 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Cognitive Assessment Scores in Older Adults with Cognitive Impairment Using Wearable Sensors
Nov 07, 2025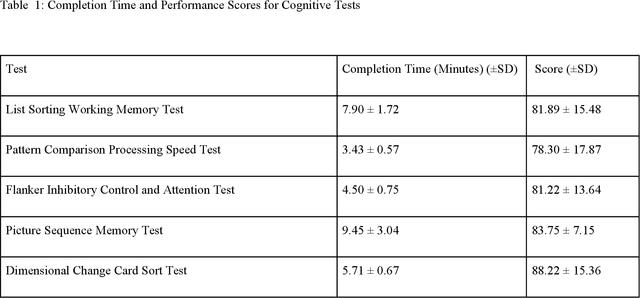
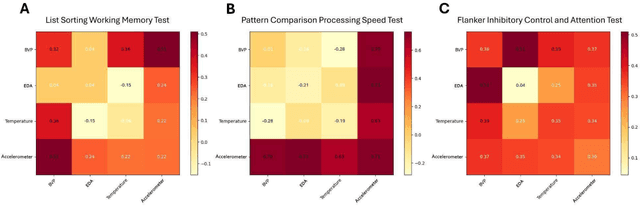
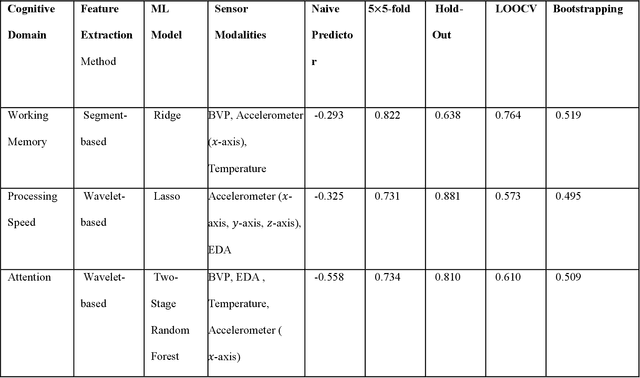
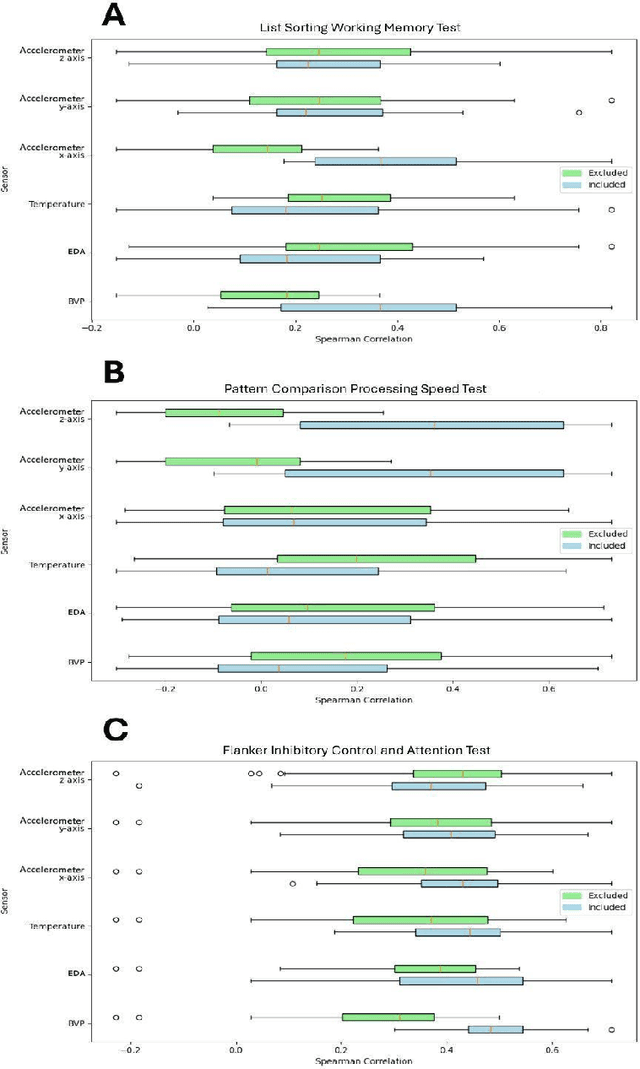
Background and Objectives: This paper focuses on using AI to assess the cognitive function of older adults with mild cognitive impairment or mild dementia using physiological data provided by a wearable device. Cognitive screening tools are disruptive, time-consuming, and only capture brief snapshots of activity. Wearable sensors offer an attractive alternative by continuously monitoring physiological signals. This study investigated whether physiological data can accurately predict scores on established cognitive tests. Research Design and Methods: We recorded physiological signals from 23 older adults completing three NIH Toolbox Cognitive Battery tests, which assess working memory, processing speed, and attention. The Empatica EmbracePlus, a wearable device, measured blood volume pulse, skin conductance, temperature, and movement. Statistical features were extracted using wavelet-based and segmentation methods. We then applied supervised learning and validated predictions via cross-validation, hold-out testing, and bootstrapping. Results: Our models showed strong performance with Spearman's ρof 0.73-0.82 and mean absolute errors of 0.14-0.16, significantly outperforming a naive mean predictor. Sensor roles varied: heart-related signals combined with movement and temperature best predicted working memory, movement paired with skin conductance was most informative for processing speed, and heart in tandem with skin conductance worked best for attention. Discussion and Implications: These findings suggest that wearable sensors paired with AI tools such as supervised learning and feature engineering can noninvasively track specific cognitive functions in older adults, enabling continuous monitoring. Our study demonstrates how AI can be leveraged when the data sample is small. This approach may support remote assessments and facilitate clinical interventions.
From Vague Instructions to Task Plans: A Feedback-Driven HRC Task Planning Framework based on LLMs
Mar 02, 2025



