 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning is Compiling: Experience Shapes Concept Learning by Combining Primitives in a Language of Thought
May 17, 2018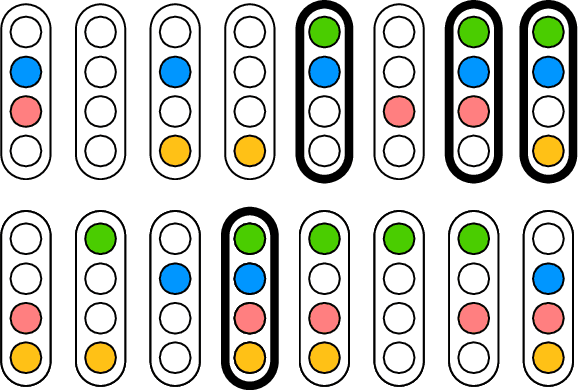
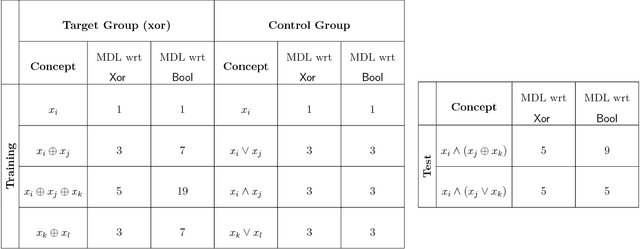
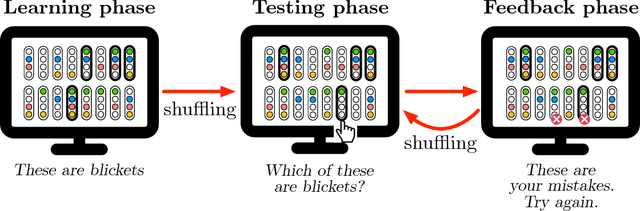
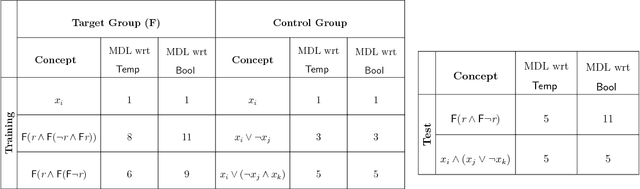
Recent approaches to human concept learning have successfully combined the power of symbolic, infinitely productive, rule systems and statistical learning. The aim of most of these studies is to reveal the underlying language structuring these representations and providing a general substrate for thought. Here, we ask about the plasticity of symbolic descriptive languages. We perform two concept learning experiments, that consistently demonstrate that humans can change very rapidly the repertoire of symbols they use to identify concepts, by compiling expressions which are frequently used into new symbols of the language. The pattern of concept learning times is accurately described by a Bayesian agent that rationally updates the probability of compiling a new expression according to how useful it has been to compress concepts so far. By portraying the Language of Thought as a flexible system of rules, we also highlight the intrinsic difficulties to pin it down empirically.
Corpus specificity in LSA and Word2vec: the role of out-of-domain documents
Dec 28, 2017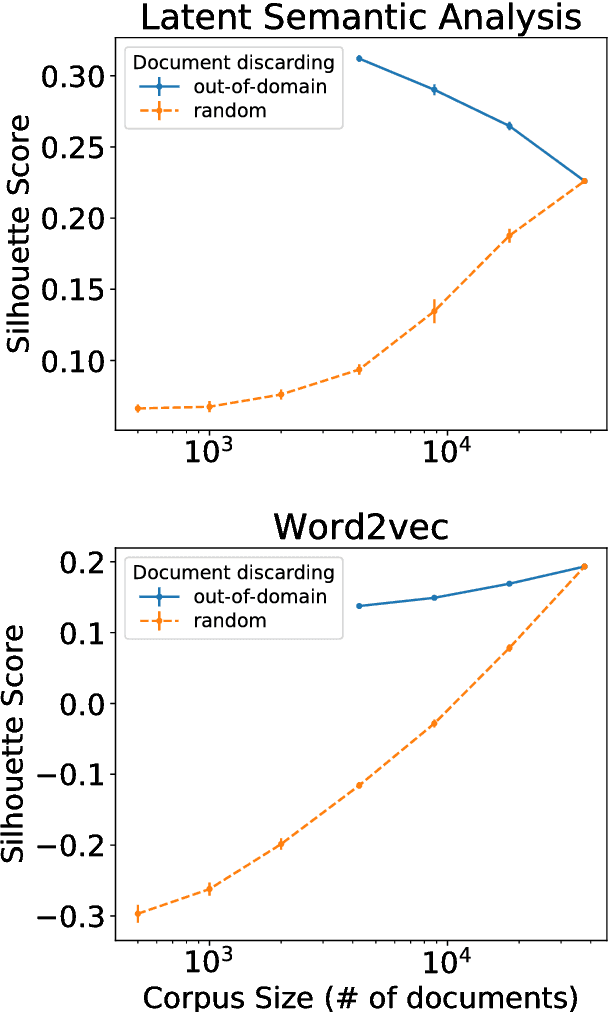
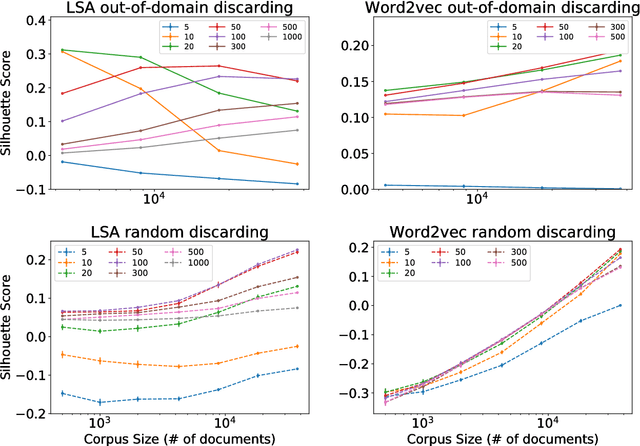
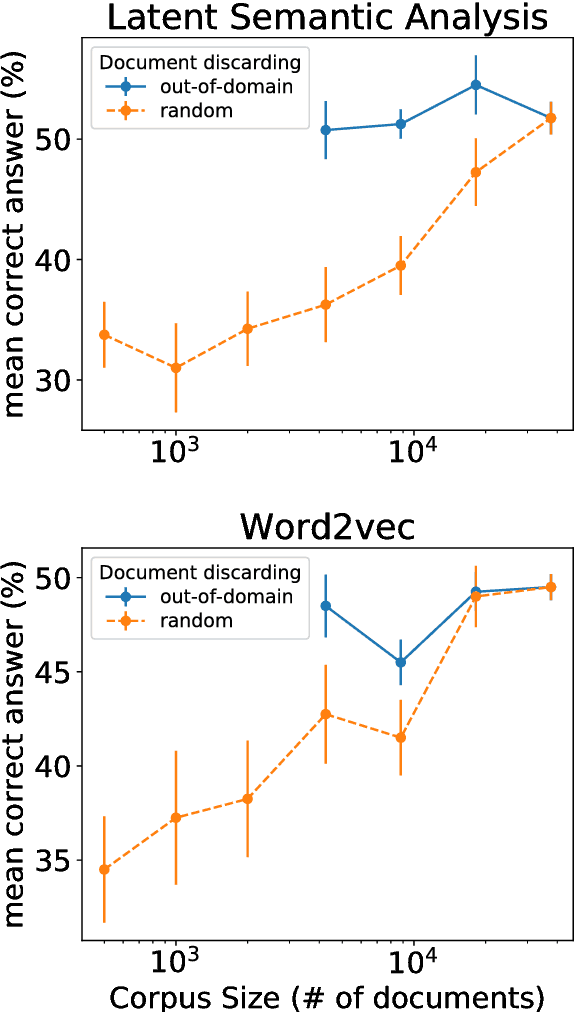
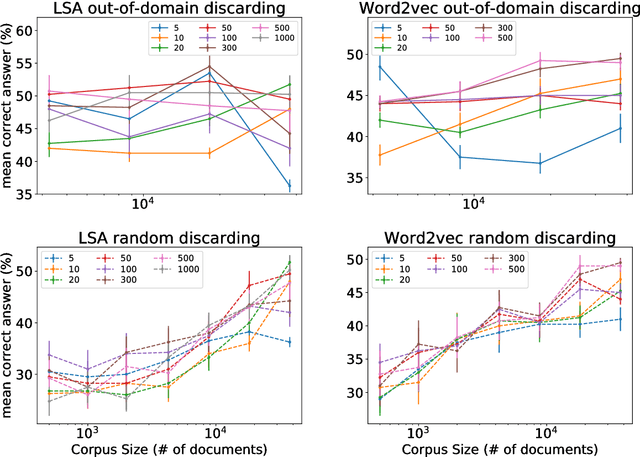
