 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fine-grained Fact-Article Correspondence in Legal Cases
Paper and Code


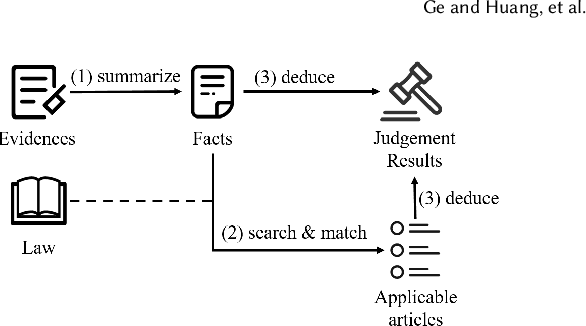

Automatically recommending relevant law articles to a given legal case has attracted much attention as it can greatly release human labor from searching over the large database of laws. However, current researches only support coarse-grained recommendation where all relevant articles are predicted as a whole without explaining which specific fact each article is relevant with. Since one case can be formed of many supporting facts, traversing over them to verify the correctness of recommendation results can be time-consuming. We believe that learning fine-grained correspondence between each single fact and law articles is crucial for an accurate and trustworthy AI system. With this motivation, we perform a pioneering study and create a corpus with manually annotated fact-article correspondences. We treat the learning as a text matching task and propose a multi-level matching network to address it. To help the model better digest the content of law articles, we parse articles in form of premise-conclusion pairs with random forest. Experiments show that the parsed form yielded better performance and the resulting model surpassed other popular text matching baselines. Furthermore, we compare with previous researches and find that establishing the fine-grained fact-article correspondences can improve the recommendation accuracy by a large margin. Our best system reaches an F1 score of 96.3%, making it of great potential for practical use. It can also significantly boost the downstream task of legal decision prediction, increasing the F1 score by up to 12.7%.