 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect before Act: Spatially Decoupled Action Repetition for Continuous Control
Feb 10, 2025Reinforcement Learning (RL) has achieved remarkable success in various continuous control tasks, such as robot manipulation and locomotion. Different to mainstream RL which makes decisions at individual steps, recent studies have incorporated action repetition into RL, achieving enhanced action persistence with improved sample efficiency and superior performance. However, existing methods treat all action dimensions as a whole during repetition, ignoring variations among them. This constraint leads to inflexibility in decisions, which reduces policy agility with inferior effectiveness. In this work, we propose a novel repetition framework called SDAR, which implements Spatially Decoupled Action Repetition through performing closed-loop act-or-repeat selection for each action dimension individually. SDAR achieves more flexible repetition strategies, leading to an improved balance between action persistence and diversity. Compared to existing repetition frameworks, SDAR is more sample efficient with higher policy performance and reduced action fluctuation. Experiments are conducted on various continuous control scenarios, demonstrating the effectiveness of spatially decoupled repetition design proposed in this work.
Improve Robustness of Reinforcement Learning against Observation Perturbations via $l_\infty$ Lipschitz Policy Networks
Dec 14, 2023



Deep Reinforcement Learning (DRL) has achieved remarkable advances in sequential decision tasks. However, recent works have revealed that DRL agents are susceptible to slight perturbations in observations. This vulnerability raises concerns regarding the effectiveness and robustness of deploying such agents in real-world applications. In this work, we propose a novel robust reinforcement learning method called SortRL, which improves the robustness of DRL policies against observation perturbations from the perspective of the network architecture. We employ a novel architecture for the policy network that incorporates global $l_\infty$ Lipschitz continuity and provide a convenient method to enhance policy robustness based on the output margin. Besides, a training framework is designed for SortRL, which solves given tasks while maintaining robustness against $l_\infty$ bounded perturbations on the observations. Several experiments are conducted to evaluate the effectiveness of our method, including classic control tasks and video games. The results demonstrate that SortRL achieves state-of-the-art robustness performance against different perturbation strength.
Accelerating Monte Carlo Tree Search with Probability Tree State Abstraction
Oct 10, 2023Monte Carlo Tree Search (MCTS) algorithms such as AlphaGo and MuZero have achieved superhuman performance in many challenging tasks. However, the computational complexity of MCTS-based algorithms is influenced by the size of the search space. To address this issue, we propose a novel probability tree state abstraction (PTSA) algorithm to improve the search efficiency of MCTS. A general tree state abstraction with path transitivity is defined. In addition, the probability tree state abstraction is proposed for fewer mistakes during the aggregation step. Furthermore, the theoretical guarantees of the transitivity and aggregation error bound are justified. To evaluate the effectiveness of the PTSA algorithm, we integrate it with state-of-the-art MCTS-based algorithms, such as Sampled MuZero and Gumbel MuZero. Experimental results on different tasks demonstrate that our method can accelerate the training process of state-of-the-art algorithms with 10%-45% search space reduction.
Capability Iteration Network for Robot Path Planning
Apr 29, 2021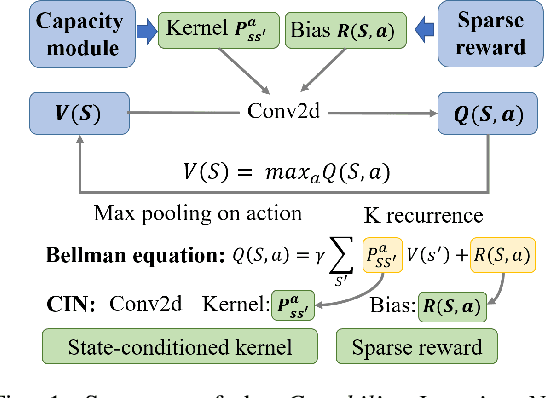
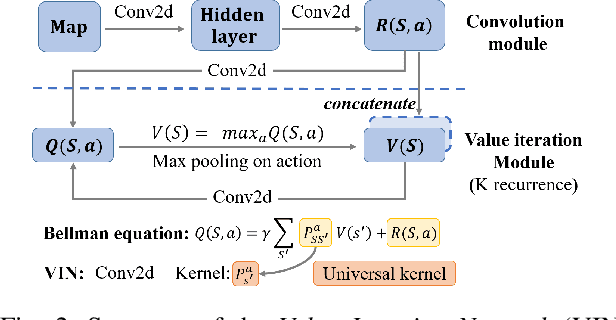
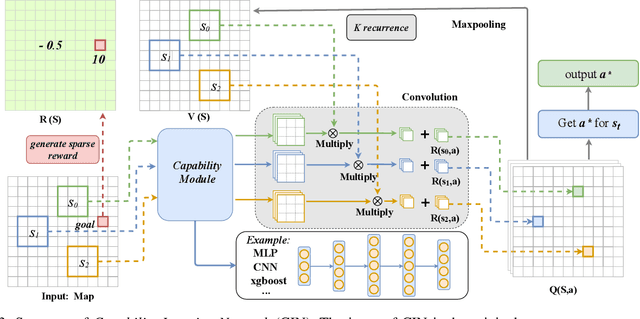
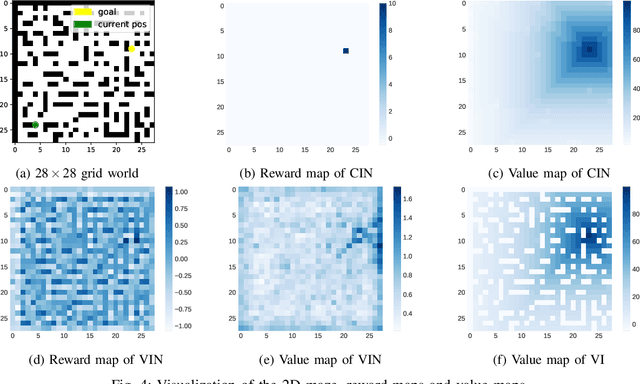
Path planning is an important topic in robotics. Recently, value iteration based deep learning models have achieved good performance such as Value Iteration Network(VIN). However, previous methods suffer from slow convergence and low accuracy on large maps, hence restricted in path planning for agents with complex kinematics such as legged robots. Therefore, we propose a new value iteration based path planning method called Capability Iteration Network(CIN). CIN utilizes sparse reward maps and encodes the capability of the agent with state-action transition probability, rather than a convolution kernel in previous models. Furthermore, two training methods including end-to-end training and training capability module alone are proposed, both of which speed up convergence greatly. Several path planning experiments in various scenarios, including on 2D, 3D grid world and real robots with different map sizes are conducted. The results demonstrate that CIN has higher accuracy, faster convergence, and lower sensitivity to random seed compared to previous VI-based models, hence more applicable for real robot path planning.