 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipGPT: Dynamic Layer Pruning Reinvented with Token Awareness and Module Decoupling
Jun 04, 2025Large language models (LLMs) achieve remarkable performance across tasks but incur substantial computational costs due to their deep, multi-layered architectures. Layer pruning has emerged as a strategy to alleviate these inefficiencies, but conventional static pruning methods overlook two critical dynamics inherent to LLM inference: (1) horizontal dynamics, where token-level heterogeneity demands context-aware pruning decisions, and (2) vertical dynamics, where the distinct functional roles of MLP and self-attention layers necessitate component-specific pruning policies. We introduce SkipGPT, a dynamic layer pruning framework designed to optimize computational resource allocation through two core innovations: (1) global token-aware routing to prioritize critical tokens, and (2) decoupled pruning policies for MLP and self-attention components. To mitigate training instability, we propose a two-stage optimization paradigm: first, a disentangled training phase that learns routing strategies via soft parameterization to avoid premature pruning decisions, followed by parameter-efficient LoRA fine-tuning to restore performance impacted by layer removal. Extensive experiments demonstrate that SkipGPT reduces over 40% of model parameters while matching or exceeding the performance of the original dense model across benchmarks. By harmonizing dynamic efficiency with preserved expressivity, SkipGPT advances the practical deployment of scalable, resource-aware LLMs. Our code is publicly available at: https://github.com/EIT-NLP/SkipGPT.
InternLM-Law: An Open Source Chinese Legal Large Language Model
Jun 21, 2024While large language models (LLMs) have showcased impressive capabilities, they struggle with addressing legal queries due to the intricate complexities and specialized expertise required in the legal field. In this paper, we introduce InternLM-Law, a specialized LLM tailored for addressing diverse legal queries related to Chinese laws, spanning from responding to standard legal questions (e.g., legal exercises in textbooks) to analyzing complex real-world legal situations. We meticulously construct a dataset in the Chinese legal domain, encompassing over 1 million queries, and implement a data filtering and processing pipeline to ensure its diversity and quality. Our training approach involves a novel two-stage process: initially fine-tuning LLMs on both