Latent Semantic Analysis (LSA) and Word2vec are some of the most widely used word embeddings. Despite the popularity of these techniques, the precise mechanisms by which they acquire new semantic relations between words remain unclear. In the present article we investigate whether LSA and Word2vec capacity to identify relevant semantic dimensions increases with size of corpus. One intuitive hypothesis is that the capacity to identify relevant dimensions should increase as the amount of data increases. However, if corpus size grow in topics which are not specific to the domain of interest, signal to noise ratio may weaken. Here we set to examine and distinguish these alternative hypothesis. To investigate the effect of corpus specificity and size in word-embeddings we study two ways for progressive elimination of documents: the elimination of random documents vs. the elimination of documents unrelated to a specific task. We show that Word2vec can take advantage of all the documents, obtaining its best performance when it is trained with the whole corpus. On the contrary, the specialization (removal of out-of-domain documents) of the training corpus, accompanied by a decrease of dimensionality, can increase LSA word-representation quality while speeding up the processing time. Furthermore, we show that the specialization without the decrease in LSA dimensionality can produce a strong performance reduction in specific tasks. From a cognitive-modeling point of view, we point out that LSA's word-knowledge acquisitions may not be efficiently exploiting higher-order co-occurrences and global relations, whereas Word2vec does.
Comparative study of LSA vs Word2vec embeddings in small corpora: a case study in dreams database
Apr 11, 2017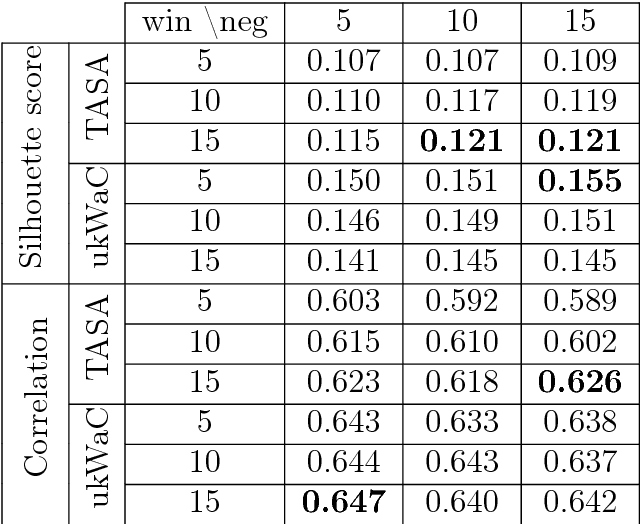
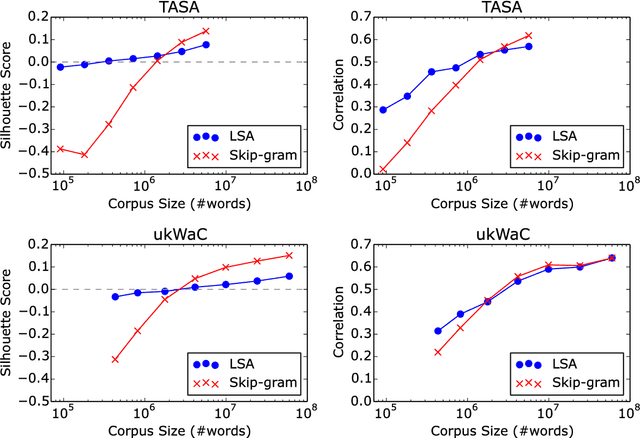
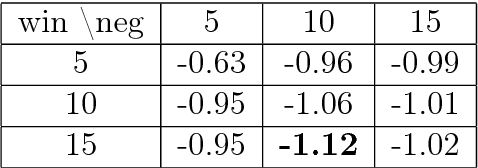
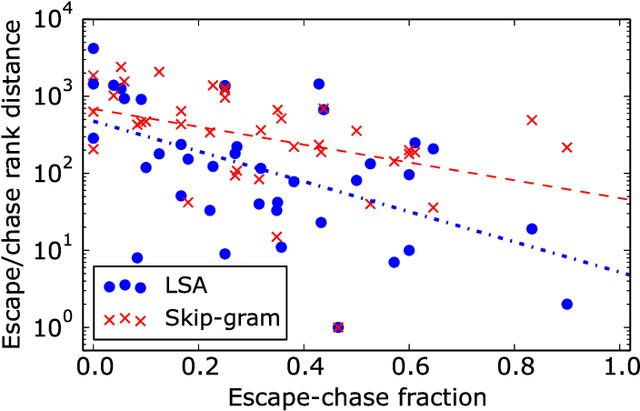