Recent advances in large language models (LLMs) have demonstrated their potential as planners in human-robot collaboration (HRC) scenarios, offering a promising alternative to traditional planning methods. LLMs, which can generate structured plans by reasoning over natural language inputs, have the ability to generalize across diverse tasks and adapt to human instructions. This paper investigates the potential of LLMs to facilitate planning in the context of human-robot collaborative tasks, with a focus on their ability to reason from high-level, vague human inputs, and fine-tune plans based on real-time feedback. We propose a novel hybrid framework that combines LLMs with human feedback to create dynamic, context-aware task plans. Our work also highlights how a single, concise prompt can be used for a wide range of tasks and environments, overcoming the limitations of long, detailed structured prompts typically used in prior studies. By integrating user preferences into the planning loop, we ensure that the generated plans are not only effective but aligned with human intentions.
Interpreting Deepcode, a learned feedback code
Apr 26, 2024



Deep learning methods have recently been used to construct non-linear codes for the additive white Gaussian noise (AWGN) channel with feedback. However, there is limited understanding of how these black-box-like codes with many learned parameters use feedback. This study aims to uncover the fundamental principles underlying the first deep-learned feedback code, known as Deepcode, which is based on an RNN architecture. Our interpretable model based on Deepcode is built by analyzing the influence length of inputs and approximating the non-linear dynamics of the original black-box RNN encoder. Numerical experiments demonstrate that our interpretable model -- which includes both an encoder and a decoder -- achieves comparable performance to Deepcode while offering an interpretation of how it employs feedback for error correction.
Sensory Glove-Based Surgical Robot User Interface
Mar 20, 2024



