 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the effect of data augmentation and BALD heuristics on distillation of Semantic-KITTI dataset
Feb 21, 2023Active Learning (AL) has remained relatively unexplored for LiDAR perception tasks in autonomous driving datasets. In this study we evaluate Bayesian active learning methods applied to the task of dataset distillation or core subset selection (subset with near equivalent performance as full dataset). We also study the effect of application of data augmentation (DA) within Bayesian AL based dataset distillation. We perform these experiments on the full Semantic-KITTI dataset. We extend our study over our existing work only on 1/4th of the same dataset. Addition of DA and BALD have a negative impact over the labeling efficiency and thus the capacity to distill datasets. We demonstrate key issues in designing a functional AL framework and finally conclude with a review of challenges in real world active learning.
Navya3DSeg -- Navya 3D Semantic Segmentation Dataset & split generation for autonomous vehicles
Feb 16, 2023



Autonomous driving (AD) perception today relies heavily on deep learning based architectures requiring large scale annotated datasets with their associated costs for curation and annotation. The 3D semantic data are useful for core perception tasks such as obstacle detection and ego-vehicle localization. We propose a new dataset, Navya 3D Segmentation (Navya3DSeg), with a diverse label space corresponding to a large scale production grade operational domain, including rural, urban, industrial sites and universities from 13 countries. It contains 23 labeled sequences and 25 supplementary sequences without labels, designed to explore self-supervised and semi-supervised semantic segmentation benchmarks on point clouds. We also propose a novel method for sequential dataset split generation based on iterative multi-label stratification, and demonstrated to achieve a +1.2% mIoU improvement over the original split proposed by SemanticKITTI dataset. A complete benchmark for semantic segmentation task was performed, with state of the art methods. Finally, we demonstrate an active learning (AL) based dataset distillation framework. We introduce a novel heuristic-free sampling method called distance sampling in the context of AL. A detailed presentation on the dataset is available at https://www.youtube.com/watch?v=5m6ALIs-s20 .
LiDAR dataset distillation within bayesian active learning framework: Understanding the effect of data augmentation
Feb 06, 2022


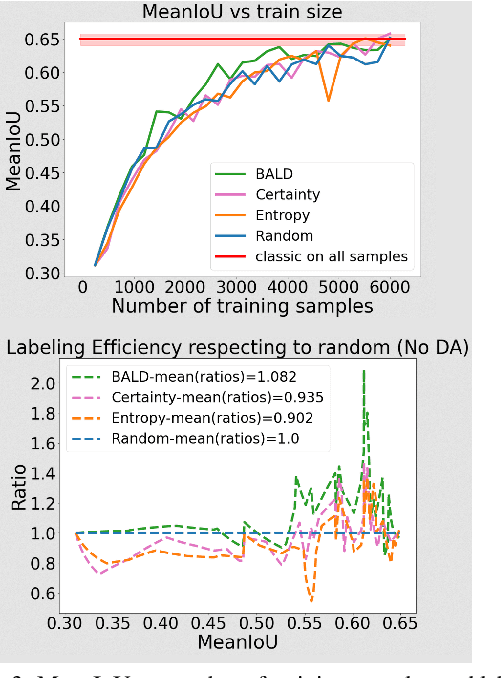
Autonomous driving (AD) datasets have progressively grown in size in the past few years to enable better deep representation learning. Active learning (AL) has re-gained attention recently to address reduction of annotation costs and dataset size. AL has remained relatively unexplored for AD datasets, especially on point cloud data from LiDARs. This paper performs a principled evaluation of AL based dataset distillation on (1/4th) of the large Semantic-KITTI dataset. Further on, the gains in model performance due to data augmentation (DA) are demonstrated across different subsets of the AL loop. We also demonstrate how DA improves the selection of informative samples to annotate. We observe that data augmentation achieves full dataset accuracy using only 60\% of samples from the selected dataset configuration. This provides faster training time and subsequent gains in annotation costs.