 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundation Models for Enhancing Robot Perception and Action
Oct 30, 2025This thesis investigates how foundation models can be systematically leveraged to enhance robotic capabilities, enabling more effective localization, interaction, and manipulation in unstructured environments. The work is structured around four core lines of inquiry, each addressing a fundamental challenge in robotics while collectively contributing to a cohesive framework for semantics-aware robotic intelligence.
Augmented Reality for RObots (ARRO): Pointing Visuomotor Policies Towards Visual Robustness
May 13, 2025Visuomotor policies trained on human expert demonstrations have recently shown strong performance across a wide range of robotic manipulation tasks. However, these policies remain highly sensitive to domain shifts stemming from background or robot embodiment changes, which limits their generalization capabilities. In this paper, we present ARRO, a novel calibration-free visual representation that leverages zero-shot open-vocabulary segmentation and object detection models to efficiently mask out task-irrelevant regions of the scene without requiring additional training. By filtering visual distractors and overlaying virtual guides during both training and inference, ARRO improves robustness to scene variations and reduces the need for additional data collection. We extensively evaluate ARRO with Diffusion Policy on several tabletop manipulation tasks in both simulation and real-world environments, and further demonstrate its compatibility and effectiveness with generalist robot policies, such as Octo and OpenVLA. Across all settings in our evaluation, ARRO yields consistent performance gains, allows for selective masking to choose between different objects, and shows robustness even to challenging segmentation conditions. Videos showcasing our results are available at: augmented-reality-for-robots.github.io
VLM-Vac: Enhancing Smart Vacuums through VLM Knowledge Distillation and Language-Guided Experience Replay
Sep 21, 2024



In this paper, we propose VLM-Vac, a novel framework designed to enhance the autonomy of smart robot vacuum cleaners. Our approach integrates the zero-shot object detection capabilities of a Vision-Language Model (VLM) with a Knowledge Distillation (KD) strategy. By leveraging the VLM, the robot can categorize objects into actionable classes -- either to avoid or to suck -- across diverse backgrounds. However, frequently querying the VLM is computationally expensive and impractical for real-world deployment. To address this issue, we implement a KD process that gradually transfers the essential knowledge of the VLM to a smaller, more efficient model. Our real-world experiments demonstrate that this smaller model progressively learns from the VLM and requires significantly fewer queries over time. Additionally, we tackle the challenge of continual learning in dynamic home environments by exploiting a novel experience replay method based on language-guided sampling. Our results show that this approach is not only energy-efficient but also surpasses conventional vision-based clustering methods, particularly in detecting small objects across diverse backgrounds.
LAN-grasp: Using Large Language Models for Semantic Object Grasping
Oct 08, 2023



In this paper, we propose LAN-grasp, a novel approach towards more appropriate semantic grasping. We use foundation models to provide the robot with a deeper understanding of the objects, the right place to grasp an object, or even the parts to avoid. This allows our robot to grasp and utilize objects in a more meaningful and safe manner. We leverage the combination of a Large Language Model, a Vision Language Model, and a traditional grasp planner to generate grasps demonstrating a deeper semantic understanding of the objects. We first prompt the Large Language Model about which object part is appropriate for grasping. Next, the Vision Language Model identifies the corresponding part in the object image. Finally, we generate grasp proposals in the region proposed by the Vision Language Model. Building on foundation models provides us with a zero-shot grasp method that can handle a wide range of objects without the need for further training or fine-tuning. We evaluated our method in real-world experiments on a custom object data set. We present the results of a survey that asks the participants to choose an object part appropriate for grasping. The results show that the grasps generated by our method are consistently ranked higher by the participants than those generated by a conventional grasping planner and a recent semantic grasping approach.
FM-Loc: Using Foundation Models for Improved Vision-based Localization
Apr 14, 2023



Visual place recognition is essential for vision-based robot localization and SLAM. Despite the tremendous progress made in recent years, place recognition in changing environments remains challenging. A promising approach to cope with appearance variations is to leverage high-level semantic features like objects or place categories. In this paper, we propose FM-Loc which is a novel image-based localization approach based on Foundation Models that uses the Large Language Model GPT-3 in combination with the Visual-Language Model CLIP to construct a semantic image descriptor that is robust to severe changes in scene geometry and camera viewpoint. We deploy CLIP to detect objects in an image, GPT-3 to suggest potential room labels based on the detected objects, and CLIP again to propose the most likely location label. The object labels and the scene label constitute an image descriptor that we use to calculate a similarity score between the query and database images. We validate our approach on real-world data that exhibit significant changes in camera viewpoints and object placement between the database and query trajectories. The experimental results demonstrate that our method is applicable to a wide range of indoor scenarios without the need for training or fine-tuning.
A Whole-Body Model Predictive Control Scheme Including External Contact Forces and CoM Height Variations
Oct 24, 2018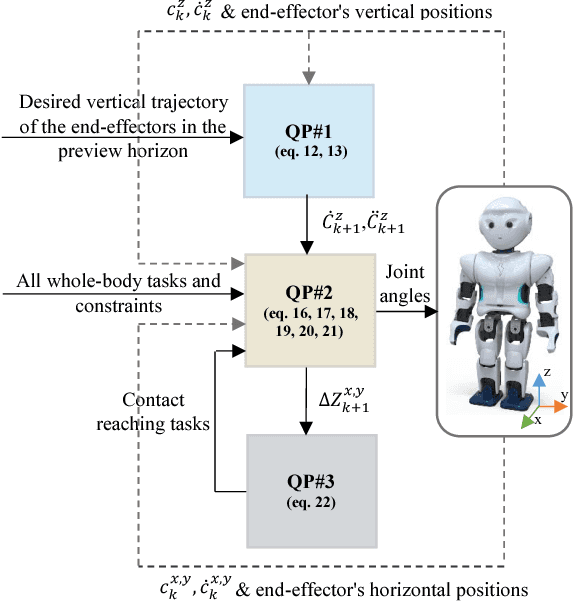