Word embeddings have been extensively studied in large text datasets. However, only a few studies analyze semantic representations of small corpora, particularly relevant in single-person text production studies. In the present paper, we compare Skip-gram and LSA capabilities in this scenario, and we test both techniques to extract relevant semantic patterns in single-series dreams reports. LSA showed better performance than Skip-gram in small size training corpus in two semantic tests. As a study case, we show that LSA can capture relevant words associations in dream reports series, even in cases of small number of dreams or low-frequency words. We propose that LSA can be used to explore words associations in dreams reports, which could bring new insight into this classic research area of psychology
The ontogeny of discourse structure mimics the development of literature
Dec 27, 2016Discourse varies with age, education, psychiatric state and historical epoch, but the ontogenetic and cultural dynamics of discourse structure remain to be quantitatively characterized. To this end we investigated word graphs obtained from verbal reports of 200 subjects ages 2-58, and 676 literary texts spanning ~5,000 years. In healthy subjects, lexical diversity, graph size, and long-range recurrence departed from initial near-random levels through a monotonic asymptotic increase across ages, while short-range recurrence showed a corresponding decrease. These changes were explained by education and suggest a hierarchical development of discourse structure: short-range recurrence and lexical diversity stabilize after elementary school, but graph size and long-range recurrence only stabilize after high school. This gradual