 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on LLM Mid-training
Oct 27, 2025Recent advances in foundation models have highlighted the significant benefits of multi-stage training, with a particular emphasis on the emergence of mid-training as a vital stage that bridges pre-training and post-training. Mid-training is distinguished by its use of intermediate data and computational resources, systematically enhancing specified capabilities such as mathematics, coding, reasoning, and long-context extension, while maintaining foundational competencies. This survey provides a formal definition of mid-training for large language models (LLMs) and investigates optimization frameworks that encompass data curation, training strategies, and model architecture optimization. We analyze mainstream model implementations in the context of objective-driven interventions, illustrating how mid-training serves as a distinct and critical stage in the progressive development of LLM capabilities. By clarifying the unique contributions of mid-training, this survey offers a comprehensive taxonomy and actionable insights, supporting future research and innovation in the advancement of LLMs.
Enhancing LLMs via High-Knowledge Data Selection
May 20, 2025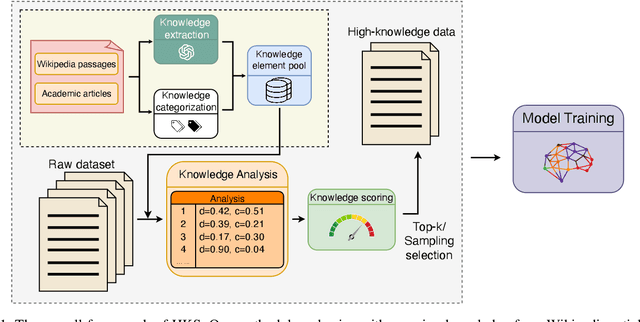
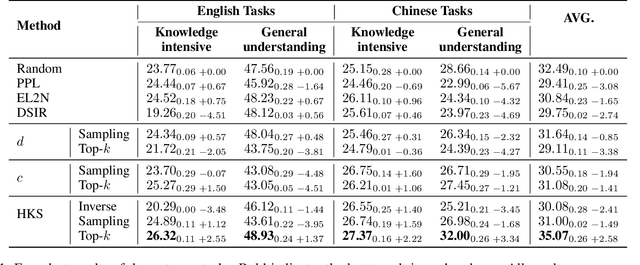
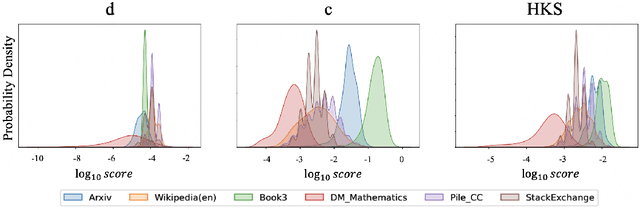
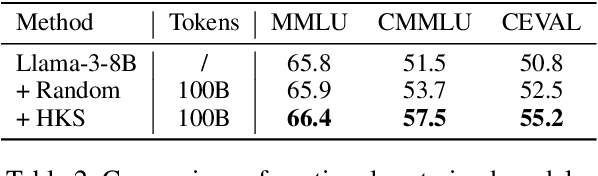
The performance of Large Language Models (LLMs) is intrinsically linked to the quality of its training data. Although several studies have proposed methods for high-quality data selection, they do not consider the importance of knowledge richness in text corpora. In this paper, we propose a novel and gradient-free High-Knowledge Scorer (HKS) to select high-quality data from the dimension of knowledge, to alleviate the problem of knowledge scarcity in the pre-trained corpus. We propose a comprehensive multi-domain knowledge element pool and introduce knowledge density and coverage as metrics to assess the knowledge content of the text. Based on this, we propose a comprehensive knowledge scorer to select data with intensive knowledge, which can also be utilized for domain-specific high-knowledge data selection by restricting knowledge elements to the specific domain. We train models on a high-knowledge bilingual dataset, and experimental results demonstrate that our scorer improves the model's performance in knowledge-intensive and general comprehension tasks, and is effective in enhancing both the generic and domain-specific capabilities of the model.
