demonstrating its generalization and effectiveness across species. The code and dog femur dataset will be publicly available at: https://github.com/Pierreoo/LandmarkPointTransformer.
* This paper has been accepted at International Symposium on Biomedical Imaging (ISBI) 2026
Paris-CARLA-3D: A Real and Synthetic Outdoor Point Cloud Dataset for Challenging Tasks in 3D Mapping
Nov 22, 2021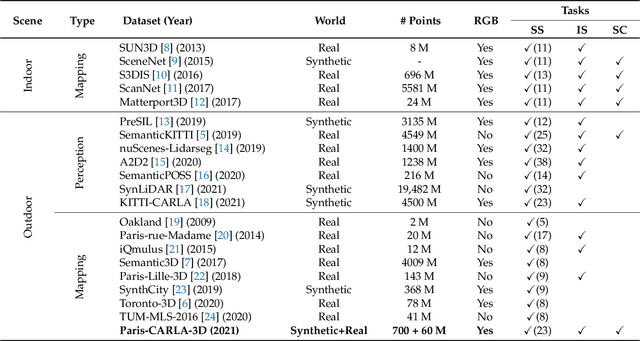



Paris-CARLA-3D is a dataset of several dense colored point clouds of outdoor environments built by a mobile LiDAR and camera system. The data are composed of two sets with synthetic data from the open source CARLA simulator (700 million points) and real data acquired in the city of Paris (60 million points), hence the name Paris-CARLA-3D. One of the advantages of this dataset is to have simulated the same LiDAR and camera platform in the open source CARLA simulator as the one used to produce the real data. In addition, manual annotation of the classes using the semantic tags of CARLA was performed on the real data, allowing the testing of transfer methods from the synthetic to the real data. The objective of this dataset is to provide a challenging dataset to evaluate and improve methods on difficult vision tasks for the 3D mapping of outdoor environments: semantic segmentation, instance segmentation, and scene completion. For each task, we describe the evaluation protocol as well as the experiments carried out to establish a baseline.
Road Segmentation on low resolution Lidar point clouds for autonomous vehicles
May 27, 2020
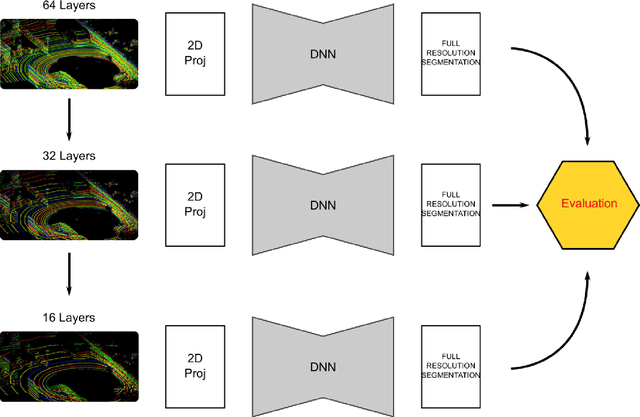
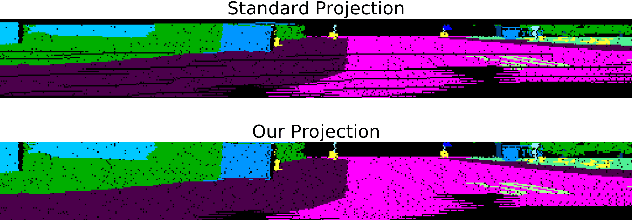
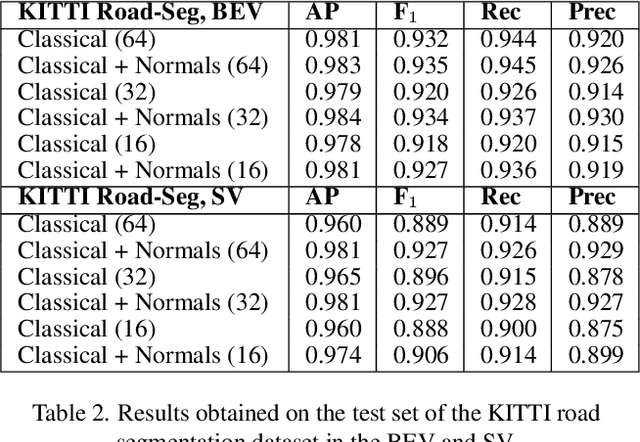
Point cloud datasets for perception tasks in the context of autonomous driving often rely on high resolution 64-layer Light Detection and Ranging (LIDAR) scanners. They are expensive to deploy on real-world autonomous driving sensor architectures which usually employ 16/32 layer LIDARs. We evaluate the effect of subsampling image based representations of dense point clouds on the accuracy of the road segmentation task. In our experiments the low resolution 16/32 layer LIDAR point clouds are simulated by subsampling the original 64 layer data, for subsequent transformation in to a feature map in the Bird-Eye-View (BEV) and SphericalView (SV) representations of the point cloud. We introduce the usage of the local normal vector with the LIDAR's spherical coordinates as an input channel to existing LoDNN architectures. We demonstrate that this local normal feature in conjunction with classical features not only improves performance for binary road segmentation on full resolution point clouds, but it also reduces the negative impact on the accuracy when subsampling dense point clouds as compared to the usage of classical features alone. We assess our method with several experiments on two datasets: KITTI Road-segmentation benchmark and the recently released Semantic KITTI dataset.
