 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Reliable Information-enhanced Multimodal Contrastive Learning for Fake News Detection
Mar 05, 2025With the rapid development of the Internet, the information dissemination paradigm has changed and the efficiency has been improved greatly. While this also brings the quick spread of fake news and leads to negative impacts on cyberspace. Currently, the information presentation formats have evolved gradually, with the news formats shifting from texts to multimodal contents. As a result, detecting multimodal fake news has become one of the research hotspots. However, multimodal fake news detection research field still faces two main challenges: the inability to fully and effectively utilize multimodal information for detection, and the low credibility or static nature of the introduced external information, which limits dynamic updates. To bridge the gaps, we propose ERIC-FND, an external reliable information-enhanced multimodal contrastive learning framework for fake news detection. ERIC-FND strengthens the representation of news contents by entity-enriched external information enhancement method. It also enriches the multimodal news information via multimodal semantic interaction method where the multimodal constrative learning is employed to make different modality representations learn from each other. Moreover, an adaptive fusion method is taken to integrate the news representations from different dimensions for the eventual classification. Experiments are done on two commonly used datasets in different languages, X (Twitter) and Weibo. Experiment results demonstrate that our proposed model ERIC-FND outperforms existing state-of-the-art fake news detection methods under the same settings.
Positive Text Reframing under Multi-strategy Optimization
Jul 27, 2024
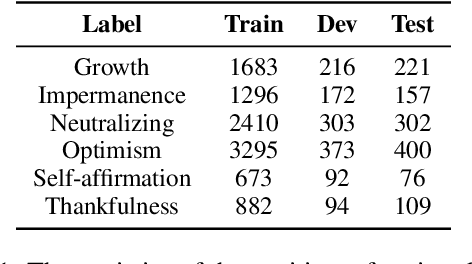


Differing from sentiment transfer, positive reframing seeks to substitute negative perspectives with positive expressions while preserving the original meaning. With the emergence of pre-trained language models (PLMs), it is possible to achieve acceptable results by fine-tuning PLMs. Nevertheless, generating fluent, diverse and task-constrained reframing text remains a significant challenge. To tackle this issue, a \textbf{m}ulti-\textbf{s}trategy \textbf{o}ptimization \textbf{f}ramework (MSOF) is proposed in this paper. Starting from the objective of positive reframing, we first design positive sentiment reward and content preservation reward to encourage the model to transform the negative expressions of the original text while ensuring the integrity and consistency of the semantics. Then, different decoding optimization approaches are introduced to improve the quality of text generation. Finally, based on the modeling formula of positive reframing, we propose a multi-dimensional re-ranking method that further selects candidate sentences from three dimensions: strategy consistency, text similarity and fluency. Extensive experiments on two Seq2Seq PLMs, BART and T5, demonstrate our framework achieves significant improvements on unconstrained and controlled positive reframing tasks.
Multi-hop Commonsense Knowledge Injection Framework for Zero-Shot Commonsense Question Answering
May 10, 2023Commonsense question answering (QA) research requires machines to answer questions based on commonsense knowledge. However, this research requires expensive labor costs to annotate data as the basis of research, and models that rely on fine-tuning paradigms only apply to specific tasks, rather than learn a general commonsense reasoning ability. As a more robust method, zero-shot commonsense question answering shows a good prospect. The current zero-shot framework tries to convert triples in commonsense knowledge graphs (KGs) into QA-form samples as the pre-trained data source to incorporate commonsense knowledge into the model. However, this method ignores the multi-hop relationship in the KG, which is also an important central problem in commonsense reasoning. In this paper, we propose a novel multi-hop commonsense knowledge injection framework. Specifically, it explores multi-hop reasoning paradigm in KGs that conform to linguistic logic, and we further propose two multi-hop QA generation methods based on KGs. Then, we utilize contrastive learning to pre-train the model with the synthetic QA dataset to inject multi-hop commonsense knowledge. Extensive experiments on five commonsense question answering benchmarks demonstrate that our framework achieves state-of-art performance.
No Place to Hide: Dual Deep Interaction Channel Network for Fake News Detection based on Data Augmentation
Mar 31, 2023



Online Social Network (OSN) has become a hotbed of fake news due to the low cost of information dissemination. Although the existing methods have made many attempts in news content and propagation structure, the detection of fake news is still facing two challenges: one is how to mine the unique key features and evolution patterns, and the other is how to tackle the problem of small samples to build the high-performance model. Different from popular methods which take full advantage of the propagation topology structure, in this paper, we propose a novel framework for fake news detection from perspectives of semantic, emotion and data enhancement, which excavates the emotional evolution patterns of news participants during the propagation process, and a dual deep interaction channel network of semantic and emotion is designed to obtain a more comprehensive and fine-grained news representation with the consideration of comments. Meanwhile, the framework introduces a data enhancement module to obtain more labeled data with high quality based on confidence which further improves the performance of the classification model. Experiments show that the proposed approach outperforms the state-of-the-art methods.
AlignVE: Visual Entailment Recognition Based on Alignment Relations
Nov 16, 2022



Visual entailment (VE) is to recognize whether the semantics of a hypothesis text can be inferred from the given premise image, which is one special task among recent emerged vision and language understanding tasks. Currently, most of the existing VE approaches are derived from the methods of visual question answering. They recognize visual entailment by quantifying the similarity between the hypothesis and premise in the content semantic features from multi modalities. Such approaches, however, ignore the VE's unique nature of relation inference between the premise and hypothesis. Therefore, in this paper, a new architecture called AlignVE is proposed to solve the visual entailment problem with a relation interaction method. It models the relation between the premise and hypothesis as an alignment matrix. Then it introduces a pooling operation to get feature vectors with a fixed size. Finally, it goes through the fully-connected layer and normalization layer to complete the classification. Experiments show that our alignment-based architecture reaches 72.45\% accuracy on SNLI-VE dataset, outperforming previous content-based models under the same settings.