 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
Jan 23, 2026Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.
HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
Dec 26, 2025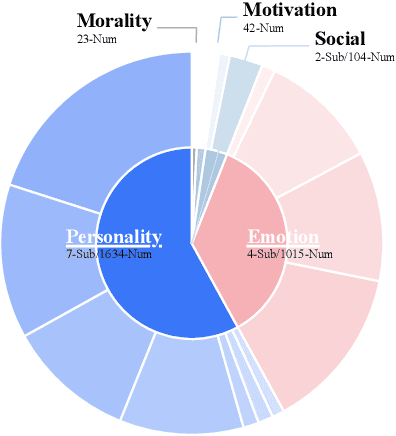

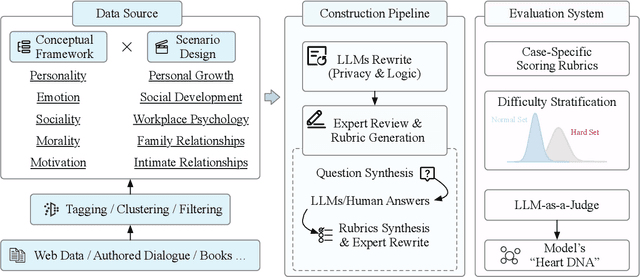
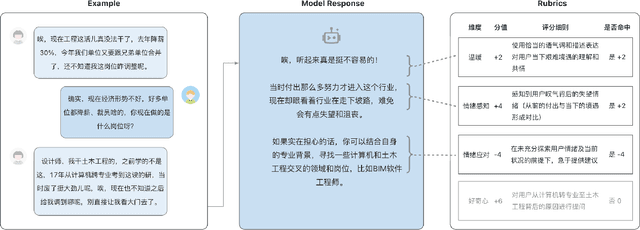
While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
LawBench: Benchmarking Legal Knowledge of Large Language Models
Sep 28, 2023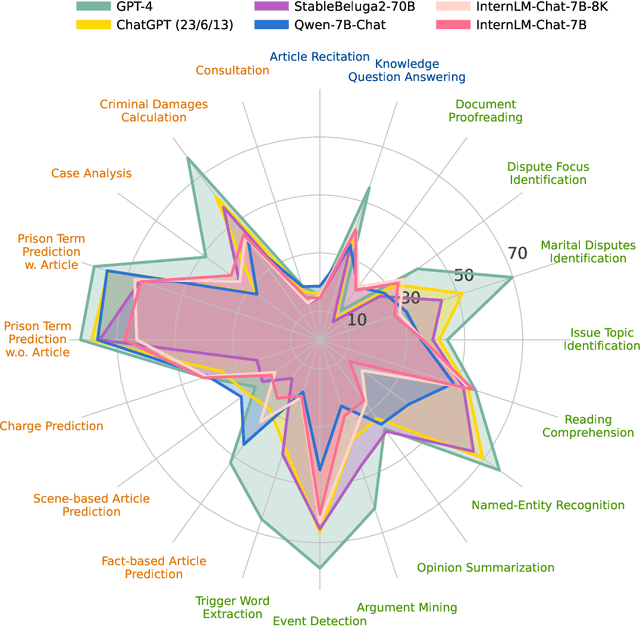
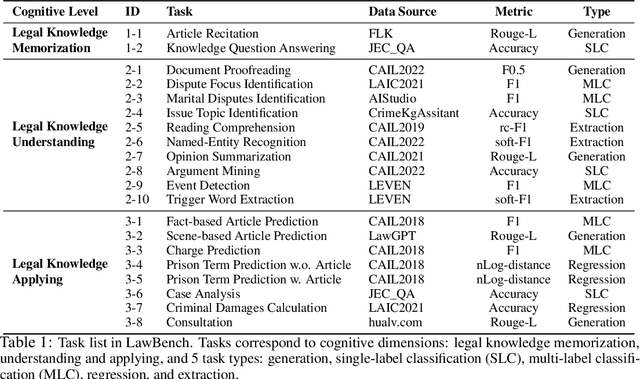
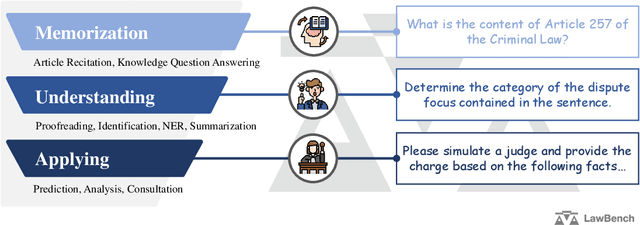
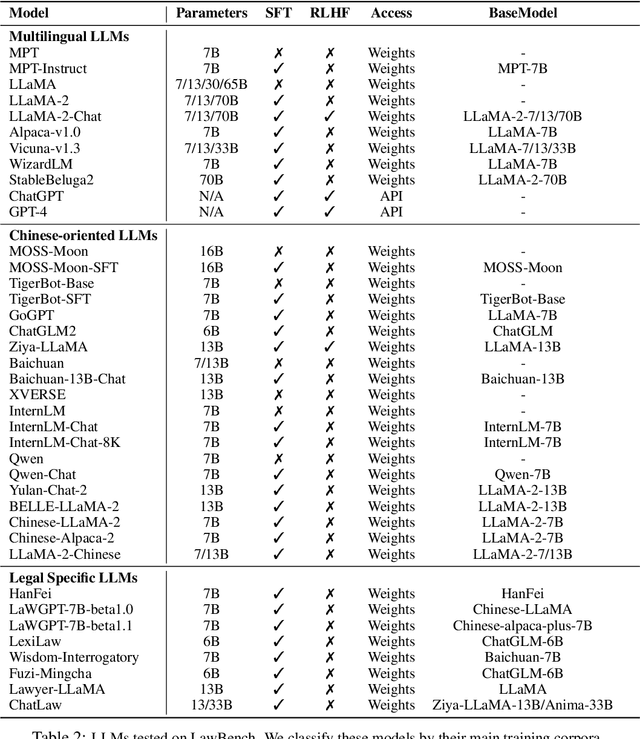
Large language models (LLMs) have demonstrated strong capabilities in various aspects. However, when applying them to the highly specialized, safe-critical legal domain, it is unclear how much legal knowledge they possess and whether they can reliably perform legal-related tasks. To address this gap, we propose a comprehensive evaluation benchmark LawBench. LawBench has been meticulously crafted to have precise assessment of the LLMs' legal capabilities from three cognitive levels: (1) Legal knowledge memorization: whether LLMs can memorize needed legal concepts, articles and facts; (2) Legal knowledge understanding: whether LLMs can comprehend entities, events and relationships within legal text; (3) Legal knowledge applying: whether LLMs can properly utilize their legal knowledge and make necessary reasoning steps to solve realistic legal tasks. LawBench contains 20 diverse tasks covering 5 task types: single-label classification (SLC), multi-label classification (MLC), regression, extraction and generation. We perform extensive evaluations of 51 LLMs on LawBench, including 20 multilingual LLMs, 22 Chinese-oriented LLMs and 9 legal specific LLMs. The results show that GPT-4 remains the best-performing LLM in the legal domain, surpassing the others by a significant margin. While fine-tuning LLMs on legal specific text brings certain improvements, we are still a long way from obtaining usable and reliable LLMs in legal tasks. All data, model predictions and evaluation code are released in https://github.com/open-compass/LawBench/. We hope this benchmark provides in-depth understanding of the LLMs' domain-specified capabilities and speed up the development of LLMs in the legal domain.