 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Undesirable Dependence on Frequency of Gender Bias Metrics Based on Word Embeddings
Jan 02, 2023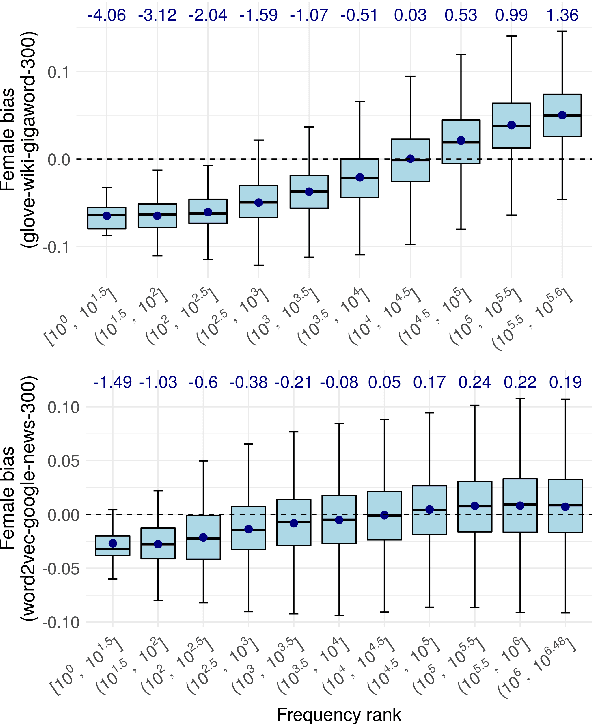


Numerous works use word embedding-based metrics to quantify societal biases and stereotypes in texts. Recent studies have found that word embeddings can capture semantic similarity but may be affected by word frequency. In this work we study the effect of frequency when measuring female vs. male gender bias with word embedding-based bias quantification methods. We find that Skip-gram with negative sampling and GloVe tend to detect male bias in high frequency words, while GloVe tends to return female bias in low frequency words. We show these behaviors still exist when words are randomly shuffled. This proves that the frequency-based effect observed in unshuffled corpora stems from properties of the metric rather than from word associations. The effect is spurious and problematic since bias metrics should depend exclusively on word co-occurrences and not individual word frequencies. Finally, we compare these results with the ones obtained with an alternative metric based on Pointwise Mutual Information. We find that this metric does not show a clear dependence on frequency, even though it is slightly skewed towards male bias across all frequencies.
The Dependence on Frequency of Word Embedding Similarity Measures
Nov 15, 2022



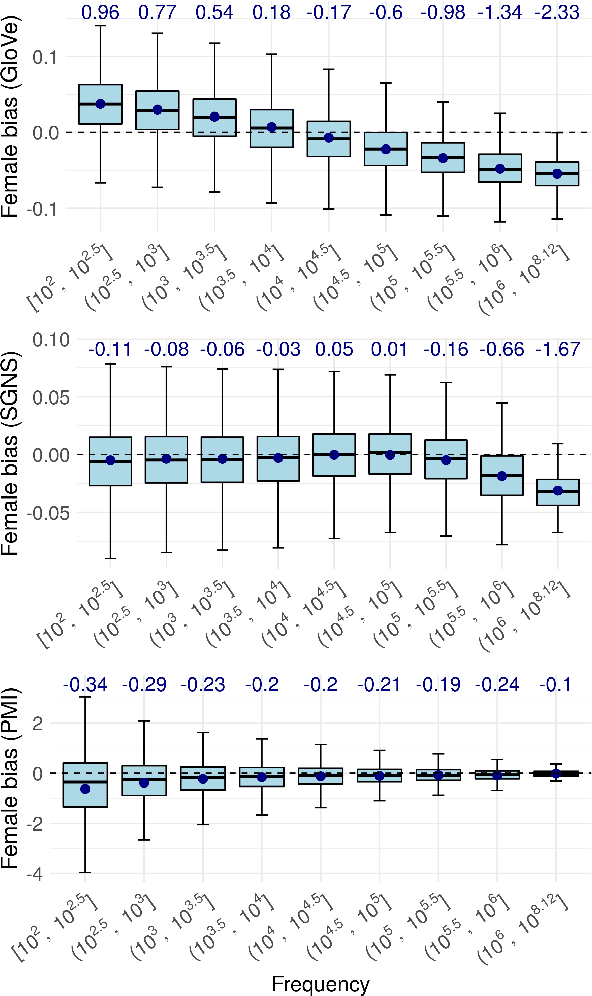
Recent research has shown that static word embeddings can encode word frequency information. However, little has been studied about this phenomenon and its effects on downstream tasks. In the present work, we systematically study the association between frequency and semantic similarity in several static word embeddings. We find that Skip-gram, GloVe and FastText embeddings tend to produce higher semantic similarity between high-frequency words than between other frequency combinations. We