 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMispronunciation detection using self-supervised speech representations
Jul 30, 2023In recent years, self-supervised learning (SSL) models have produced promising results in a variety of speech-processing tasks, especially in contexts of data scarcity. In this paper, we study the use of SSL models for the task of mispronunciation detection for second language learners. We compare two downstream approaches: 1) training the model for phone recognition (PR) using native English data, and 2) training a model directly for the target task using non-native English data. We compare the performance of these two approaches for various SSL representations as well as a representation extracted from a traditional DNN-based speech recognition model. We evaluate the models on L2Arctic and EpaDB, two datasets of non-native speech annotated with pronunciation labels at the phone level. Overall, we find that using a downstream model trained for the target task gives the best performance and that most upstream models perform similarly for the task.
A transfer learning based approach for pronunciation scoring
Nov 01, 2021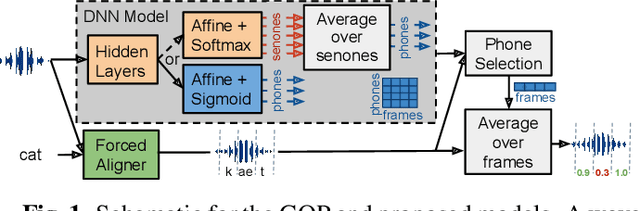
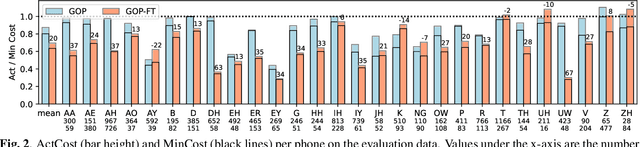
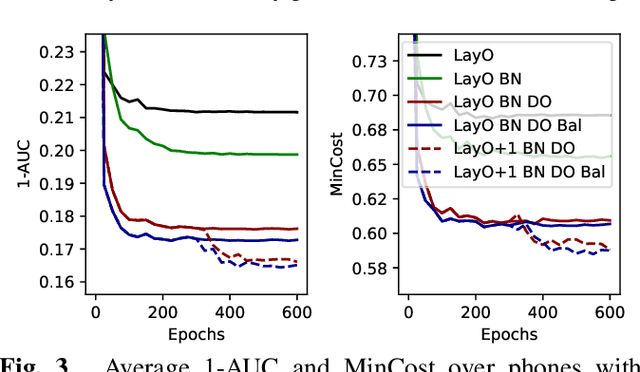
Phone-level pronunciation scoring is a challenging task, with performance far from that of human annotators. Standard systems generate a score for each phone in a phrase using models trained for automatic speech recognition (ASR) with native data only. Better performance has been shown when using systems that are trained specifically for the task using non-native data. Yet, such systems face the challenge that datasets labelled for this task are scarce and usually small. In this paper, we present a transfer learning-based approach that leverages a model trained for ASR, adapting it for the task of pronunciation scoring. We analyze the effect of several design choices and compare the performance with a state-of-the-art goodness of pronunciation (GOP) system. Our final system is 20% better than the GOP system on EpaDB, a database for pronunciation scoring research, for a cost function that prioritizes low rates of unnecessary corrections.