 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE: Flexible Integration of Data Quality Ratings for Effective Pre-Training
Paper and Code
Feb 02, 2025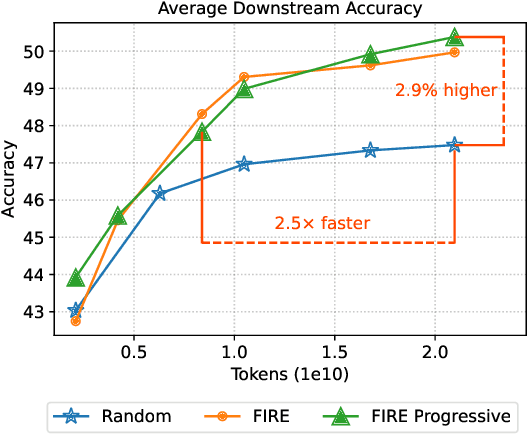
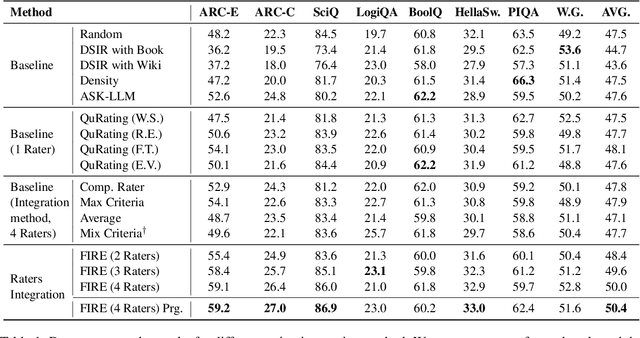
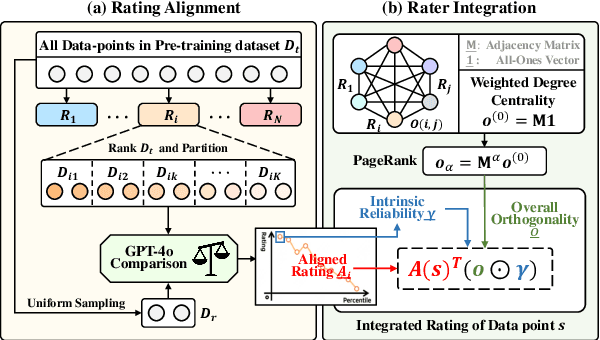

Selecting high-quality data can significantly improve the pre-training efficiency of large language models (LLMs). Existing methods often rely on heuristic techniques and single quality signals, limiting their ability to comprehensively evaluate data quality. In this work, we propose FIRE, a flexible and scalable framework for integrating multiple data quality raters, which allows for a comprehensive assessment of data quality across various dimensions. FIRE aligns multiple quality signals into a unified space, and integrates diverse data quality raters to provide a comprehensive quality signal for each data point. Further, we introduce a progressive data selection scheme based on FIRE that iteratively refines the selection of high-quality data points, balancing computational complexity with the refinement of orthogonality. Experiments on the SlimPajama dataset reveal that FIRE consistently outperforms other selection methods and significantly enhances the pre-trained model across a wide range of downstream tasks, with a 2.9\% average performance boost and reducing the FLOPs necessary to achieve a certain performance level by more than half.