show that the association between frequency and similarity also appears when words are randomly shuffled. This proves that the patterns found are not due to real semantic associations present in the texts, but are an artifact produced by the word embeddings. Finally, we provide an example of how word frequency can strongly impact the measurement of gender bias with embedding-based metrics. In particular, we carry out a controlled experiment that shows that biases can even change sign or reverse their order by manipulating word frequencies.
Simple and Cheap Setup for Timing Tapping Responses Synchronized to Auditory Stimuli
Apr 30, 2021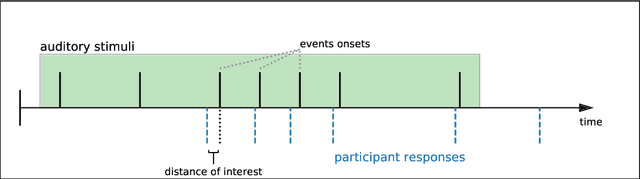
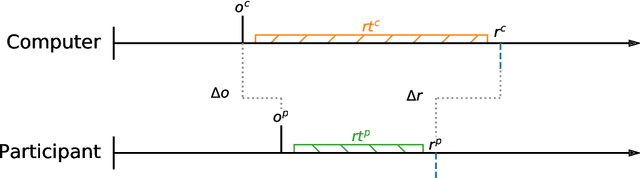

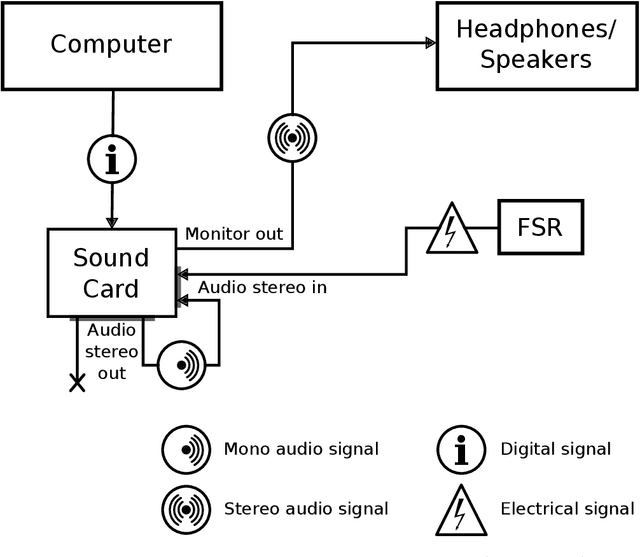
Measuring human capabilities to synchronize in time, adapt to perturbations to timing sequences or reproduce time intervals often require experimental setups that allow recording response times with millisecond precision. Most setups present auditory stimuli using either MIDI devices or specialized hardware such as Arduino and are often expensive or require calibration and advanced programming skills. Here, we present in detail an experimental setup that only requires an external sound card and minor electronic skills, works on a conventional PC, is cheaper than alternatives and requires almost no programming skills. It is intended for presenting any auditory stimuli and recording tapping response times with within 2 milliseconds precision (up to -2ms lag). This paper shows why desired accuracy in recording response times against auditory stimuli is difficult to achieve in conventional computer setups, presents an experimental setup to overcome this and explains in detail how to set it up and use the provided code. Finally, the code for analyzing the recorded tapping responses was evaluated, showing that no spurious or missing events were found in 94% of the analyzed recordings.
