 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding of Object Manipulation Actions Using Human Multi-Modal Sensory Data
Paper and Code
May 16, 2019
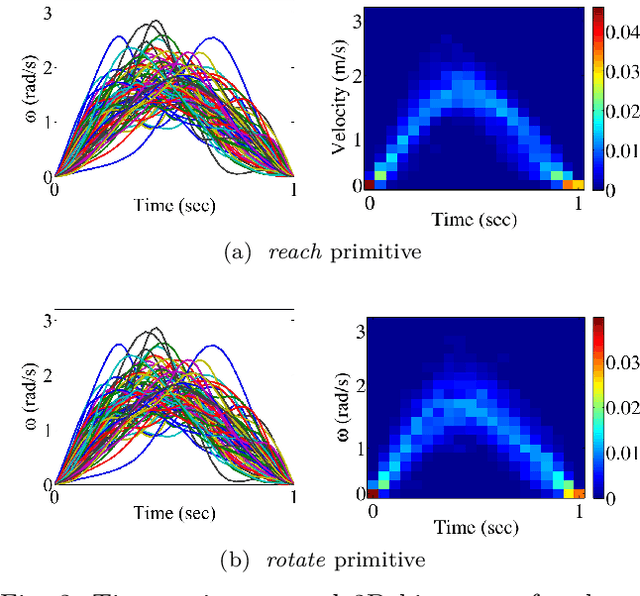
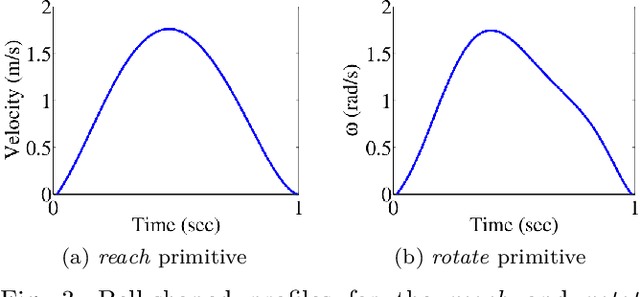

Object manipulation actions represent an important share of the Activities of Daily Living (ADLs). In this work, we study how to enable service robots to use human multi-modal data to understand object manipulation actions, and how they can recognize such actions when humans perform them during human-robot collaboration tasks. The multi-modal data in this study consists of videos, hand motion data, applied forces as represented by the pressure patterns on the hand, and measurements of the bending of the fingers, collected as human subjects performed manipulation actions. We investigate two different approaches. In the first one, we show that multi-modal signal (motion, finger bending and hand pressure) generated by the action can be decomposed into a set of primitives that can be seen as its building blocks. These primitives are used to define 24 multi-modal primitive features. The primitive features can in turn be used as an abstract representation of the multi-modal signal and employed for action recognition. In the latter approach, the visual features are extracted from the data using a pre-trained image classification deep convolutional neural network. The visual features are subsequently used to train the classifier. We also investigate whether adding data from other modalities produces a statistically significant improvement in the classifier performance. We show that both approaches produce a comparable performance. This implies that image-based methods can successfully recognize human actions during human-robot collaboration. On the other hand, in order to provide training data for the robot so it can learn how to perform object manipulation actions, multi-modal data provides a better alternative.