 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.
Mutual Enhancement of Large and Small Language Models with Cross-Silo Knowledge Transfer
Dec 10, 2023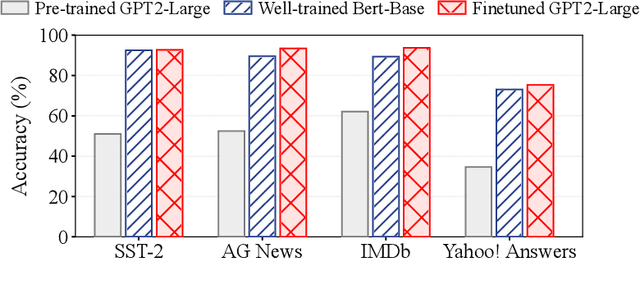



While large language models (LLMs) are empowered with broad knowledge, their task-specific performance is often suboptimal. It necessitates fine-tuning LLMs with task-specific data, but such data may be inaccessible due to privacy concerns. In this paper, we propose a novel approach to enhance LLMs with smaller language models (SLMs) that are trained on clients using their private task-specific data. To enable mutual enhancement between LLMs and SLMs, we propose CrossLM, where the SLMs promote the LLM to generate task-specific high-quality data, and both the LLM and SLMs are enhanced with the generated data. We evaluate CrossLM using publicly accessible language models across a range of benchmark tasks. The results demonstrate that CrossLM significantly enhances the task-specific performance of SLMs on clients and the LLM on the cloud server simultaneously while preserving the LLM's generalization capability.