KPConv: Flexible and Deformable Convolution for Point Clouds
Apr 18, 2019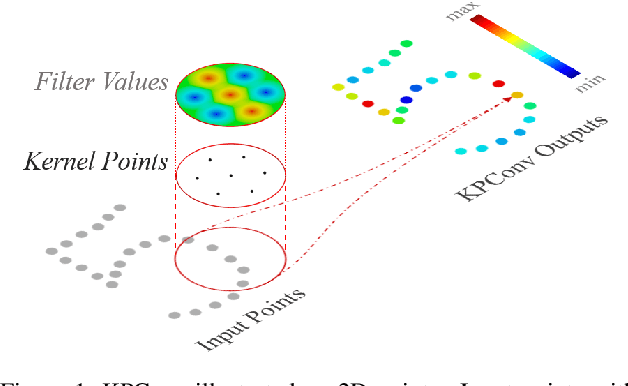
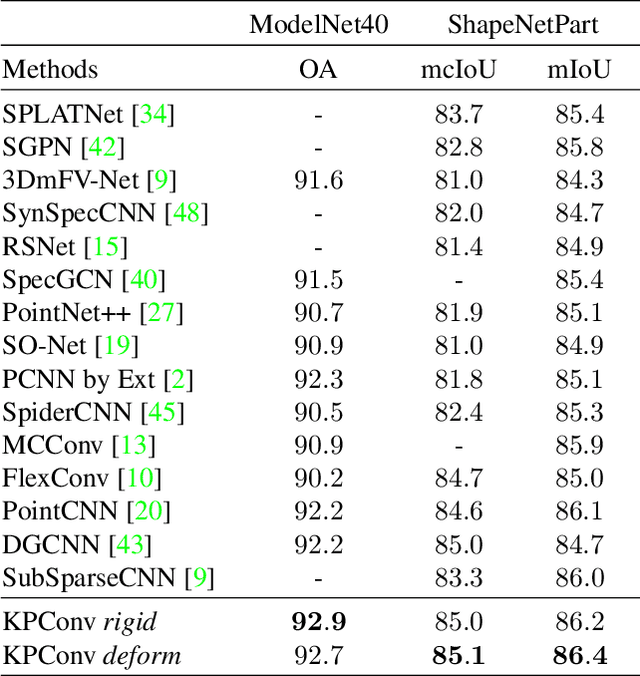
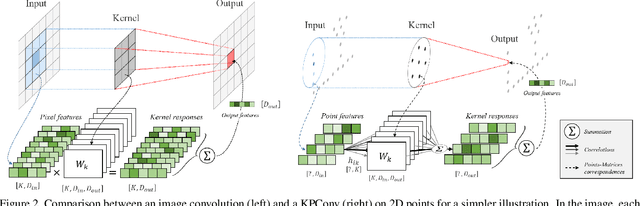
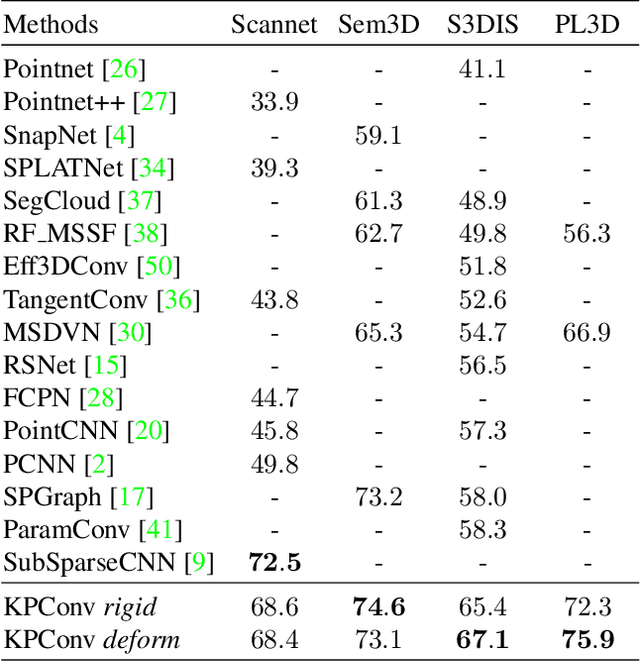
We present Kernel Point Convolution (KPConv), a new design of point convolution, i.e. that operates on point clouds without any intermediate representation. The convolution weights of KPConv are located in Euclidean space by kernel points, and applied to the input points close to them. Its capacity to use any number of kernel points gives KPConv more flexibility than fixed grid convolutions. Furthermore, these locations are continuous in space and can be learned by the network. Therefore, KPConv can be extended to deformable convolutions that learn to adapt kernel points to local geometry. Thanks to a regular subsampling strategy, KPConv is also efficient and robust to varying densities. Whether they use deformable KPConv for complex tasks, or rigid KPconv for simpler tasks, our networks outperform state-of-the-art classification and segmentation