Robotic surgery has reached a high level of maturity and has become an integral part of standard surgical care. However, existing surgeon consoles are bulky and take up valuable space in the operating room, present challenges for surgical team coordination, and their proprietary nature makes it difficult to take advantage of recent technological advances, especially in virtual and augmented reality. One potential area for further improvement is the integration of modern sensory gloves into robotic platforms, allowing surgeons to control robotic arms directly with their hand movements intuitively. We propose one such system that combines an HTC Vive tracker, a Manus Meta Prime 3 XR sensory glove, and God Vision wireless smart glasses. The system controls one arm of a da Vinci surgical robot. In addition to moving the arm, the surgeon can use fingers to control the end-effector of the surgical instrument. Hand gestures are used to implement clutching and similar functions. In particular, we introduce clutching of the instrument orientation, a functionality not available in the da Vinci system. The vibrotactile elements of the glove are used to provide feedback to the user when gesture commands are invoked. A preliminary evaluation of the system shows that it has excellent tracking accuracy and allows surgeons to efficiently perform common surgical training tasks with minimal practice with the new interface; this suggests that the interface is highly intuitive. The proposed system is inexpensive, allows rapid prototyping, and opens opportunities for further innovations in the design of surgical robot interfaces.
Comprehensive Robotic Cholecystectomy Dataset (CRCD): Integrating Kinematics, Pedal Signals, and Endoscopic Videos
Dec 02, 2023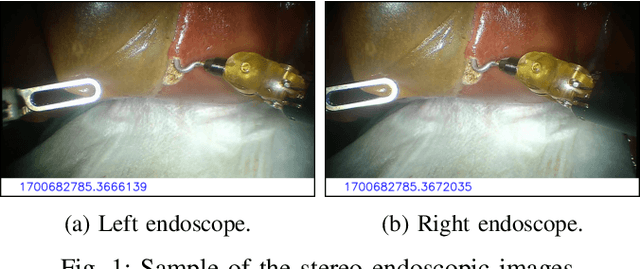


In recent years, the potential applications of machine learning to Minimally Invasive Surgery (MIS) have spurred interest in data sets that can be used to develop data-driven tools. This paper introduces a novel dataset recorded during ex vivo pseudo-cholecystectomy procedures on pig livers, utilizing the da Vinci Research Kit (dVRK). Unlike current datasets, ours bridges a critical gap by offering not only full kinematic data but also capturing all pedal inputs used during the procedure and providing a time-stamped record of the endoscope's movements. Contributed by seven surgeons, this data set introduces a new dimension to surgical robotics research, allowing the creation of advanced models for automating console functionalities. Our work addresses the existing limitation of incomplete recordings and imprecise kinematic data, common in other datasets. By introducing two models, dedicated to predicting clutch usage and camera activation, we highlight the dataset's potential for advancing automation in surgical robotics. The comparison of methodologies and time windows provides insights into the models' boundaries and limitations.
Proactive Robot Control for Collaborative Manipulation Using Human Intent
Nov 06, 2023



Collaborative manipulation task often requires negotiation using explicit or implicit communication. An important example is determining where to move when the goal destination is not uniquely specified, and who should lead the motion. This work is motivated by the ability of humans to communicate the desired destination of motion through back-and-forth force exchanges. Inherent to these exchanges is also the ability to dynamically assign a role to each participant, either taking the initiative or deferring to the partner's lead. In this paper, we propose a hierarchical robot control framework that emulates human behavior in communicating a motion destination to a human collaborator and in responding to their actions. At the top level, the controller consists of a set of finite-state machines corresponding to different levels of commitment of the robot to its desired goal configuration. The control architecture is loosely based on the human strategy observed in the human-human experiments, and the key component is a real-time intent recognizer that helps the robot respond to human actions. We describe the details of the control framework, and feature engineering and training process of the intent recognition. The proposed controller was implemented on a UR10e robot (Universal Robots) and evaluated through human studies. The experiments show that the robot correctly recognizes and responds to human input, communicates its intent clearly, and resolves conflict. We report success rates and draw comparisons with human-human experiments to demonstrate the effectiveness of the approach.
A Framework For Automated Dissection Along Tissue Boundary
Oct 14, 2023



Robotic surgery promises enhanced precision and adaptability over traditional surgical methods. It also offers the possibility of automating surgical interventions, resulting in reduced stress on the surgeon, better surgical outcomes, and lower costs. Cholecystectomy, the removal of the gallbladder, serves as an ideal model procedure for automation due to its distinct and well-contrasted anatomical features between the gallbladder and liver, along with standardized surgical maneuvers. Dissection is a frequently used subtask in cholecystectomy where the surgeon delivers the energy on the hook to detach the gallbladder from the liver. Hence, dissection along tissue boundaries is a good candidate for surgical automation. For the da Vinci surgical robot to perform the same procedure as a surgeon automatically, it needs to have the ability to (1) recognize and distinguish between the two different tissues (e.g. the liver and the gallbladder), (2) understand where the boundary between the two tissues is located in the 3D workspace, (3) locate the instrument tip relative to the boundary in the 3D space using visual feedback, and (4) move the instrument along the boundary. This paper presents a novel framework that addresses these challenges through AI-assisted image processing and vision-based robot control. We also present the ex-vivo evaluation of the automated procedure on chicken and pork liver specimens that demonstrates the effectiveness of the proposed framework.
Recognizing Intent in Collaborative Manipulation
Aug 17, 2023



