 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Policy Adaptation without Policy Updates
Jun 04, 2026Leveraging prior knowledge from pretrained policies, foundation models, or human operators offers an efficient alternative to learning robot skills from scratch. However, these agents often provide actions that are suboptimal, noisy, or misaligned with task-specific expert behavior. We propose GLOVES, a family of flow-based adaptation methods that correct non-expert actions by transporting them toward an expert action distribution. Rather than replacing agentic control with full autonomy, GLOVES performs selective action-level adaptation, improving task success while preserving agent intent. The learned flow also provides a natural in-distribution scoring mechanism through reverse flow evaluation. We use this signal as an intervention gate: actions that appear consistent with the expert distribution are passed through unchanged, while anomalous or out-of-distribution (OOD) actions are corrected. In this way, assistance is only provided when necessary. GLOVES requires only limited expert supervision, using a small number of demonstrations or reusable successful skill segments. By learning local expert action patterns and stitching them during execution, GLOVES provides a lightweight shared-control module for robust action adaptation across tasks and environments. Code and demos are available at ripl.github.io/GLOVES_web.
HapCompass: A Rotational Haptic Device for Contact-Rich Robotic Teleoperation
Mar 31, 2026The contact-rich nature of manipulation makes it a significant challenge for robotic teleoperation. While haptic feedback is critical for contact-rich tasks, providing intuitive directional cues within wearable teleoperation interfaces remains a bottleneck. Existing solutions, such as non-directional vibrations from handheld controllers, provide limited information, while vibrotactile arrays are prone to perceptual interference. To address these limitations, we propose HapCompass, a novel, low-cost wearable haptic device that renders 2D directional cues by mechanically rotating a single linear resonant actuator (LRA). We evaluated HapCompass's ability to convey directional cues to human operators and showed that it increased the success rate, decreased the completion time and the maximum contact force for teleoperated manipulation tasks when compared to vision-only and non-directional feedback baselines. Furthermore, we conducted a preliminary imitation-learning evaluation, suggesting that the directional feedback provided by HapCompass enhances the quality of demonstration data and, in turn, the trained policy. We release the design of the HapCompass device along with the code that implements our teleoperation interface: https://ripl.github.io/HapCompass/.
Do You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
Oct 02, 2025We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .
FlashBack: Consistency Model-Accelerated Shared Autonomy
May 22, 2025Shared autonomy is an enabling technology that provides users with control authority over robots that would otherwise be difficult if not impossible to directly control. Yet, standard methods make assumptions that limit their adoption in practice-for example, prior knowledge of the user's goals or the objective (i.e., reward) function that they wish to optimize, knowledge of the user's policy, or query-level access to the user during training. Diffusion-based approaches to shared autonomy do not make such assumptions and instead only require access to demonstrations of desired behaviors, while allowing the user to maintain control authority. However, these advantages have come at the expense of high computational complexity, which has made real-time shared autonomy all but impossible. To overcome this limitation, we propose Consistency Shared Autonomy (CSA), a shared autonomy framework that employs a consistency model-based formulation of diffusion. Key to CSA is that it employs the distilled probability flow of ordinary differential equations (PF ODE) to generate high-fidelity samples in a single step. This results in inference speeds significantly than what is possible with previous diffusion-based approaches to shared autonomy, enabling real-time assistance in complex domains with only a single function evaluation. Further, by intervening on flawed actions at intermediate states of the PF ODE, CSA enables varying levels of assistance. We evaluate CSA on a variety of challenging simulated and real-world robot control problems, demonstrating significant improvements over state-of-the-art methods both in terms of task performance and computational efficiency.