On the interpretation and significance of bias metrics in texts: a PMI-based approach
Apr 13, 2021
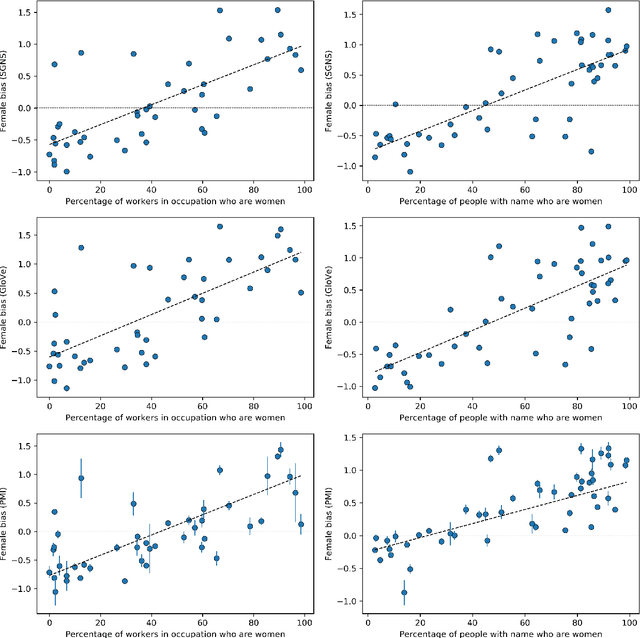

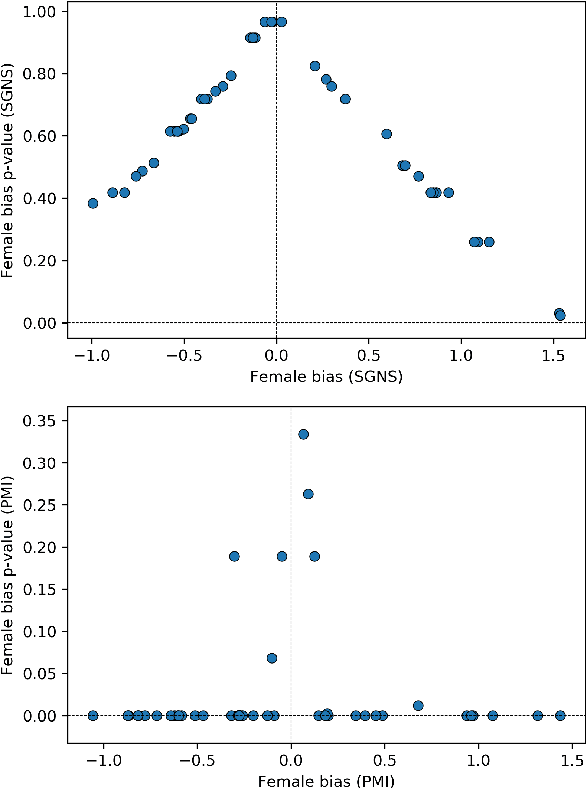
In recent years, the use of word embeddings has become popular to measure the presence of biases in texts. Despite the fact that these measures have been shown to be effective in detecting a wide variety of biases, metrics based on word embeddings lack transparency, explainability and interpretability. In this study, we propose a PMI-based metric to quantify biases in texts. We show that this metric can be approximated by an odds ratio, which allows estimating the confidence interval and statistical significance of textual bias. We also show that this PMI-based measure can be expressed as a function of conditional probabilities, providing a simple interpretation in terms of word co-occurrences. Our approach produces a performance comparable to GloVe-based and Skip-gram-based metrics in experiments of gender-occupation and gender-name associations. We discuss the advantages and disadvantages of using methods based on first-order vs second-order co-occurrences, from the point of view of the interpretability of the metric and the sparseness of the data.