legal-specific and general-purpose content to equip the models with broad knowledge, followed by exclusive fine-tuning on high-quality legal data to enhance structured output generation. InternLM-Law achieves the highest average performance on LawBench, outperforming state-of-the-art models, including GPT-4, on 13 out of 20 subtasks. We make InternLM-Law and our dataset publicly available to facilitate future research in applying LLMs within the legal domain.
MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
May 20, 2024



Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
LawBench: Benchmarking Legal Knowledge of Large Language Models
Sep 28, 2023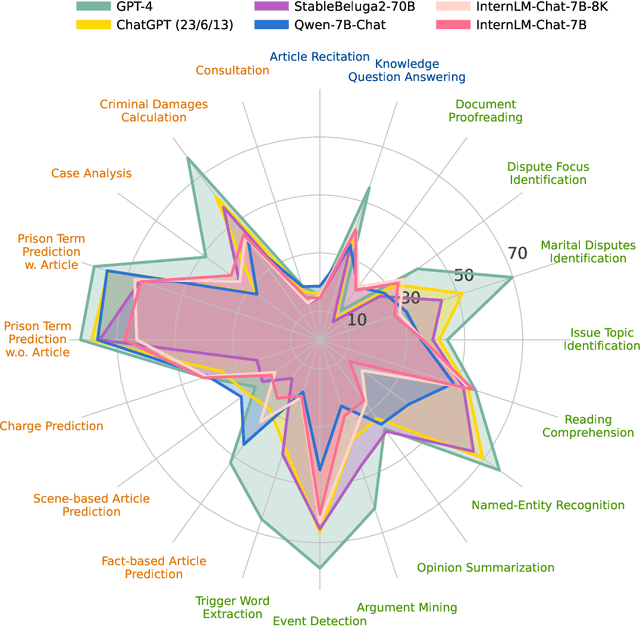
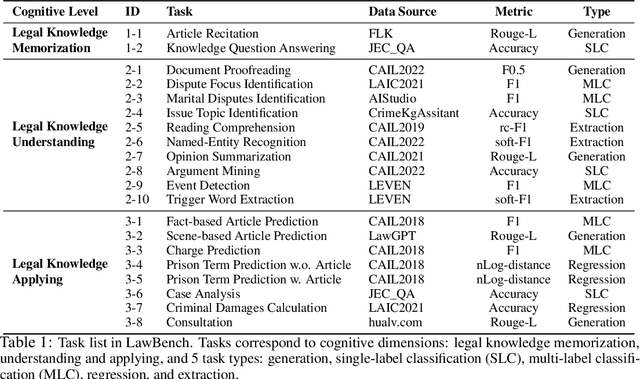
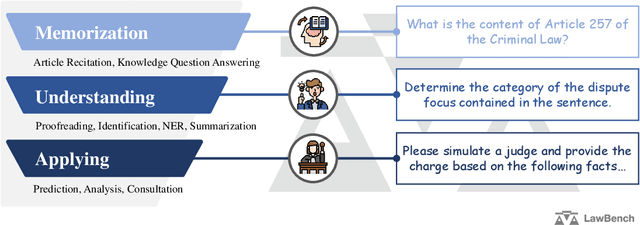
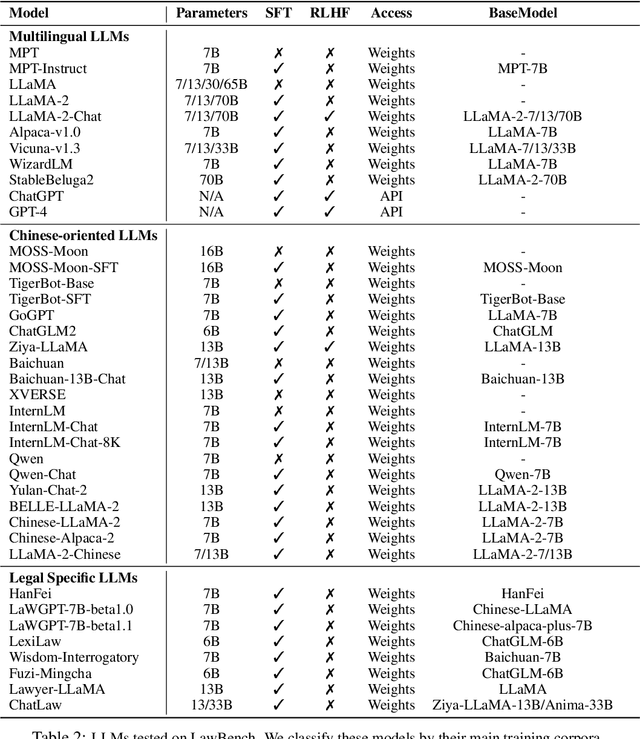
Large language models (LLMs) have demonstrated strong capabilities in various aspects. However, when applying them to the highly specialized, safe-critical legal domain, it is unclear how much legal knowledge they possess and whether they can reliably perform legal-related tasks. To address this gap, we propose a comprehensive evaluation benchmark LawBench. LawBench has been meticulously crafted to have precise assessment of the LLMs' legal capabilities from three cognitive levels: (1) Legal knowledge memorization: whether LLMs can memorize needed legal concepts, articles and facts; (2) Legal knowledge understanding: whether LLMs can comprehend entities, events and relationships within legal text; (3) Legal knowledge applying: whether LLMs can properly utilize their legal knowledge and make necessary reasoning steps to solve realistic legal tasks. LawBench contains 20 diverse tasks covering 5 task types: single-label classification (SLC), multi-label classification (MLC), regression, extraction and generation. We perform extensive evaluations of 51 LLMs on LawBench, including 20 multilingual LLMs, 22 Chinese-oriented LLMs and 9 legal specific LLMs. The results show that GPT-4 remains the best-performing LLM in the legal domain, surpassing the others by a significant margin. While fine-tuning LLMs on legal specific text brings certain improvements, we are still a long way from obtaining usable and reliable LLMs in legal tasks. All data, model predictions and evaluation code are released in https://github.com/open-compass/LawBench/. We hope this benchmark provides in-depth understanding of the LLMs' domain-specified capabilities and speed up the development of LLMs in the legal domain.