Adversarial Constrained Policy Optimization: Improving Constrained Reinforcement Learning by Adapting Budgets
Oct 28, 2024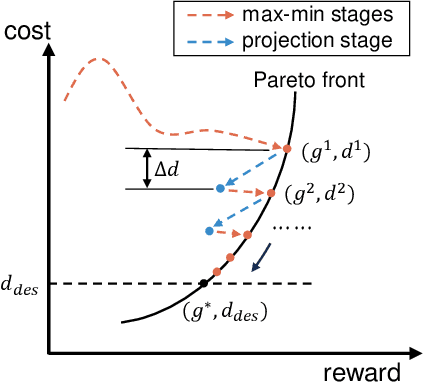
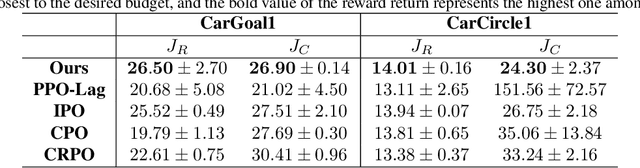
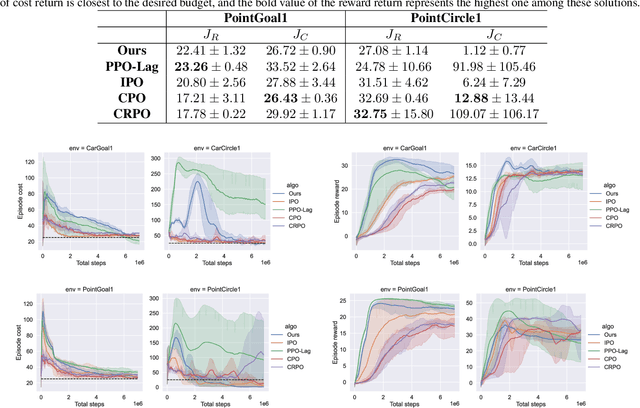
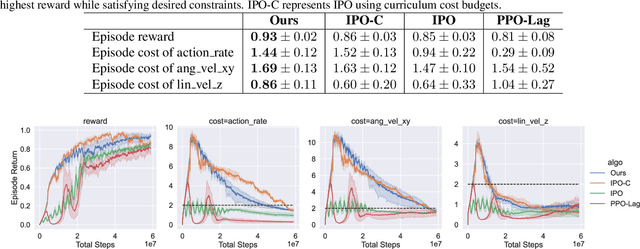
Constrained reinforcement learning has achieved promising progress in safety-critical fields where both rewards and constraints are considered. However, constrained reinforcement learning methods face challenges in striking the right balance between task performance and constraint satisfaction and it is prone for them to get stuck in over-conservative or constraint violating local minima. In this paper, we propose Adversarial Constrained Policy Optimization (ACPO), which enables simultaneous optimization of reward and the adaptation of cost budgets during training. Our approach divides original constrained problem into two adversarial stages that are solved alternately, and the policy update performance of our algorithm can be theoretically guaranteed. We validate our method through experiments conducted on Safety Gymnasium and quadruped locomotion tasks. Results demonstrate that our algorithm achieves better performances compared to commonly used baselines.
Improve Robustness of Reinforcement Learning against Observation Perturbations via $l_\infty$ Lipschitz Policy Networks
Dec 14, 2023



Deep Reinforcement Learning (DRL) has achieved remarkable advances in sequential decision tasks. However, recent works have revealed that DRL agents are susceptible to slight perturbations in observations. This vulnerability raises concerns regarding the effectiveness and robustness of deploying such agents in real-world applications. In this work, we propose a novel robust reinforcement learning method called SortRL, which improves the robustness of DRL policies against observation perturbations from the perspective of the network architecture. We employ a novel architecture for the policy network that incorporates global $l_\infty$ Lipschitz continuity and provide a convenient method to enhance policy robustness based on the output margin. Besides, a training framework is designed for SortRL, which solves given tasks while maintaining robustness against $l_\infty$ bounded perturbations on the observations. Several experiments are conducted to evaluate the effectiveness of our method, including classic control tasks and video games. The results demonstrate that SortRL achieves state-of-the-art robustness performance against different perturbation strength.