Unsupervised Domain Adaptation via CycleGAN for White Matter Hyperintensity Segmentation in Multicenter MR Images
Sep 10, 2020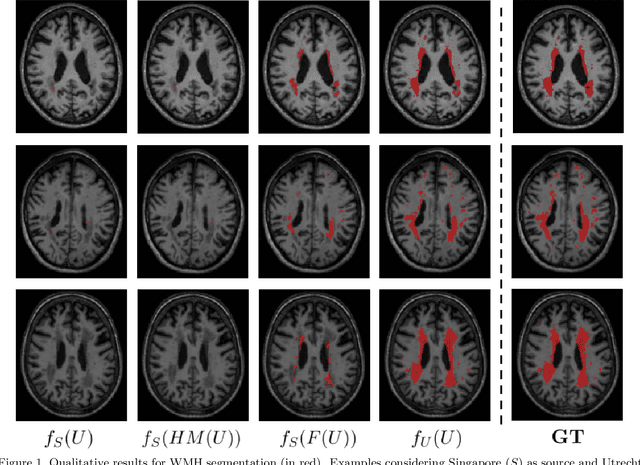
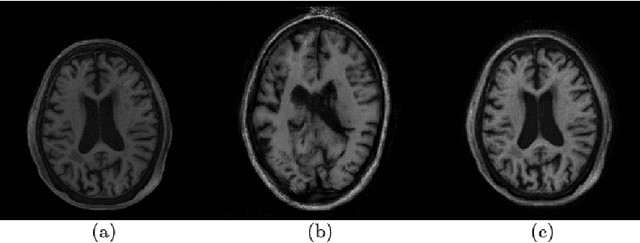

Automatic segmentation of white matter hyperintensities in magnetic resonance images is of paramount clinical and research importance. Quantification of these lesions serve as a predictor for risk of stroke, dementia and mortality. During the last years, convolutional neural networks (CNN) specifically tailored for biomedical image segmentation have outperformed all previous techniques in this task. However, they are extremely data-dependent, and maintain a good performance only when data distribution between training and test datasets remains unchanged. When such distribution changes but we still aim at performing the same task, we incur in a domain adaptation problem (e.g. using a different MR machine or different acquisition parameters for training and test data). In this work, we explore the use of cycle-consistent adversarial networks (CycleGAN) to perform unsupervised domain adaptation on multicenter MR images with brain lesions. We aim at learning a mapping function to transform volumetric MR images between domains, which are characterized by different medical centers and MR machines with varying brand, model and configuration parameters. Our experiments show that CycleGAN allows us to reduce the Jensen-Shannon divergence between MR domains, enabling automatic segmentation with CNN models on domains where no labeled data was available.