Cooperative driving strategy based on naturalitic driving data and non-cooperative MPC
Oct 10, 2019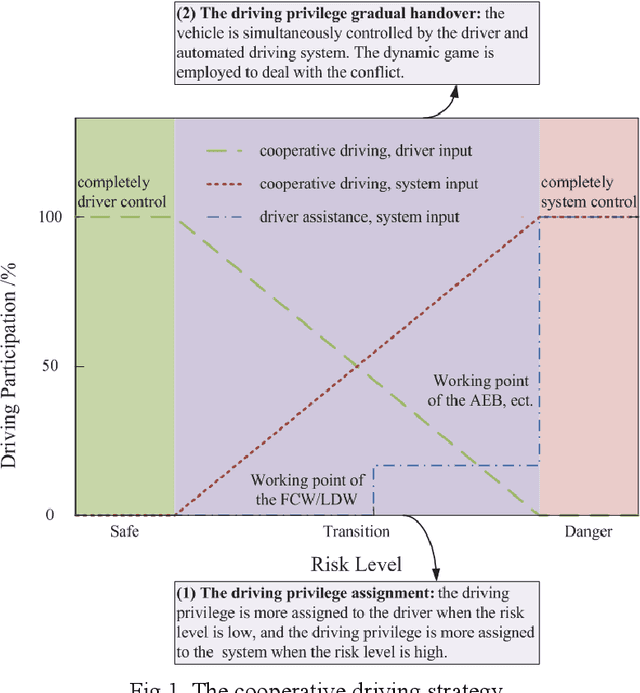
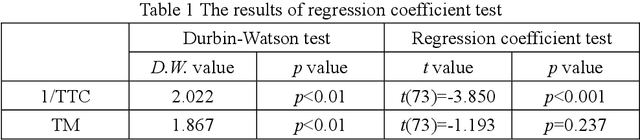

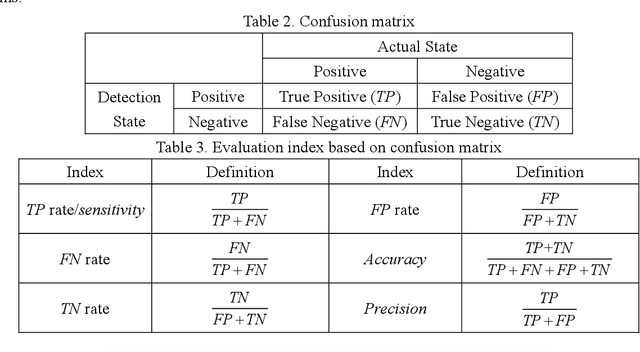
A cooperative driving strategy is proposed, in which the dynamic driving privilege assignment in real-time and the driving privilege gradual handover are realized. The first issue in cooperative driving is the driving privilege assignment based on the risk level. The risk assessment methods in 2 typical dangerous scenarios are presented, i.e. the car-following scenario and the cut-in scenario. The naturalistic driving data is used to study the behavior characteristics of the driver. TTC (time to collosion) is defined as an obvious risk measure, whereas the time before the host vehicle has to brake assuming that the target vehicle is braking is defined as the potential risk measure, i.e. the time margin (TM). A risk assessment algorithm is proposed based on the obvious risk and potential risk. The naturalistic driving data are applied to verify the effectiveness of the risk assessment algorithm. It is identified that the risk assessment algorithm performs better than TTC in the ROC (receiver operating characteristic). The second issue in cooperative driving is the driving privilege gradual handover. The vehicle is jointly controlled by the driver and automated driving system during the driving privilege gradual handover. The non-cooperative MPC (model predictive control) is employed to resolve the conflicts between the driver and automated driving system. It is identified that the Nash equilibrium of the non-cooperative MPC can be achieved by using a non-iterative method. The driving privilege gradual handover is realized by using the confidence matrixes update. The simulation verification shows that the the cooperative driving strategy can realize the gradual handover of the driving privilege between the driver and automated system, and the cooperative driving strategy can dynamically assige the driving privilege in real-time according to the risk level.