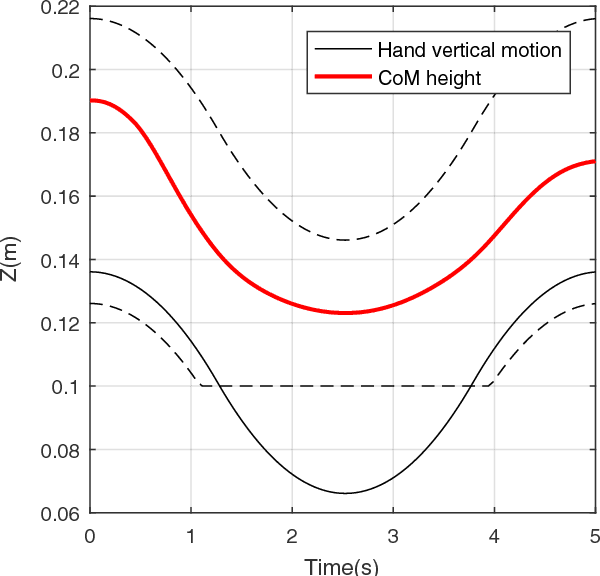
In this paper, we present an approach for generating a variety of whole-body motions for a humanoid robot. We extend the available Model Predictive Control (MPC) approaches for walking on flat terrain to plan for both vertical motion of the Center of Mass (CoM) and external contact forces consistent with a given task. The optimization problem is comprised of three stages, i. e. the CoM vertical motion, joint angles, and contact forces planning. The choice of external contact (e. g. hand contact with the object or environment) among all available locations and the appropriate time to reach and maintain a contact are all computed automatically within the algorithm. The presented algorithm benefits from the simplicity of the Linear Inverted Pendulum Model (LIPM), while it overcomes the common limitations of this model and enables us to generate a variety of whole-body motions through external contacts. Simulation and experimental implementation of several whole-body actions in multi-contact scenarios on a humanoid robot show the capability of the proposed algorithm.
Push Recovery of a Position-Controlled Humanoid Robot Based on Capture Point Feedback Control
Oct 29, 2017
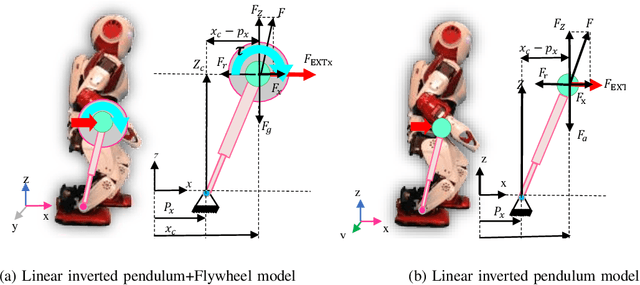
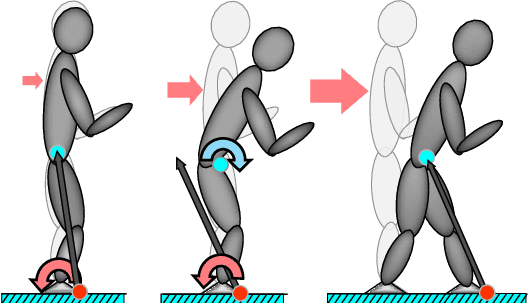

In this paper, a combination of ankle and hip strategy is used for push recovery of a position-controlled humanoid robot. Ankle strategy and hip strategy are equivalent to Center of Pressure (CoP) and Centroidal Moment Pivot (CMP) regulation respectively. For controlling the CMP and CoP we need a torque-controlled robot, however most of the conventional humanoid robots are position controlled. In this regard, we present an efficient way for implementation of the hip and ankle strategies on a position controlled humanoid robot. We employ a feedback controller to compensate the capture point error. Using our scheme, a simple and practical push recovery controller is designed which can be implemented on the most of the conventional humanoid robots without the need for torque sensors. The effectiveness of the proposed approach is verified through push recovery experiments on SURENA-Mini humanoid robot under severe pushes.