approaches on several datasets. We also offer ablation studies and visualizations to provide understanding of what has been learned by KPConv and to validate the descriptive power of deformable KPConv.
Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods
Aug 01, 2018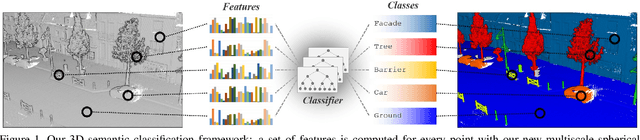

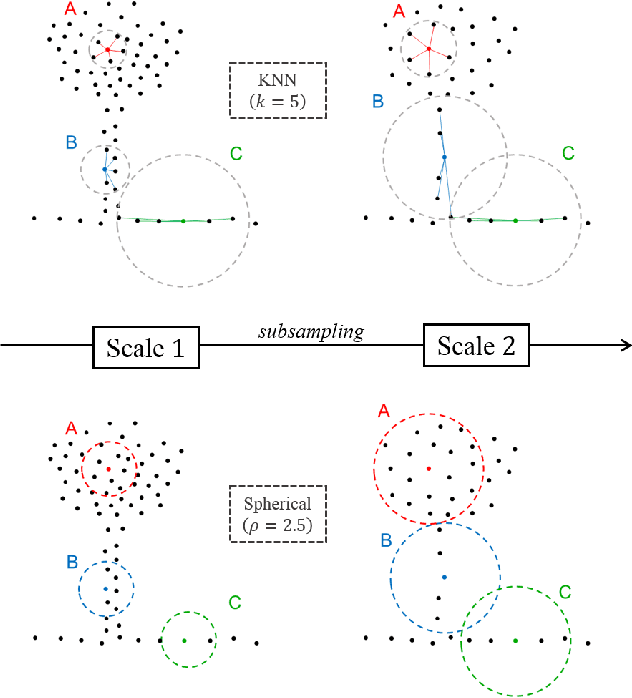
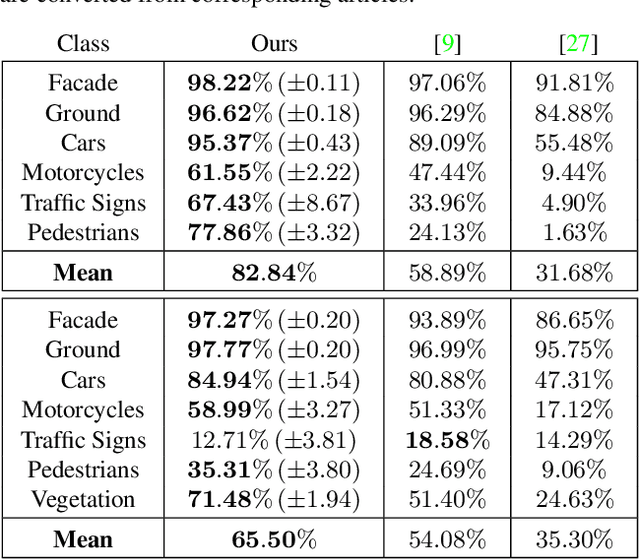
This paper introduces a new definition of multiscale neighborhoods in 3D point clouds. This definition, based on spherical neighborhoods and proportional subsampling, allows the computation of features with a consistent geometrical meaning, which is not the case when using k-nearest neighbors. With an appropriate learning strategy, the proposed features can be used in a random forest to classify 3D points. In this semantic classification task, we show that our multiscale features outperform state-of-the-art features using the same experimental conditions. Furthermore, their classification power competes with more elaborate classification approaches including Deep Learning methods.
