 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic and linguistic representations for speech continuous emotion recognition in call center conversations
Oct 06, 2023The goal of our research is to automatically retrieve the satisfaction and the frustration in real-life call-center conversations. This study focuses an industrial application in which the customer satisfaction is continuously tracked down to improve customer services. To compensate the lack of large annotated emotional databases, we explore the use of pre-trained speech representations as a form of transfer learning towards AlloSat corpus. Moreover, several studies have pointed out that emotion can be detected not only in speech but also in facial trait, in biological response or in textual information. In the context of telephone conversations, we can break down the audio information into acoustic and linguistic by using the speech signal and its transcription. Our experiments confirms the large gain in performance obtained with the use of pre-trained features. Surprisingly, we found that the linguistic content is clearly the major contributor for the prediction of satisfaction and best generalizes to unseen data. Our experiments conclude to the definitive advantage of using CamemBERT representations, however the benefit of the fusion of acoustic and linguistic modalities is not as obvious. With models learnt on individual annotations, we found that fusion approaches are more robust to the subjectivity of the annotation task. This study also tackles the problem of performances variability and intends to estimate this variability from different views: weights initialization, confidence intervals and annotation subjectivity. A deep analysis on the linguistic content investigates interpretable factors able to explain the high contribution of the linguistic modality for this task.
On the use of Self-supervised Pre-trained Acoustic and Linguistic Features for Continuous Speech Emotion Recognition
Nov 18, 2020
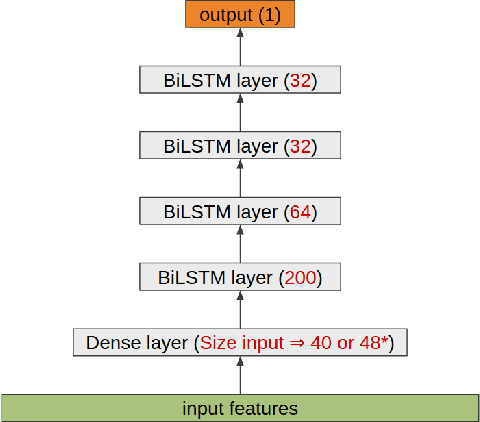
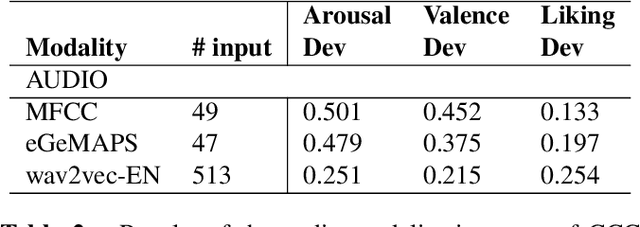

Pre-training for feature extraction is an increasingly studied approach to get better continuous representations of audio and text content. In the present work, we use wav2vec and camemBERT as self-supervised learned models to represent our data in order to perform continuous emotion recognition from speech (SER) on AlloSat, a large French emotional database describing the satisfaction dimension, and on the state of the art corpus SEWA focusing on valence, arousal and liking dimensions. To the authors' knowledge, this paper presents the first study showing that the joint use of wav2vec and BERT-like pre-trained features is very relevant to deal with continuous SER task, usually characterized by a small amount of labeled training data. Evaluated by the well-known concordance correlation coefficient (CCC), our experiments show that we can reach a CCC value of 0.825 instead of 0.592 when using MFCC in conjunction with word2vec word embedding on the AlloSat dataset.