Joint Learning of Brain Lesion and Anatomy Segmentation from Heterogeneous Datasets
Apr 15, 2019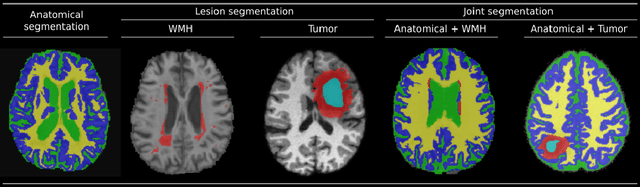

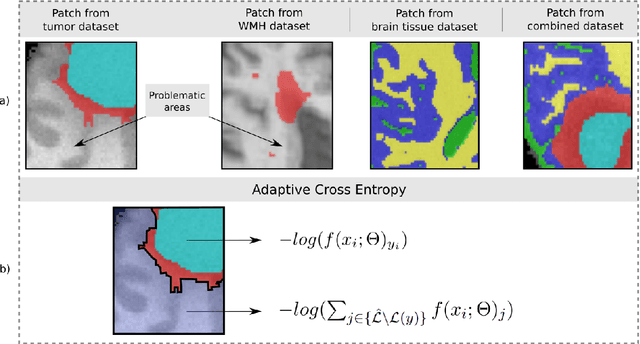
Brain lesion and anatomy segmentation in magnetic resonance images are fundamental tasks in neuroimaging research and clinical practice. Given enough training data, convolutional neuronal networks (CNN) proved to outperform all existent techniques in both tasks independently. However, to date, little work has been done regarding simultaneous learning of brain lesion and anatomy segmentation from disjoint datasets. In this work we focus on training a single CNN model to predict brain tissue and lesion segmentations using heterogeneous datasets labeled independently, according to only one of these tasks (a common scenario when using publicly available datasets). We show that label contradiction issues can arise in this case, and propose a novel adaptive cross entropy (ACE) loss function that makes such training possible. We provide quantitative evaluation in two different scenarios, benchmarking the proposed method in comparison with a multi-network approach. Our experiments suggest that ACE loss enables training of single models when standard cross entropy and Dice loss functions tend to fail. Moreover, we show that it is possible to achieve competitive results when comparing with multiple networks trained for independent tasks.
Corpus specificity in LSA and Word2vec: the role of out-of-domain documents
Dec 28, 2017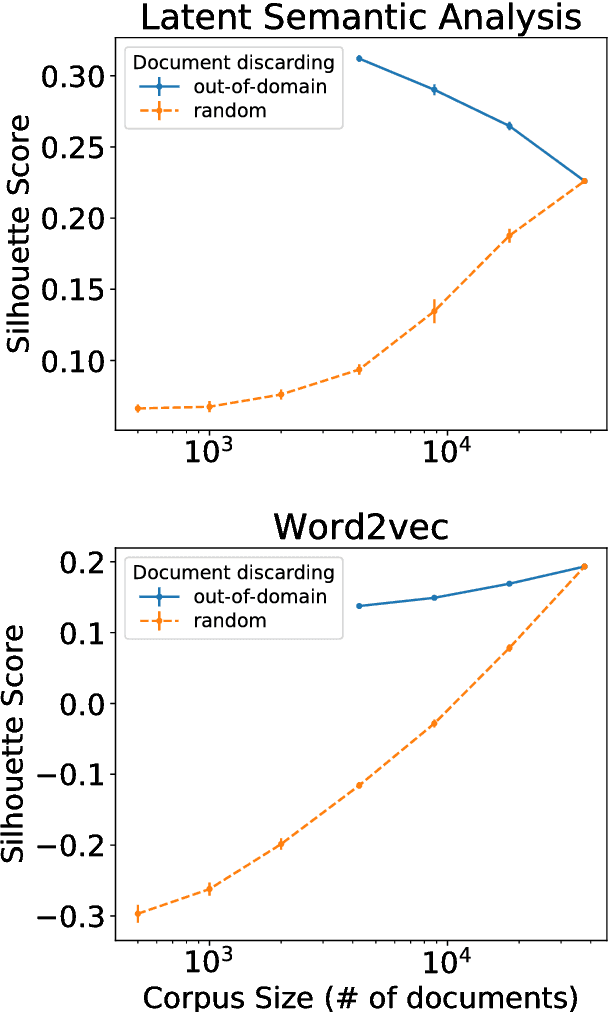
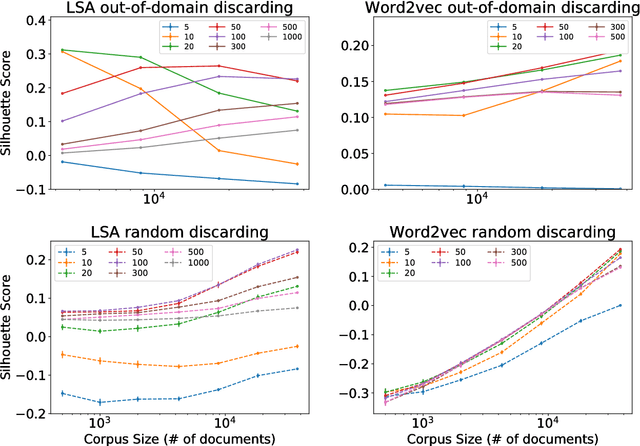
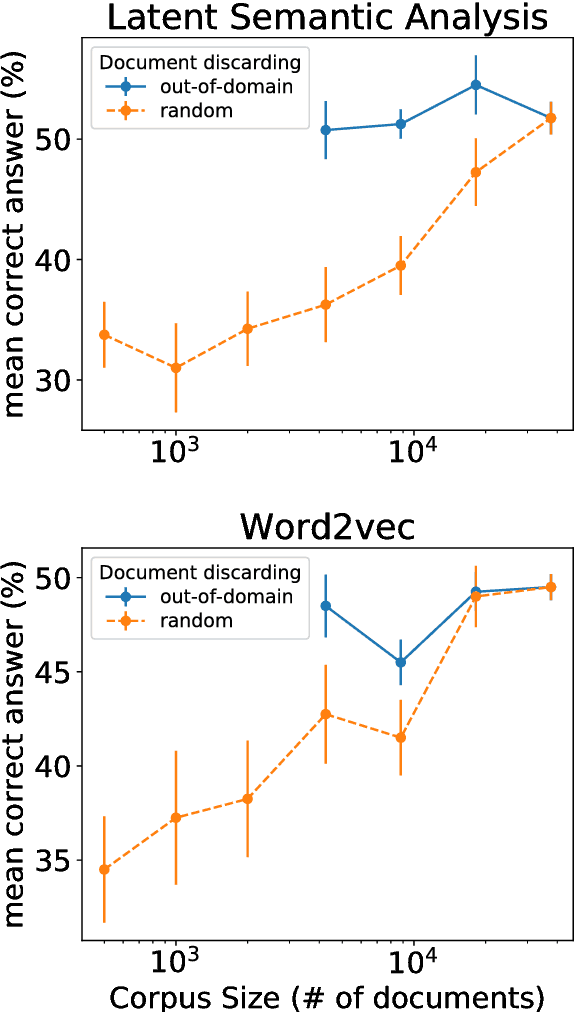
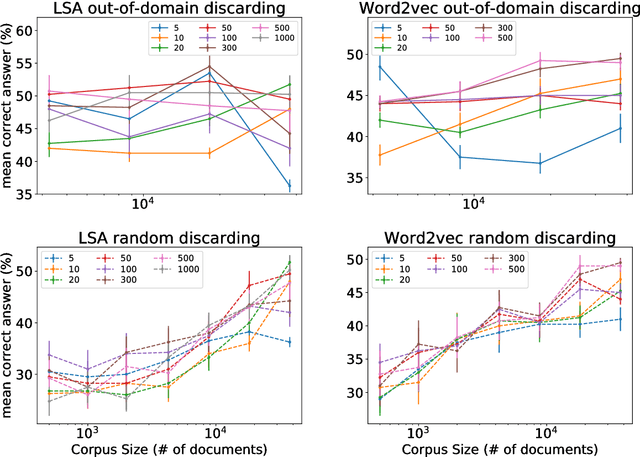
Latent Semantic Analysis (LSA) and Word2vec are some of the most widely used word embeddings. Despite the popularity of these techniques, the precise mechanisms by which they acquire new semantic relations between words remain unclear. In the present article we investigate whether LSA and Word2vec capacity to identify relevant semantic dimensions increases with size of corpus. One intuitive hypothesis is that the capacity to identify relevant dimensions should increase as the amount of data increases. However, if corpus size grow in topics which are not specific to the domain of interest, signal to noise ratio may weaken. Here we set to examine and distinguish these alternative hypothesis. To investigate the effect of corpus specificity and size in word-embeddings we study two ways for progressive elimination of documents: the elimination of random documents vs. the elimination of documents unrelated to a specific task. We show that Word2vec can take advantage of all the documents, obtaining its best performance when it is trained with the whole corpus. On the contrary, the specialization (removal of out-of-domain documents) of the training corpus, accompanied by a decrease of dimensionality, can increase LSA word-representation quality while speeding up the processing time. Furthermore, we show that the specialization without the decrease in LSA dimensionality can produce a strong performance reduction in specific tasks. From a cognitive-modeling point of view, we point out that LSA's word-knowledge acquisitions may not be efficiently exploiting higher-order co-occurrences and global relations, whereas Word2vec does.