maturation was blurred in psychotic subjects, who maintained in adulthood a near-random structure. In literature, monotonic asymptotic changes over time were remarkable: While lexical diversity, long-range recurrence and graph size increased away from near-randomness, short-range recurrence declined, from above to below random levels. Bronze Age texts are structurally similar to childish or psychotic discourses, but subsequent texts converge abruptly to the healthy adult pattern around the onset of the Axial Age (800-200 BC), a period of pivotal cultural change. Thus, individually as well as historically, discourse maturation increases the range of word recurrence away from randomness.
Emotional Intensity analysis in Bipolar subjects
Jun 07, 2016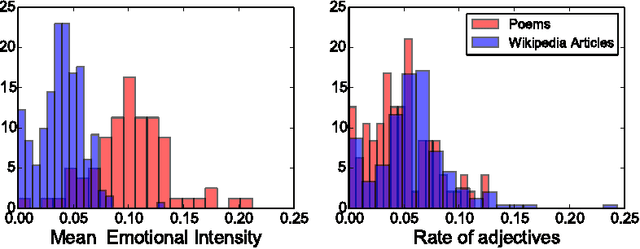
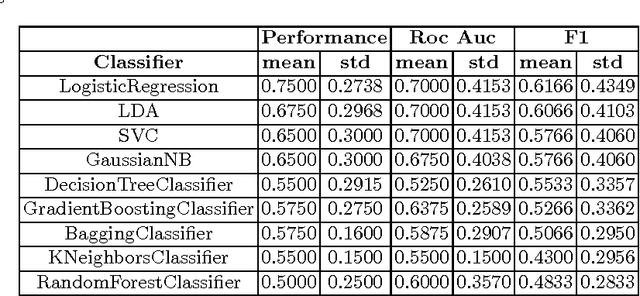
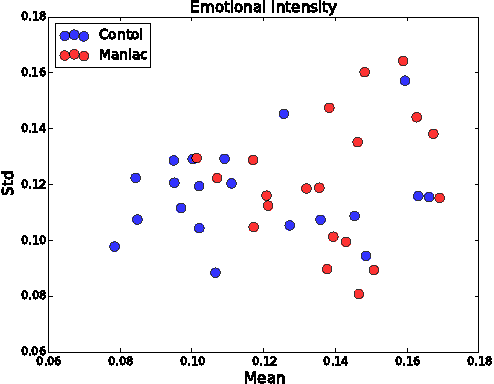
The massive availability of digital repositories of human thought opens radical novel way of studying the human mind. Natural language processing tools and computational models have evolved such that many mental conditions are predicted by analysing speech. Transcription of interviews and discourses are analyzed using syntactic, grammatical or sentiment analysis to infer the mental state. Here we set to investigate if classification of Bipolar and control subjects is possible. We develop the Emotion Intensity Index based on the Dictionary of Affect, and find that subjects categories are distinguishable. Using classical classification techniques we get more than 75\% of labeling performance. These results sumed to previous studies show that current automated speech analysis is capable of identifying altered mental states towards a quantitative psychiatry.