Segmentation et Interprétation de Nuages de Points pour la Modélisation d'Environnements Urbains
Jun 13, 2013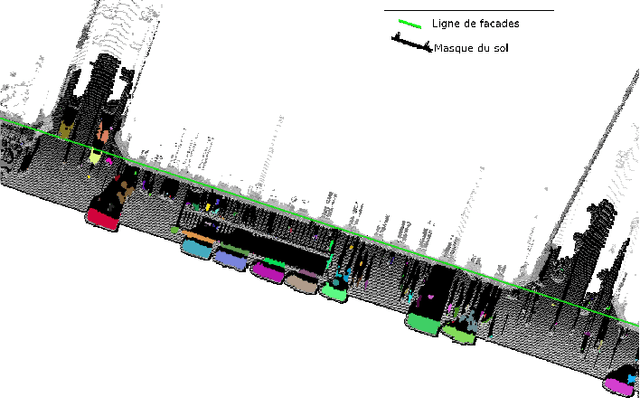
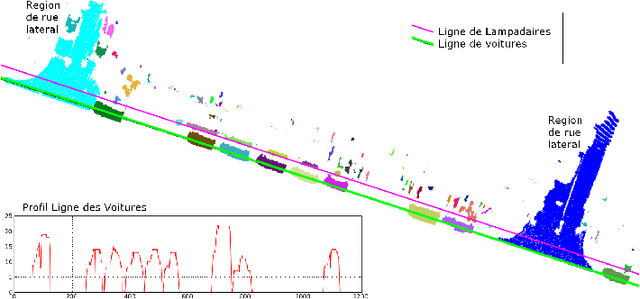
Dans cet article, nous pr\'esentons une m\'ethode pour la d\'etection et la classification d'artefacts au niveau du sol, comme phase de filtrage pr\'ealable \`a la mod\'elisation d'environnements urbains. La m\'ethode de d\'etection est r\'ealis\'ee sur l'image profondeur, une projection de nuage de points sur un plan image o\`u la valeur du pixel correspond \`a la distance du point au plan. En faisant l'hypoth\`ese que les artefacts sont situ\'es au sol, ils sont d\'etect\'es par une transformation de chapeau haut de forme par remplissage de trous sur l'image de profondeur. Les composantes connexes ainsi obtenues, sont ensuite caract\'eris\'ees et une analyse des variables est utilis\'ee pour la s\'election des caract\'eristiques les plus discriminantes. Les composantes connexes sont donc classifi\'ees en quatre cat\'egories (lampadaires, pi\'etons, voitures et "Reste") \`a l'aide d'un algorithme d'apprentissage supervis\'e. La m\'ethode a \'et\'e test\'ee sur des nuages de points de la ville de Paris, en montrant de bons r\'esultats de d\'etection et de classification dans l'ensemble de donn\'ees.---In this article, we present a method for detection and classification of artifacts at the street level, in order to filter cloud point, facilitating the urban modeling process. Our approach exploits 3D information by using range image, a projection of 3D points onto an image plane where the pixel intensity is a function of the measured distance between 3D points and the plane. By assuming that the artifacts are on the ground, they are detected using a Top-Hat of the hole filling algorithm of range images. Then, several features are extracted from the detected connected components and a stepwise forward variable/model selection by using the Wilk's Lambda criterion is performed. Afterward, CCs are classified in four categories (lampposts, pedestrians, cars and others) by using a supervised machine learning method. The proposed method was tested on cloud points of Paris, and have shown satisfactory results on the whole dataset.