Collaborative manipulation is inherently multimodal, with haptic communication playing a central role. When performed by humans, it involves back-and-forth force exchanges between the participants through which they resolve possible conflicts and determine their roles. Much of the existing work on collaborative human-robot manipulation assumes that the robot follows the human. But for a robot to match the performance of a human partner it needs to be able to take initiative and lead when appropriate. To achieve such human-like performance, the robot needs to have the ability to (1) determine the intent of the human, (2) clearly express its own intent, and (3) choose its actions so that the dyad reaches consensus. This work proposes a framework for recognizing human intent in collaborative manipulation tasks using force exchanges. Grounded in a dataset collected during a human study, we introduce a set of features that can be computed from the measured signals and report the results of a classifier trained on our collected human-human interaction data. Two metrics are used to evaluate the intent recognizer: overall accuracy and the ability to correctly identify transitions. The proposed recognizer shows robustness against the variations in the partner's actions and the confounding effects due to the variability in grasp forces and dynamic effects of walking. The results demonstrate that the proposed recognizer is well-suited for implementation in a physical interaction control scheme.
Robots Taking Initiative in Collaborative Object Manipulation: Lessons from Physical Human-Human Interaction
Apr 24, 2023
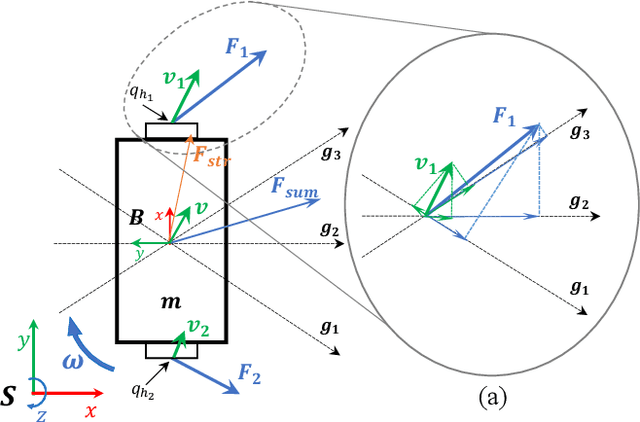
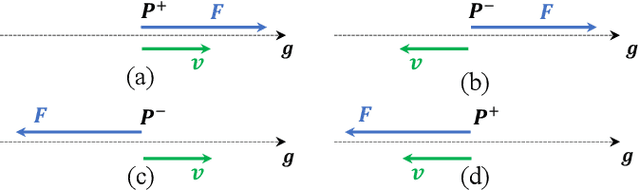
Physical Human-Human Interaction (pHHI) involves the use of multiple sensory modalities. Studies of communication through spoken utterances and gestures are well established. Nevertheless, communication through force signals is not well understood. In this paper, we focus on investigating the mechanisms employed by humans during the negotiation through force signals, which is an integral part of successful collaboration. Our objective is to use the insights to inform the design of controllers for robot assistants. Specifically, we want to enable robots to take the lead in collaboration. To achieve this goal, we conducted a study to observe how humans behave during collaborative manipulation tasks. During our preliminary data analysis, we discovered several new features that help us better understand how the interaction progresses. From these features, we identified distinct patterns in the data that indicate when a participant is expressing their intent. Our study provides valuable insight into how humans collaborate physically, which can help us design robots that behave more like humans in such scenarios.
An End-to-End Human Simulator for Task-Oriented Multimodal Human-Robot Collaboration
Apr 02, 2023This paper proposes a neural network-based user simulator that can provide a multimodal interactive environment for training Reinforcement Learning (RL) agents in collaborative tasks involving multiple modes of communication. The simulator is trained on the existing ELDERLY-AT-HOME corpus and accommodates multiple modalities such as language, pointing gestures, and haptic-ostensive actions. The paper also presents a novel multimodal data augmentation approach, which addresses the challenge of using a limited dataset due to the expensive and time-consuming nature of collecting human demonstrations. Overall, the study highlights the potential for using RL and multimodal user simulators in developing and improving domestic assistive robots.