 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrevealed Threats: A Comprehensive Study of the Adversarial Robustness of Underwater Image Enhancement Models
Paper and Code
Sep 10, 2024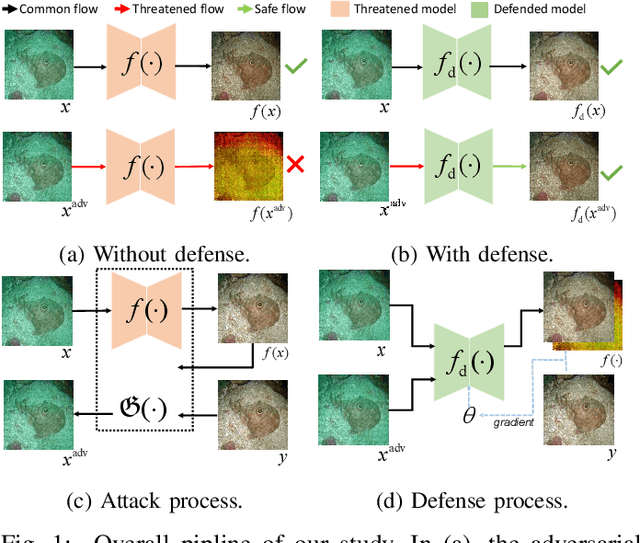


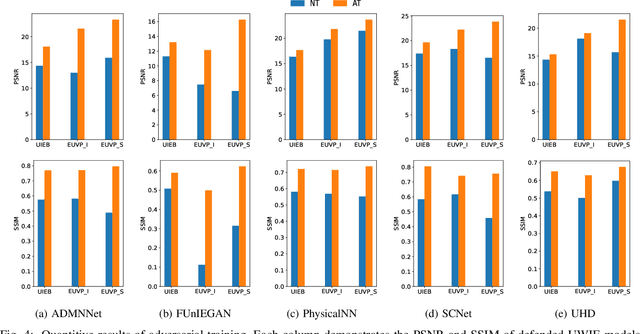
Learning-based methods for underwater image enhancement (UWIE) have undergone extensive exploration. However, learning-based models are usually vulnerable to adversarial examples so as the UWIE models. To the best of our knowledge, there is no comprehensive study on the adversarial robustness of UWIE models, which indicates that UWIE models are potentially under the threat of adversarial attacks. In this paper, we propose a general adversarial attack protocol. We make a first attempt to conduct adversarial attacks on five well-designed UWIE models on three common underwater image benchmark datasets. Considering the scattering and absorption of light in the underwater environment, there exists a strong correlation between color correction and underwater image enhancement. On the basis of that, we also design two effective UWIE-oriented adversarial attack methods Pixel Attack and Color Shift Attack targeting different color spaces. The results show that five models exhibit varying degrees of vulnerability to adversarial attacks and well-designed small perturbations on degraded images are capable of preventing UWIE models from generating enhanced results. Further, we conduct adversarial training on these models and successfully mitigated the effectiveness of adversarial attacks. In summary, we reveal the adversarial vulnerability of UWIE models and propose a new evaluation dimension of UWIE models.