 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Clustered Cross-Covariance Control for Offline RL
Jan 28, 2026A fundamental challenge in offline reinforcement learning is distributional shift. Scarce data or datasets dominated by out-of-distribution (OOD) areas exacerbate this issue. Our theoretical analysis and experiments show that the standard squared error objective induces a harmful TD cross covariance. This effect amplifies in OOD areas, biasing optimization and degrading policy learning. To counteract this mechanism, we develop two complementary strategies: partitioned buffer sampling that restricts updates to localized replay partitions, attenuates irregular covariance effects, and aligns update directions, yielding a scheme that is easy to integrate with existing implementations, namely Clustered Cross-Covariance Control for TD (C^4). We also introduce an explicit gradient-based corrective penalty that cancels the covariance induced bias within each update. We prove that buffer partitioning preserves the lower bound property of the maximization objective, and that these constraints mitigate excessive conservatism in extreme OOD areas without altering the core behavior of policy constrained offline reinforcement learning. Empirically, our method showcases higher stability and up to 30% improvement in returns over prior methods, especially with small datasets and splits that emphasize OOD areas.
ConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.
AugFL: Augmenting Federated Learning with Pretrained Models
Mar 04, 2025Federated Learning (FL) has garnered widespread interest in recent years. However, owing to strict privacy policies or limited storage capacities of training participants such as IoT devices, its effective deployment is often impeded by the scarcity of training data in practical decentralized learning environments. In this paper, we study enhancing FL with the aid of (large) pre-trained models (PMs), that encapsulate wealthy general/domain-agnostic knowledge, to alleviate the data requirement in conducting FL from scratch. Specifically, we consider a networked FL system formed by a central server and distributed clients. First, we formulate the PM-aided personalized FL as a regularization-based federated meta-learning problem, where clients join forces to learn a meta-model with knowledge transferred from a private PM stored at the server. Then, we develop an inexact-ADMM-based algorithm, AugFL, to optimize the problem with no need to expose the PM or incur additional computational costs to local clients. Further, we establish theoretical guarantees for AugFL in terms of communication complexity, adaptation performance, and the benefit of knowledge transfer in general non-convex cases. Extensive experiments corroborate the efficacy and superiority of AugFL over existing baselines.
Federated Offline Policy Optimization with Dual Regularization
May 29, 2024Federated Reinforcement Learning (FRL) has been deemed as a promising solution for intelligent decision-making in the era of Artificial Internet of Things. However, existing FRL approaches often entail repeated interactions with the environment during local updating, which can be prohibitively expensive or even infeasible in many real-world domains. To overcome this challenge, this paper proposes a novel offline federated policy optimization algorithm, named $\texttt{DRPO}$, which enables distributed agents to collaboratively learn a decision policy only from private and static data without further environmental interactions. $\texttt{DRPO}$ leverages dual regularization, incorporating both the local behavioral policy and the global aggregated policy, to judiciously cope with the intrinsic two-tier distributional shifts in offline FRL. Theoretical analysis characterizes the impact of the dual regularization on performance, demonstrating that by achieving the right balance thereof, $\texttt{DRPO}$ can effectively counteract distributional shifts and ensure strict policy improvement in each federative learning round. Extensive experiments validate the significant performance gains of $\texttt{DRPO}$ over baseline methods.
Mutual Enhancement of Large and Small Language Models with Cross-Silo Knowledge Transfer
Dec 10, 2023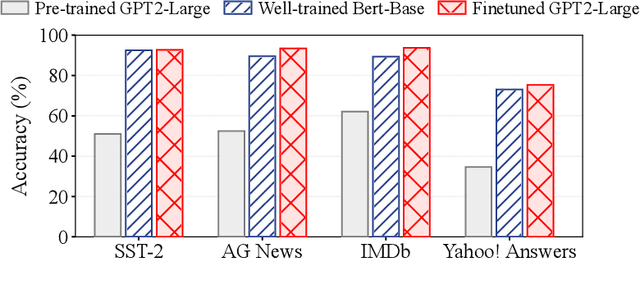



While large language models (LLMs) are empowered with broad knowledge, their task-specific performance is often suboptimal. It necessitates fine-tuning LLMs with task-specific data, but such data may be inaccessible due to privacy concerns. In this paper, we propose a novel approach to enhance LLMs with smaller language models (SLMs) that are trained on clients using their private task-specific data. To enable mutual enhancement between LLMs and SLMs, we propose CrossLM, where the SLMs promote the LLM to generate task-specific high-quality data, and both the LLM and SLMs are enhanced with the generated data. We evaluate CrossLM using publicly accessible language models across a range of benchmark tasks. The results demonstrate that CrossLM significantly enhances the task-specific performance of SLMs on clients and the LLM on the cloud server simultaneously while preserving the LLM's generalization capability.