LT^2C^2: A language of thought with Turing-computable Kolmogorov complexity
Mar 04, 2013
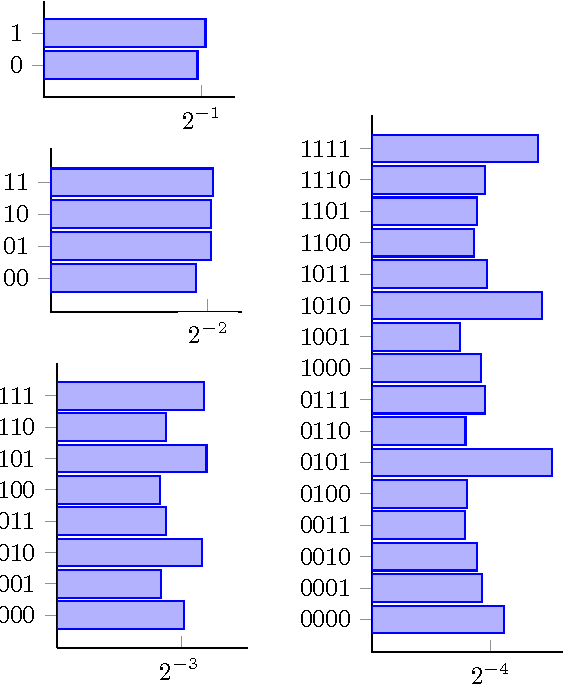
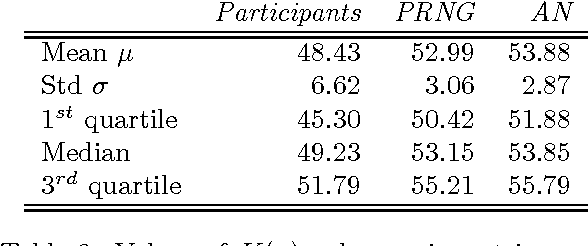
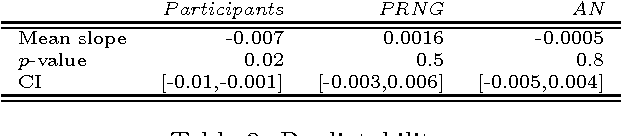
In this paper, we present a theoretical effort to connect the theory of program size to psychology by implementing a concrete language of thought with Turing-computable Kolmogorov complexity (LT^2C^2) satisfying the following requirements: 1) to be simple enough so that the complexity of any given finite binary sequence can be computed, 2) to be based on tangible operations of human reasoning (printing, repeating,...), 3) to be sufficiently powerful to generate all possible sequences but not too powerful as to identify regularities which would be invisible to humans. We first formalize LT^2C^2, giving its syntax and semantics and defining an adequate notion of program size. Our setting leads to a Kolmogorov complexity function relative to LT^2C^2 which is computable in polynomial time, and it also induces a prediction algorithm in the spirit of Solomonoff's inductive inference theory. We then prove the efficacy of this language by investigating regularities in strings produced by participants attempting to generate random strings. Participants had a profound understanding of randomness and hence avoided typical misconceptions such as exaggerating the number of alternations. We reasoned that remaining regularities would express the algorithmic nature of human thoughts, revealed in the form of specific patterns. Kolmogorov complexity relative to LT^2C^2 passed three expected tests examined here: 1) human sequences were less complex than control PRNG sequences, 2) human sequences were not stationary, showing decreasing values of complexity resulting from fatigue, 3) each individual showed traces of algorithmic stability since fitting of partial sequences was more effective to predict subsequent sequences than average fits. This work extends on previous efforts to combine notions of Kolmogorov complexity theory and algorithmic information theory to psychology, by explicitly ...
* 14 pages, 4 figures