The ontogeny of discourse structure mimics the development of literature
Dec 27, 2016Discourse varies with age, education, psychiatric state and historical epoch, but the ontogenetic and cultural dynamics of discourse structure remain to be quantitatively characterized. To this end we investigated word graphs obtained from verbal reports of 200 subjects ages 2-58, and 676 literary texts spanning ~5,000 years. In healthy subjects, lexical diversity, graph size, and long-range recurrence departed from initial near-random levels through a monotonic asymptotic increase across ages, while short-range recurrence showed a corresponding decrease. These changes were explained by education and suggest a hierarchical development of discourse structure: short-range recurrence and lexical diversity stabilize after elementary school, but graph size and long-range recurrence only stabilize after high school. This gradual maturation was blurred in psychotic subjects, who maintained in adulthood a near-random structure. In literature, monotonic asymptotic changes over time were remarkable: While lexical diversity, long-range recurrence and graph size increased away from near-randomness, short-range recurrence declined, from above to below random levels. Bronze Age texts are structurally similar to childish or psychotic discourses, but subsequent texts converge abruptly to the healthy adult pattern around the onset of the Axial Age (800-200 BC), a period of pivotal cultural change. Thus, individually as well as historically, discourse maturation increases the range of word recurrence away from randomness.
Emotional Intensity analysis in Bipolar subjects
Jun 07, 2016
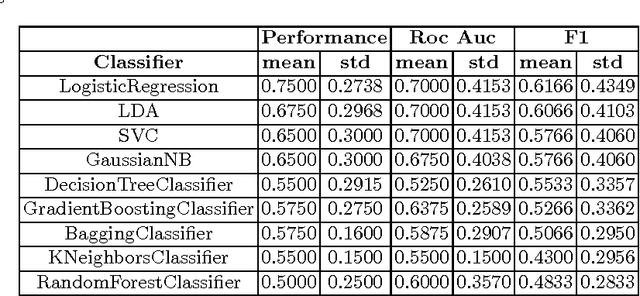
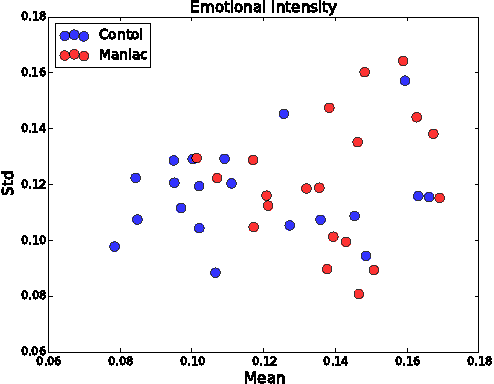
The massive availability of digital repositories of human thought opens radical novel way of studying the human mind. Natural language processing tools and computational models have evolved such that many mental conditions are predicted by analysing speech. Transcription of interviews and discourses are analyzed using syntactic, grammatical or sentiment analysis to infer the mental state. Here we set to investigate if classification of Bipolar and control subjects is possible. We develop the Emotion Intensity Index based on the Dictionary of Affect, and find that subjects categories are distinguishable. Using classical classification techniques we get more than 75\% of labeling performance. These results sumed to previous studies show that current automated speech analysis is capable of identifying altered mental states towards a quantitative psychiatry.