FRAMES: Boosting LLMs with A Four-Quadrant Multi-Stage Pretraining Strategy
Feb 08, 2025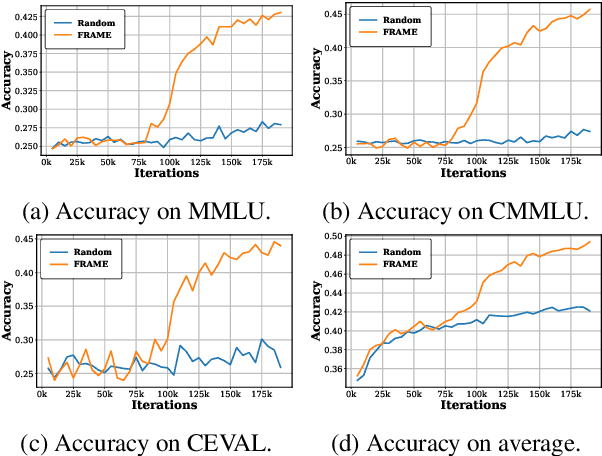
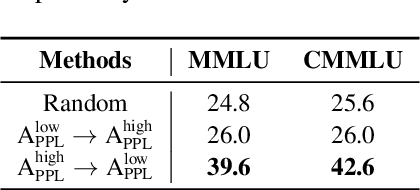
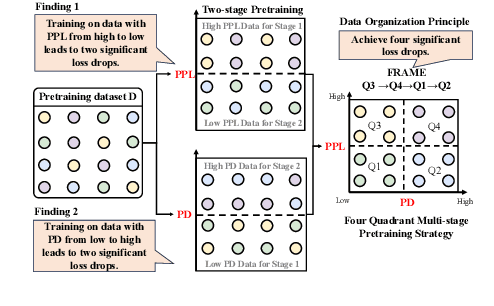
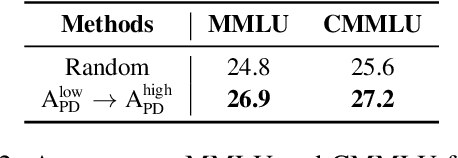
Large language models (LLMs) have significantly advanced human language understanding and generation, with pretraining data quality and organization being crucial to their performance. Multi-stage pretraining is a promising approach, but existing methods often lack quantitative criteria for data partitioning and instead rely on intuitive heuristics. In this paper, we propose the novel Four-quadRAnt Multi-stage prEtraining Strategy (FRAMES), guided by the established principle of organizing the pretraining process into four stages to achieve significant loss reductions four times. This principle is grounded in two key findings: first, training on high Perplexity (PPL) data followed by low PPL data, and second, training on low PPL difference (PD) data followed by high PD data, both causing the loss to drop significantly twice and performance enhancements. By partitioning data into four quadrants and strategically organizing them, FRAMES achieves a remarkable 16.8% average improvement over random sampling across MMLU and CMMLU, effectively boosting LLM performance.
FIRE: Flexible Integration of Data Quality Ratings for Effective Pre-Training
Feb 02, 2025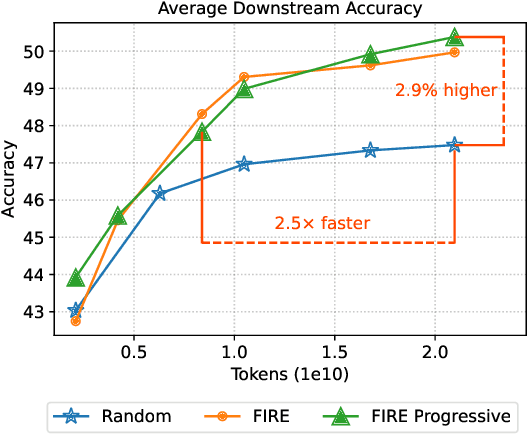
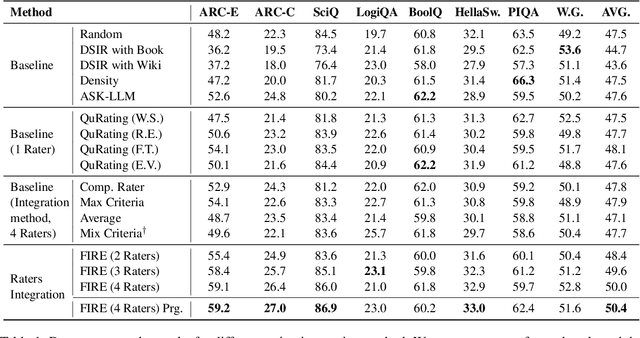
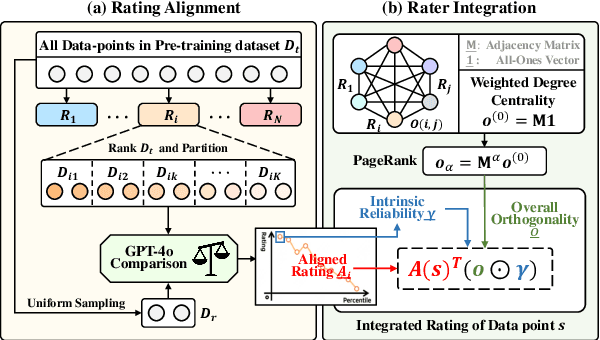

Selecting high-quality data can significantly improve the pre-training efficiency of large language models (LLMs). Existing methods often rely on heuristic techniques and single quality signals, limiting their ability to comprehensively evaluate data quality. In this work, we propose FIRE, a flexible and scalable framework for integrating multiple data quality raters, which allows for a comprehensive assessment of data quality across various dimensions. FIRE aligns multiple quality signals into a unified space, and integrates diverse data quality raters to provide a comprehensive quality signal for each data point. Further, we introduce a progressive data selection scheme based on FIRE that iteratively refines the selection of high-quality data points, balancing computational complexity with the refinement of orthogonality. Experiments on the SlimPajama dataset reveal that FIRE consistently outperforms other selection methods and significantly enhances the pre-trained model across a wide range of downstream tasks, with a 2.9\% average performance boost and reducing the FLOPs necessary to achieve a certain performance level by more than half.