 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR dataset distillation within bayesian active learning framework: Understanding the effect of data augmentation
Feb 06, 2022


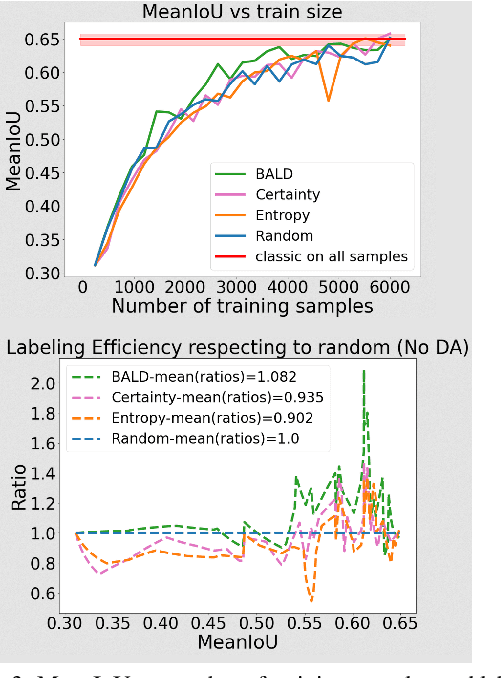
Autonomous driving (AD) datasets have progressively grown in size in the past few years to enable better deep representation learning. Active learning (AL) has re-gained attention recently to address reduction of annotation costs and dataset size. AL has remained relatively unexplored for AD datasets, especially on point cloud data from LiDARs. This paper performs a principled evaluation of AL based dataset distillation on (1/4th) of the large Semantic-KITTI dataset. Further on, the gains in model performance due to data augmentation (DA) are demonstrated across different subsets of the AL loop. We also demonstrate how DA improves the selection of informative samples to annotate. We observe that data augmentation achieves full dataset accuracy using only 60\% of samples from the selected dataset configuration. This provides faster training time and subsequent gains in annotation costs.