 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Human Simulator for Task-Oriented Multimodal Human-Robot Collaboration
Apr 02, 2023This paper proposes a neural network-based user simulator that can provide a multimodal interactive environment for training Reinforcement Learning (RL) agents in collaborative tasks involving multiple modes of communication. The simulator is trained on the existing ELDERLY-AT-HOME corpus and accommodates multiple modalities such as language, pointing gestures, and haptic-ostensive actions. The paper also presents a novel multimodal data augmentation approach, which addresses the challenge of using a limited dataset due to the expensive and time-consuming nature of collecting human demonstrations. Overall, the study highlights the potential for using RL and multimodal user simulators in developing and improving domestic assistive robots.
Multimodal Reinforcement Learning for Robots Collaborating with Humans
Mar 13, 2023

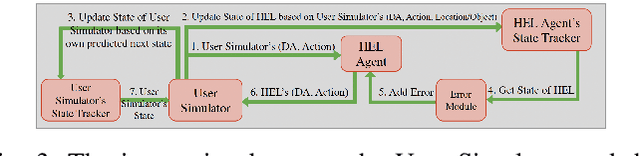

Robot assistants for older adults and people with disabilities need to interact with their users in collaborative tasks. The core component of these systems is an interaction manager whose job is to observe and assess the task, and infer the state of the human and their intent to choose the best course of action for the robot. Due to the sparseness of the data in this domain, the policy for such multi-modal systems is often crafted by hand; as the complexity of interactions grows this process is not scalable. In this paper, we propose a reinforcement learning (RL) approach to learn the robot policy. In contrast to the dialog systems, our agent is trained with a simulator developed by using human data and can deal with multiple modalities such as language and physical actions. We conducted a human study to evaluate the performance of the system in the interaction with a user. Our designed system shows promising preliminary results when it is used by a real user.
Evaluating Multimodal Interaction of Robots Assisting Older Adults
Dec 20, 2022



We outline our work on evaluating robots that assist older adults by engaging with them through multiple modalities that include physical interaction. Our thesis is that to increase the effectiveness of assistive robots: 1) robots need to understand and effect multimodal actions, 2) robots should not only react to the human, they need to take the initiative and lead the task when it is necessary. We start by briefly introducing our proposed framework for multimodal interaction and then describe two different experiments with the actual robots. In the first experiment, a Baxter robot helps a human find and locate an object using the Multimodal Interaction Manager (MIM) framework. In the second experiment, a NAO robot is used in the same task, however, the roles of the robot and the human are reversed. We discuss the evaluation methods that were used in these experiments, including different metrics employed to characterize the performance of the robot in each case. We conclude by providing our perspective on the challenges and opportunities for the evaluation of assistive robots for older adults in realistic settings.
Understanding of Object Manipulation Actions Using Human Multi-Modal Sensory Data
May 16, 2019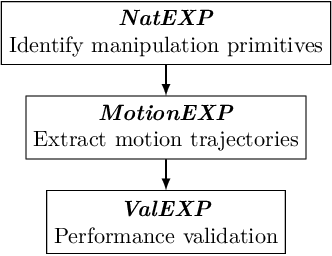
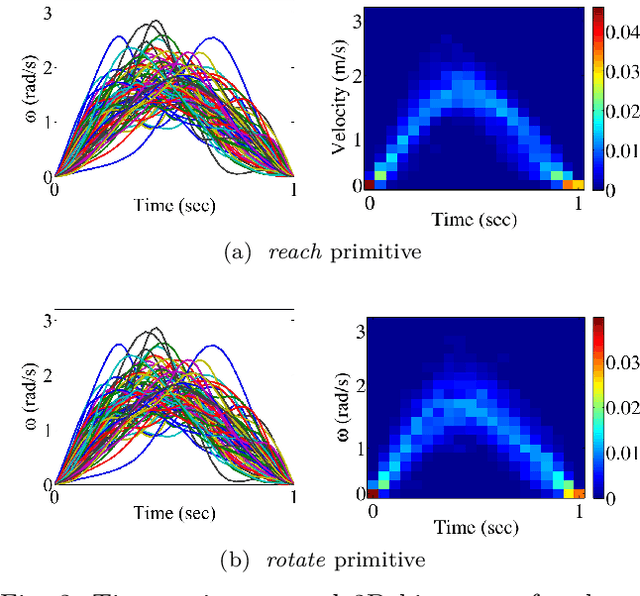
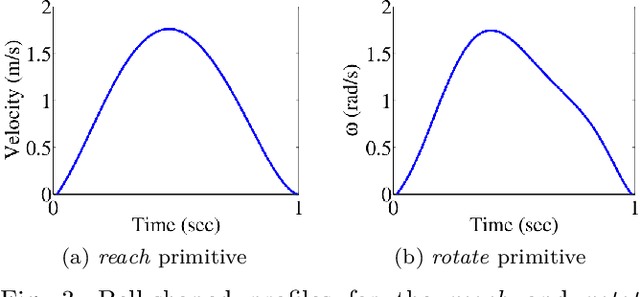

Object manipulation actions represent an important share of the Activities of Daily Living (ADLs). In this work, we study how to enable service robots to use human multi-modal data to understand object manipulation actions, and how they can recognize such actions when humans perform them during human-robot collaboration tasks. The multi-modal data in this study consists of videos, hand motion data, applied forces as represented by the pressure patterns on the hand, and measurements of the bending of the fingers, collected as human subjects performed manipulation actions. We investigate two different approaches. In the first one, we show that multi-modal signal (motion, finger bending and hand pressure) generated by the action can be decomposed into a set of primitives that can be seen as its building blocks. These primitives are used to define 24 multi-modal primitive features. The primitive features can in turn be used as an abstract representation of the multi-modal signal and employed for action recognition. In the latter approach, the visual features are extracted from the data using a pre-trained image classification deep convolutional neural network. The visual features are subsequently used to train the classifier. We also investigate whether adding data from other modalities produces a statistically significant improvement in the classifier performance. We show that both approaches produce a comparable performance. This implies that image-based methods can successfully recognize human actions during human-robot collaboration. On the other hand, in order to provide training data for the robot so it can learn how to perform object manipulation actions, multi-modal data provides a better alternative.