 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Geometry-aware Weakly Supervised 3D Object Detection
Paper and Code
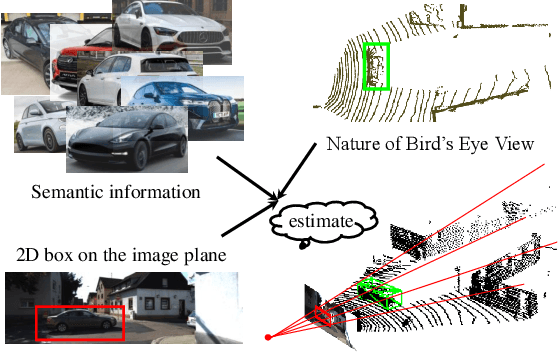
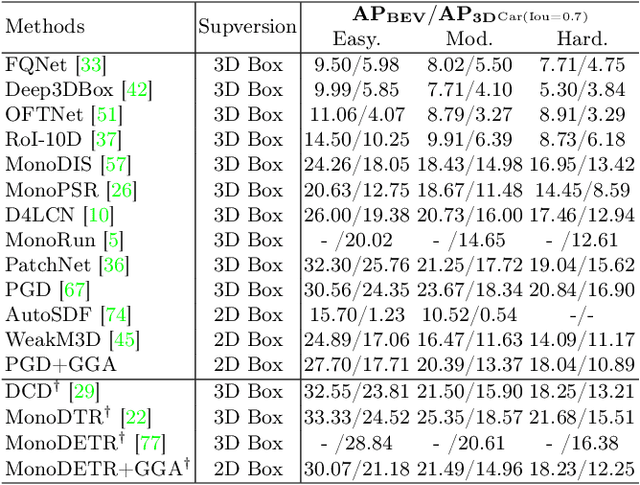

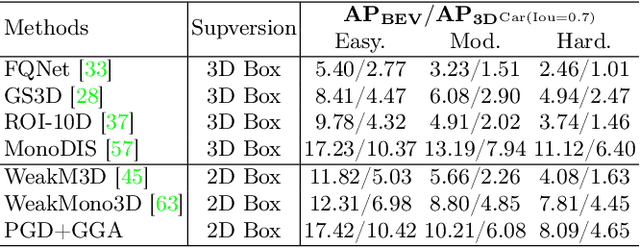
3D object detection is an indispensable component for scene understanding. However, the annotation of large-scale 3D datasets requires significant human effort. To tackle this problem, many methods adopt weakly supervised 3D object detection that estimates 3D boxes by leveraging 2D boxes and scene/class-specific priors. However, these approaches generally depend on sophisticated manual priors, which is hard to generalize to novel categories and scenes. In this paper, we are motivated to propose a general approach, which can be easily adapted to new scenes and/or classes. A unified framework is developed for learning 3D object detectors from RGB images and associated 2D boxes. In specific, we propose three general components: prior injection module to obtain general object geometric priors from LLM model, 2D space projection constraint to minimize the discrepancy between the boundaries of projected 3D boxes and their corresponding 2D boxes on the image plane, and 3D space geometry constraint to build a Point-to-Box alignment loss to further refine the pose of estimated 3D boxes. Experiments on KITTI and SUN-RGBD datasets demonstrate that our method yields surprisingly high-quality 3D bounding boxes with only 2D annotation. The source code is available at https://github.com/gwenzhang/GGA.